Java网络爬虫实操(10)
上一篇: Java网络爬虫实操(9)
各位好,马上又是618购物节了,大家的购物热情多少有点被勾起吧。相信大家最频繁的操作肯定是打开购物网站,输入关心商品的关键字,然后看看哪个店的销量高,哪个店的价格最低,等等。 本篇文章结合Java爬虫框架 NetDiscovery 使用selenium技术实现自动化获取前三个商品的信息。
1) 逻辑流程
- 程序打开JD的商品搜索页面
- 自动输入商品关键字
- 自动点击查询按钮
- 自动点击销量按钮
- 获取前三个商品的信息:店铺名称、商品名称、售价
2) 代码流程
- 使用chrome浏览器访问网页,需要使用对应平台和版本的driver程序。
WebDriverPoolConfig config = new WebDriverPoolConfig("example/chromedriver.exe", Browser.Chrome);
WebDriverPool.init(config);
- 实现一个继承SeleniumAction的类,执行逻辑都在这里。
package com.cv4j.netdiscovery.example.jd;
import com.cv4j.netdiscovery.selenium.Utils;
import com.cv4j.netdiscovery.selenium.action.SeleniumAction;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
public class JDAction extends SeleniumAction {
@Override
public SeleniumAction perform(WebDriver driver) {
try {
//BrowserAction 最大化浏览器窗口
driver.manage().window().maximize();
Thread.sleep(3000);
//输入商品关键字
String searchText = "商务笔记本";
String searchInput = "//*[@id=/"keyword/"]";
WebElement userInput = Utils.getWebElementByXpath(driver, searchInput);
userInput.sendKeys(searchText);
Thread.sleep(3000);
//触发查询事件
String searchBtn = "/html/body/div[2]/form/input[4]";
Utils.clickElement(driver, By.xpath(searchBtn));
Thread.sleep(3000);
//触发销量事件
String saleSortBtn = "//*[@id=/"J_filter/"]/div[1]/div[1]/a[2]";
Utils.clickElement(driver, By.xpath(saleSortBtn));
Thread.sleep(3000);
//获取页面的html源码并转化为对象
String pageHtml = driver.getPageSource();
Document document = Jsoup.parse(pageHtml);
Elements elements = document.select("div[id=J_goodsList] li[class=gl-item]");
if(elements != null && elements.size() >= 3) {
for (int i = 0; i < 3; i++) {
Element element = elements.get(i);
String storeName = element.select("div[class=p-shop] a").first().text();
String goodsName = element.select("div[class=p-name p-name-type-2] a em").first().text();
String goodsPrice = element.select("div[class=p-price] i").first().text();
System.out.println(storeName+" "+goodsName+" ¥"+goodsPrice);
}
}
} catch(InterruptedException e) {
e.printStackTrace();
}
return null;
}
}
- 把action装载到下载器SeleniumDownloader,并且构建一个Spider
package com.cv4j.netdiscovery.example.jd;
import com.cv4j.netdiscovery.core.Spider;
import com.cv4j.netdiscovery.selenium.Browser;
import com.cv4j.netdiscovery.selenium.downloader.SeleniumDownloader;
import com.cv4j.netdiscovery.selenium.pool.WebDriverPool;
import com.cv4j.netdiscovery.selenium.pool.WebDriverPoolConfig;
public class JDSpider {
public static void main(String[] args) {
WebDriverPoolConfig config = new WebDriverPoolConfig("example/chromedriver.exe", Browser.Chrome);
WebDriverPool.init(config);
JDAction jdAction = new JDAction();
SeleniumDownloader seleniumDownloader = new SeleniumDownloader(jdAction);
String url = "https://search.jd.com/";
Spider.create()
.name("searchJD")
.url(url)
.downloader(seleniumDownloader)
.run();
}
}
- spider的执行结果

3) 进一步说明
- 以上代码只是例子,实际工作中action逻辑会比较复杂。我们可以根据需求,把action拆分为多个,通过list装配到加载器,框架会根据add顺序排队执行action。
List<SeleniumAction> actionList = new ArrayList<>();
actionList.add(new BrowserAction());
actionList.add(new InitAction());
actionList.add(new WorkAction());
SeleniumDownloader seleniumDownloader = new SeleniumDownloader(actionList);
- 如果自动化工作需要周期性执行,可以参考之前的文章,把spider加载到SpiderEngine中,然后调用runRepeat(),实现重复执行。
SpiderEngine engine = SpiderEngine.create();
for(...) {
engine.addSpider(spider);
}
engine.runWithRepeat();
-
也许有些伙伴会问action类中的xpath怎么来的?我是使用chrome浏览器,通过开发者工具中Elements,选中元素后点右键,然后找到xpath的。
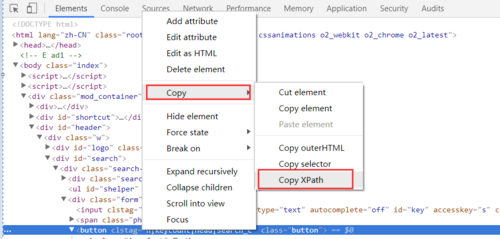
-
如何从html字符串转换为对象,实现目标数据的精确获取,有很多方法。比如Jsoup。
好了,本篇只是抛砖引玉,相信有需要的伙伴肯定有深入的需求和想法,欢迎大家关注Java爬虫框架 NetDiscovery https://github.com/fengzhizi715/NetDiscovery
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

