Java高并发之线程池详解
线程池优势
在业务场景中,如果一个对象创建销毁开销比较大, 那么此时建议池化对象进行管理,例如线程,jdbc连接等等,在高并发场景中,如果可以复用之前销毁的对象,那么系统效率将大大提升。另外一个好处是可以设定池化对象的上限,例如预防创建线程数量过多导致系统崩溃的场景。
jdk中的线程池
下文主要从以下几个角度讲解:
- 创建线程池
- 提交任务
- 潜在宕机风险
- 线程池大小配置
- 自定义阻塞队列BlockingQueue
- 回调接口
- 自定义拒绝策略
- 自定义ThreadFactory
- 关闭线程池
创建线程池
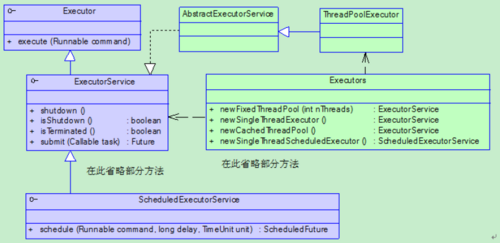
我们可以通过自定义ThreadPoolExecutor或者jdk内置的 Executors 来创建一系列的线程池
- newFixedThreadPool: 创建固定线程数量的线程池
- newSingleThreadExecutor: 创建单一线程的池
- newCachedThreadPool: 创建线程数量自动扩容, 自动销毁的线程池
- newScheduledThreadPool: 创建支持计划任务的线程池
上述几种都是通过new ThreadPoolExecutor()来实现的, 构造函数源码如下:
/**
* @param corePoolSize 池内核心线程数量, 超出数量的线程会进入阻塞队列
* @param maximumPoolSize 最大可创建线程数量
* @param keepAliveTime 线程存活时间
* @param unit 存活时间的单位
* @param workQueue 线程溢出后的阻塞队列
*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, Executors.defaultThreadFactory(), defaultHandler);
}
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>());
}
public static ExecutorService newSingleThreadExecutor() {
return new Executors.FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()));
}
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>());
}
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, TimeUnit.NANOSECONDS, new ScheduledThreadPoolExecutor.DelayedWorkQueue());
}
提交任务
直接调用executorService.execute(runnable)或者submit(runnable)即可,
execute和submit的区别在于submit会返回Future来获取任何执行的结果.
我们看下newScheduledThreadPool的使用示例.
public class SchedulePoolDemo {
public static void main(String[] args){
ScheduledExecutorService service = Executors.newScheduledThreadPool(10);
// 如果前面的任务没有完成, 调度也不会启动
service.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(2000);
// 每两秒打印一次.
System.out.println(System.currentTimeMillis()/1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, 0, 2, TimeUnit.SECONDS);
}
}
潜在宕机风险
使用Executors来创建要注意潜在宕机风险.其返回的线程池对象的弊端如下:
- FixedThreadPool和SingleThreadPoolPool : 允许的 请求队列 长度为 Integer.MAX_VALUE,可能会堆积大量的请求,从而导致 OOM.
- CachedThreadPool和ScheduledThreadPool : 允许的 创建线程 数量为 Integer.MAX_VALUE,可能会创建大量的线程,从而导致 OOM.
综上所述, 在可能有大量请求的线程池场景中, 更推荐自定义ThreadPoolExecutor来创建线程池, 具体构造函数配置见下文.
线程池大小配置
一般根据任务类型进行区分, 假设CPU为N核
- CPU密集型任务需要减少线程数量, 降低线程之间切换造成的开销, 可配置线程池大小为N + 1.
- IO密集型任务则可以加大线程数量, 可配置线程池大小为 N * 2.
- 混合型任务则可以拆分为CPU密集型与IO密集型, 独立配置.
自定义阻塞队列BlockingQueue
主要存放等待执行的线程, ThreadPoolExecutor中支持自定义该队列来实现不同的排队队列.
- ArrayBlockingQueue:先进先出队列,创建时指定大小, 有界;
- LinkedBlockingQueue:使用链表实现的先进先出队列,默认大小为Integer.MAX_VALUE;
- SynchronousQueue: 不保存提交的任务, 数据也不会缓存到队列中, 用于生产者和消费者互等对方, 一起离开.
- PriorityBlockingQueue: 支持优先级的队列
回调接口
线程池提供了一些回调方法, 具体使用如下所示.
ExecutorService service = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingDeque<Runnable>()) {
@Override
protected void beforeExecute(Thread t, Runnable r) {
System.out.println("准备执行任务: " + r.toString());
}
@Override
protected void afterExecute(Runnable r, Throwable t) {
System.out.println("结束任务: " + r.toString());
}
@Override
protected void terminated() {
System.out.println("线程池退出");
}
};
可以在回调接口中, 对线程池的状态进行监控, 例如任务执行的最长时间, 平均时间, 最短时间等等, 还有一些其他的属性如下:
- taskCount:线程池需要执行的任务数量.
- completedTaskCount:线程池在运行过程中已完成的任务数量.小于或等于taskCount.
- largestPoolSize:线程池曾经创建过的最大线程数量.通过这个数据可以知道线程池是否满过.如等于线程池的最大大小,则表示线程池曾经满了.
- getPoolSize:线程池的线程数量.如果线程池不销毁的话,池里的线程不会自动销毁,所以这个大小只增不减.
- getActiveCount:获取活动的线程数.
自定义拒绝策略
线程池满负荷运转后, 因为时间空间的问题, 可能需要拒绝掉部分任务的执行.
jdk提供了RejectedExecutionHandler接口, 并内置了几种线程拒绝策略
- AbortPolicy: 直接拒绝策略, 抛出异常.
- CallerRunsPolicy: 调用者自己执行任务策略.
- DiscardOldestPolicy: 舍弃最老的未执行任务策略.
使用方式也很简单, 直接传参给ThreadPool
ExecutorService service = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.MILLISECONDS,
new SynchronousQueue<Runnable>(),
Executors.defaultThreadFactory(),
new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
System.out.println("reject task: " + r.toString());
}
});
自定义ThreadFactory
线程工厂用于创建池里的线程. 例如在工厂中都给线程setDaemon(true), 这样程序退出的时候, 线程自动退出.
或者统一指定线程优先级, 设置名称等等.
class NamedThreadFactory implements ThreadFactory {
private static final AtomicInteger threadIndex = new AtomicInteger(0);
private final String baseName;
private final boolean daemon;
public NamedThreadFactory(String baseName) {
this(baseName, true);
}
public NamedThreadFactory(String baseName, boolean daemon) {
this.baseName = baseName;
this.daemon = daemon;
}
public Thread newThread(Runnable runnable) {
Thread thread = new Thread(runnable, this.baseName + "-" + threadIndex.getAndIncrement());
thread.setDaemon(this.daemon);
return thread;
}
}
关闭线程池
跟直接new Thread不一样, 局部变量的线程池, 需要手动关闭, 不然会导致线程泄漏问题.
默认提供两种方式关闭线程池.
- shutdown: 等所有任务, 包括阻塞队列中的执行完, 才会终止, 但是不会接受新任务.
- shutdownNow: 立即终止线程池, 打断正在执行的任务, 清空队列.
本文永久更新链接地址: https://www.linuxidc.com/Linux/2018-06/152702.htm
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

