HTTP协议内攻击检测基本原理
网络攻击最重要的载体协议是HTTP协议,能利用HTTP协议进行的网络攻击方式多样,不限于以下内容。
- SQLI,XSS,CSRF,RCE,LFI,RFI,Brute Force,SSRF,SSTI,Deserialization,XXE。
我们在对HTTP攻击检测时,由于各种原因,我们无法做到一个理想状态,我会以四个从攻击者视角的例子对此加以说明。
S2-045远程代码执行漏洞(CVE-2017-5638)
这个漏洞是J2EE框架Struts2存在远程代码执行,官方定义为高危,这个漏洞的触发点是:Struts2框架对于请求的HTTP数据包的Content-type字段处理不当造成的,攻击者只要在Content-type字段加上攻击载荷即可,因此攻击方式利用非常简单。
Struts2的攻击检测理论上不是很难,由于利用方式都是要先bypass Struts2的ognl沙盒然后再进行java的代码执行操作,这个漏洞利用流程跟之前Struts2的漏洞利用思路上是一致的,而waf设备之前的检测规则对S2-045的payload还是能检测的,那么为什么绝大部分安全检测设备没有检测到呢?答案非常简单,就是没有对HTTP的Content-type字段进行检查,因为检测系统的设计者没有认识到攻击可以出现在HTTP的Content-type字段。
2015年12月的Joomla反序列化漏洞 0-day
说到2015年年底的漏洞界,最著名的毫无争议是Java反序列化漏洞组,但是这个Joomla反序列化漏洞也非常让人兴奋,这个漏洞起始于一个老外发现自己服务器的访问日志存在一段非常非常特别的访问。
2015 Dec 12 16:49:07 clienyhidden.access.log
Src IP: 74.3.170.33 / CAN / Alberta
74.3.170.33 - - [12/Dec/2015:16:49:40 -0500] "GET /contact/ HTTP/1.1" 403 5322 "http://google.com/" "}__test|O:21:/x22JDatabaseDriverMysqli/x22:3: ..
{s:2:/x22fc/x22;O:17:/x22JSimplepieFactory/x22:0: .. {}s:21:/x22/x5C0/x5C0/x5C0disconnectHandlers/x22;a:1:{i:0;a:2:{i:0;O:9:/x22SimplePie/x22:5:..
{s:8:/x22sanitize/x22;O:20:/x22JDatabaseDriverMysql/x22:0:{}s:8:/x22feed_url/x22;s:60:..
这段信息瞬间就在安全圈爆炸,安全研究者分析漏洞,最终发现特定的字符可以导致截断字符消失,接着反序列化串便可以进入unserialize函数。
这个漏洞的攻击载荷存在于User-Agent字段,这个字段往往存储的只是用户的浏览器信息。由于对攻击的理解不到位,这个漏洞的检测在当时也很不如意。
S2-052远程代码执行漏洞(CVE-2017-9805)
S2-052虽然是Struts2家族的RCE漏洞,但是跟之前的S系列的RCE漏洞都不一样,这个漏洞的本质是Java反序列化漏洞。
这里做下简单的科普,明白的可以略过这段内容。什么是反序列化呢?我们都知道,代码中存在对象的概念,本质上对象是一种数据结构。出于一些原因,我们有个需求,要在不同进程中传递这种对象,因此这里就引入了序列化和反序列化。
序列化可以理解为:把内存中的对象转换成一种可以在进程间传递的内容。其载体的形式可以为xml,json,yaml,bin等; 反序列化 可以理解为:把序列化的串反解析成对象的过程。由于载体的多种形式,就会出现很多种反序列化漏洞,比如有名的java反序列化,json反序列化,xml反序列化,yaml反序列化等。
在这个漏洞中,漏洞触发点是REST插件在解析请求中的xml文件时,调用了XStreamHandler,传入的数据会被默认进行反序列化,如果当传入的xml是个经过XStream序列化的恶意对象时,便造成反序列化漏洞。(S2-052的序列化载体就是xml)
在对S2-052进行检测时,难度是很大的,做好很不容易。因为最开始的poc生成是利用marshalsec工具生成ImageIO的远程代码序列化对象,这个poc适用的环境是java1.8以上,这是个非常苛刻的条件。但是之后又有人发现,CommonsCollections5 + XStream和CommonsCollections6 + XStream的利用组合适用于java1.7的环境。所以在做特征检测的时候,考虑到所有的利用形式需要对攻击利用具有非常深厚的理解。
