怎样衡量两个字符串的相似度(编辑距离动态规划求解)
目前计算句子相似性有很多不同的方案,比如基于语义词典的方法、基于相同词汇的方法、基于统计的方法和基于编辑距离的方法。这篇文章先介绍编辑距离的基础。
编辑距离
编辑距离其实就是指把一个字符串转换为另外一个字符串所需要的最小编辑操作的代价数。包括插入字符、替换字符和删除字符。编辑距离越小,相似度越大。
比如我们要将 what 转换成 where ,可能是将 a -> e,接着 t -> r ,变为 wher ,最后添加 e,完成。因为每一步都可以插入、删除或替换,那么如何才能在最终得到一个最小的代价,这是就会用到动态规划来求解。
假设我们有长度分别为 i、j 的两个字符串,设编辑距离为 edit(i,j) 。接着我们看下,如果它们最后的字符相等,则编辑距离其实等于 edit(i-1,j-1) 。而如果最后的字符不相等,那么我们可以通过插入或替换来使其相等,但是不同的操作对应的代价不相同,如果插入则为 edit(i,j-1)+1 或 eidit(i-1,j)+1 ,替换则为 edit(i-1,j-1)+1 。
求解
用以下动态方程来表示:
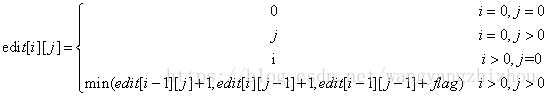
其中
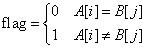
举个前面的例子,what 到 where,假设两个字符分别为空时对应的代价数如下,
| 编辑距离 | 空 | w | h | a | t |
| 空 | 0 | 1 | 2 | 3 | 4 |
| w | 1 | ||||
| h | 2 | ||||
| e | 3 | ||||
| r | 4 | ||||
| e | 5 |
动态规划后为:
| 编辑距离 | 空 | w | h | a | t |
| 空 | 0 | 1 | 2 | 3 | 4 |
| w | 1 | 0 | 1 | 2 | 3 |
| h | 2 | 1 | 0 | 1 | 2 |
| e | 3 | 2 | 1 | 1 | 2 |
| r | 4 | 3 | 2 | 2 | 2 |
| e | 5 | 4 | 3 | 3 | 3 |
在整个动态规划过程中一直都是选择最小的代价数,所以最终的3即是这两个字符串的最小代价数,即编辑距离。
github
https://github.com/sea-boat/TextAnalyzer/blob/master/src/main/java/com/seaboat/text/analyzer/distance/CharEditDistance.java
实现
public class EditDistance {
public static int getEditDistance(String s, String t) {
int d[][];
int n;
int m;
int i;
int j;
char s_i;
char t_j;
int cost;
n = s.length();
m = t.length();
if (n == 0) {
return m;
}
if (m == 0) {
return n;
}
d = new int[n + 1][m + 1];
for (i = 0; i <= n; i++) {
d[i][0] = i;
}
for (j = 0; j <= m; j++) {
d[0][j] = j;
}
for (i = 1; i <= n; i++) {
s_i = s.charAt(i - 1);
for (j = 1; j <= m; j++) {
t_j = t.charAt(j - 1);
cost = (s_i == t_j) ? 0 : 1;
d[i][j] = Math.min(d[i - 1][j] + 1, d[i][j - 1] + 1);
d[i][j] = Math.min(d[i][j], d[i - 1][j - 1] + cost);
}
}
return d[n][m];
}
public static void main(String[] args) {
EditDistance ed = new EditDistance();
System.out.println(ed.getEditDistance("what", "where"));
}
}
-------------推荐阅读------------
我的2017文章汇总——机器学习篇
我的2017文章汇总——Java及中间件
我的2017文章汇总——深度学习篇
我的2017文章汇总——JDK源码篇
我的2017文章汇总——自然语言处理篇
我的2017文章汇总——Java并发篇
跟我交流,向我提问:

公众号的菜单已分为“读书总结”、“分布式”、“机器学习”、“深度学习”、“NLP”、“Java深度”、“Java并发核心”、“JDK源码”、“Tomcat内核”等,可能有一款适合你的胃口。
为什么写《Tomcat内核设计剖析》
欢迎关注:

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

