三、 FastDFS功能原理
1.1. 文件上传
FastDFS向使用者提供基本文件访问接口,比如upload、download、append、delete等,以客户端库的方式提供给用户使用。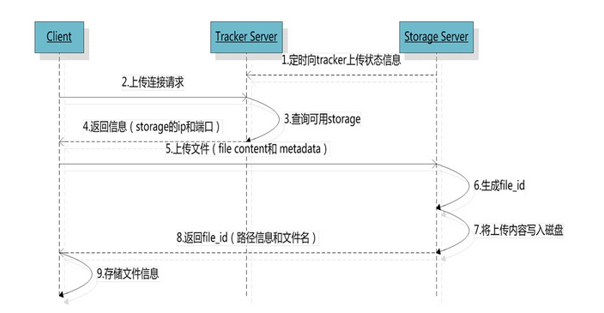 选择tracker server
选择tracker server
当集群中不止一个tracker server时,由于tracker之间是完全对等的关系,客户端在upload文件时可以任意选择一个trakcer。选择存储的group
当tracker接收到upload file的请求时,会为该文件分配一个可以存储该文件的group,支持如下选择group的规则:选择storage server
- Round robin,所有的group间轮询
- Specified group,指定某一个确定的group
- Load balance,剩余存储空间多多group优先
当选定group后,tracker会在group内选择一个storage server给客户端,支持如下选择storage的规则:选择storage path
- Round robin,在group内的所有storage间轮询
- First server ordered by ip,按ip排序
- First server ordered by priority,按优先级排序(优先级在storage上配置)
当分配好storage server后,客户端将向storage发送写文件请求,storage将会为文件分配一个数据存储目录,支持如下规则:生成Fileid
- Round robin,多个存储目录间轮询
- 剩余存储空间最多的优先
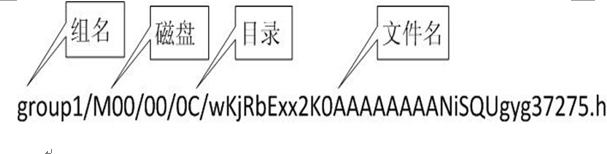
选定存储目录之后,storage会为文件生一个Fileid,由storage server ip、文件创建时间、文件大小、文件crc32和一个随机数拼接而成,然后将这个二进制串进行base64编码,转换为可打印的字符串。选择两级目录
当选定存储目录之后,storage会为文件分配一个fileid,每个存储目录下有两级256*256的子目录,storage会按文件fileid进行两次hash(猜测),路由到其中一个子目录,然后将文件以fileid为文件名存储到该子目录下。生成文件名
当文件存储到某个子目录后,即认为该文件存储成功,接下来会为该文件生成一个文件名,文件名由group、存储目录、两级子目录、fileid、文件后缀名(由客户端指定,主要用于区分文件类型)拼接而成。
 文件上传类型有3种:
文件上传类型有3种:
1)upload:上传普通文件,包括主文件 2)upload_appender:上传appender文件,后续可以对其进行append操作【又用作断点续传】 3)upload_slave:上传从文件。
1.2. 文件下载
客户端upload file成功后,会拿到一个storage生成的文件名,接下来客户端根据这个文件名即可访问到该文件。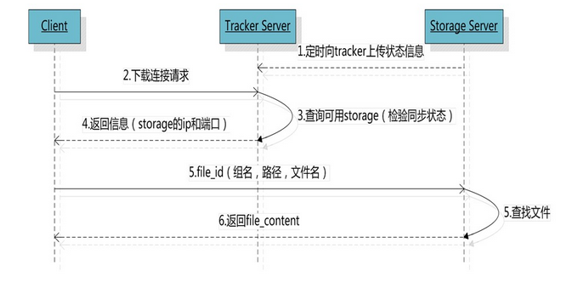 跟upload file一样,在download file时客户端可以选择任意tracker server。
tracker发送download请求给某个tracker,必须带上文件名信息,tracke从文件名中解析出文件的group、大小、创建时间等信息,然后为该请求选择一个storage用来服务读请求。由于group内的文件同步时在后台异步进行的,所以有可能出现在读到时候,文件还没有同步到某些storage server上,为了尽量避免访问到这样的storage,tracker按照如下规则选择group内可读的storage。
跟upload file一样,在download file时客户端可以选择任意tracker server。
tracker发送download请求给某个tracker,必须带上文件名信息,tracke从文件名中解析出文件的group、大小、创建时间等信息,然后为该请求选择一个storage用来服务读请求。由于group内的文件同步时在后台异步进行的,所以有可能出现在读到时候,文件还没有同步到某些storage server上,为了尽量避免访问到这样的storage,tracker按照如下规则选择group内可读的storage。