各种SQL注入的bypass
在2016年4月,出了一个让各家安全厂商都很头疼的bypass sql检测的bypass方式,我记得漏洞标题是《Bypass阿里云盾、百度云加速、安全宝、安全狗、云锁、360主机卫士SQL注入防御》,现在来看bypass的方式,其实这个方法的利用方式在sqlmap中早已涉及,只是大家都没太注意罢了。本质上利用注释符号与换行符号的组合,再加以各种干扰字符的插入,导致像下面的内容是可以执行的。
http://192.168.103.129/manning/manning_test_mysql.php?id=1%23 我们为什么要绕过waf呢 script>alert(1)</script> %0aunion select 1,2,3
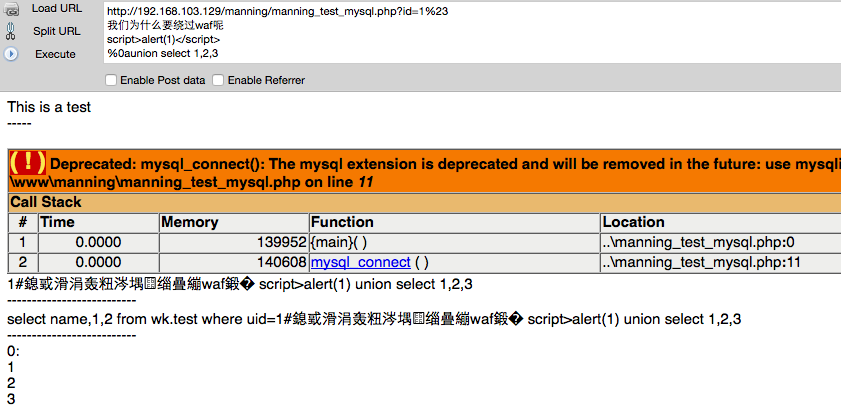
在检测时,由于先匹配出来的一定是xss的特征,导致告警错误的出现,如果在每个空格处都加以这种bypass方式的使用,waf是很难处理的。除非牺牲误报率为代价,否则对抗变形还是很困难的。
常规HTTP攻击检测做法
常规HTTP攻击检测做法流程如下:
- HTTP数据字段拆解
- 重要字段特征匹配(多字段关联匹配)
我认为这种做法是一种老派的做法,由于性能的要求(HTTP数据包在流量中的比例巨大,占据检测计算量消耗的大部分),检测的字段位置大多数都是URI字段和DATA字段,这就导致检测的范围不够完整,因此当面对一些意想不到的漏洞时,效果往往不尽如人意。从例子1,例子2中我们也能看出这个观点。当然如果扩大检测范围,误报的产生也是不可避免。另外不知从何时起,检测设备只关注uri字段,让我非常费解。
特征匹配在安全检测领域是成熟的,高效性,准确性,可维护性都是特征匹配重要的优势。但是特征匹配技术的检测能力体现,往往取决于规则编写者对于攻击理解的程度,对攻击的理解不充分会直接影响检测规则的质量。我们从例子3,例子4可以很好的看出这点。
总结下来,规则检测存在两点不足。
- 检测位置不充分,且易产生误报
- 检测的能力体现取决于规则编写者
适应当今攻防对抗,检测应该具备的能力
当今攻防对抗的升级,不光有攻击载荷变化的情况,还有漏洞点出现在承载协议任意位置的情况。那么有效的检测应该是什么样子呢?我会从整体质量、效率、运营上提出我的观点。
首先在检测能力和质量上
- 检测内容不区分协议字段
- 具备对抗混淆的能力
- 能定义正常,异常,攻击
接着在检测效率上
- 高于正则匹配的效率
最后在日常运营上
- 具备高效的处理误报与漏报
- 能高效的进行应急响应
谈一些工作中的实践
在实际工作中,我们利用机器学习技术进行了大量实践,进行了包括异常识别、攻击识别等内容,取得了卓越的效果。
比如我们现在每天处理的数据量在1800亿左右的HTTP访问数据,其中发现异常请求数据只有8000万次。这种检测量级的下降,让我们能做更深入的包检测。
总结
本文从开始的介绍历史漏洞出发,阐述的了当前检测技术的一些不足,并以此展望了理想检测技术应该具备的能力,以及介绍了我们当前的一些实践结果。
广告时间
我们目前正在打造一款全部由AI技术构建的入侵感知系统,目前系统集群日处理数据达到1800亿次。 如果对我们做的产品感兴趣,或者想加入我们,请联系 emhhbmd4aW4xW2F0XTM2MC5jbgo= 城市:北京
参考文章
https://blog.sucuri.net/2015/12/remote-command-execution-vulnerability-in-joomla.html http://blog.csdn.net/rossrocket/article/details/67674290 https://www.anquanke.com/post/id/83119
正文到此结束
- 本文标签: 云 ip 标题 Google HTML 阿里云 文章 本质 mysql 质量 产品 漏洞 CTO REST http id remote 进程 数据 注释 插件 主机 HTTP协议 tab 广告 UI 时间 XML 运营 Struts2 协议 map 需求 Collections src Collection 服务器 js sql 代码 json 百度 IO PHP https 安全 GitHub Select 总结 NIO java git 集群 SDN 解析 锁 2015 Agent
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