1该文件上传到的源头storage-源头storage只要存活着,肯定包含这个文件,源头的地址被编码在文件名中。 2文件创建时间戳==storage被同步到的时间戳且(当前时间-文件创建时间戳)>文件同步最大时间(如5分钟)-文件创建后,认为经过最大同步时间后,肯定已经同步到其他storage了。 3文件创建时间戳< storage被同步到的时间戳。 -同步时间戳之前的文件确定已经同步了 4(当前时间-文件创建时间戳)>同步延迟阀值(如一天)。 -经过同步延迟阈值时间,认为文件肯定已经同步了。Storage上的Nginx Module首先会去看本机有没有被请求的文件,如果没有的话,会从FileId中解开源Storage的IP地址,然后去访问,如果此时源Storage当机了,那么本次下载请求就此失败(Nginx Module从始至终没有拿着被请求文件的Group Name去问Tracker现在哪台活着的Storage能响应请求) 由于以上的流程无法保证HA,所以我们还是决定在前端负载均衡设备上手动根据URL中的GroupName将请求转到相应的upstream组(Storage Server组)中,唯一的不好是,增加Group时需要调整负载均衡设备的设置
1.3. 文件删除
删除处理流程与文件下载类是:- Client询问Tracker server可以下载指定文件的Storage server,参数为文件ID(包含组名和文件名);
- Tracker server返回一台可用的Storage server;
- Client直接和该Storage server建立连接,完成文件删除。
1.4. 文件同步
写文件时,客户端将文件写至group内一个storage server即认为写文件成功,storage server写完文件后,会由后台线程将文件同步至同group内其他的storage server。 每个storage写文件后,同时会写一份binlog,binlog里不包含文件数据,只包含文件名等元信息,这份binlog用于后台同步,storage会记录向group内其他storage同步的进度,以便重启后能接上次的进度继续同步;进度以时间戳的方式进行记录,所以最好能保证集群内所有server的时钟保持同步。 storage的同步进度会作为元数据的一部分汇报到tracker上,tracke在选择读storage的时候会以同步进度作为参考。 比如一个group内有A、B、C三个storage server,A向C同步到进度为T1 (T1以前写的文件都已经同步到B上了),B向C同步到时间戳为T2(T2 > T1),tracker接收到这些同步进度信息时,就会进行整理,将最小的那个做为C的同步时间戳,本例中T1即为C的同步时间戳为T1(即所有T1以前写的数据都已经同步到C上了);同理,根据上述规则,tracker会为A、B生成一个同步时间戳。1.5. 断点续传
提供appender file的支持,通过upload_appender_file接口存储,appender file允许在创建后,对该文件进行append操作。实际上,appender file与普通文件的存储方式是相同的,不同的是,appender file不能被合并存储到trunk file。.续传涉及到的文件大小MD5不会改变。续传流程与文件上传类是,先定位到源storage,完成完整或部分上传,再通过binlog进行同group内server文件同步。1.6. 文件属性
FastDFS提供了设置/获取文件扩展属性的接口(setmeta/getmeta),扩展属性以key-value对的方式存储在storage上的同名文件(拥有特殊的前缀或后缀),比如/group/M00/00/01/some_file为原始文件,则该文件的扩展属性存储在/group/M00/00/01/.some_file.meta文件(真实情况不一定是这样,但机制类似),这样根据文件名就能定位到存储扩展属性的文件。 以上两个接口作者不建议使用,额外的meta文件会进一步“放大”海量小文件存储问题,同时由于meta非常小,其存储空间利用率也不高,比如100bytes的meta文件也需要占用4K(block_size)的存储空间。1.7. HTTP访问支持
FastDFS的tracker和storage都内置了http协议的支持,客户端可以通过http协议来下载文件,tracker在接收到请求时,通过http的redirect机制将请求重定向至文件所在的storage上;除了内置的http协议外,FastDFS还提供了通过apache或nginx扩展模块下载文件的支持。
正文到此结束
- 本文标签:
- 版权声明: 本文由HARRIES原创发布,转载请遵循《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

