从JVM角度看看Java的clone操作
最近在给熔断器组件增加一个降级策略(Hystrix好像没有这个配置),我们提供了如下几种策略:
1、默认策略
2、返回常量值
3、抛出指定异常
4、执行一段groovy脚本
当然了,这些配置都是可以在平台上配置,并立即生效的。
目前返回常量值的实现如下:
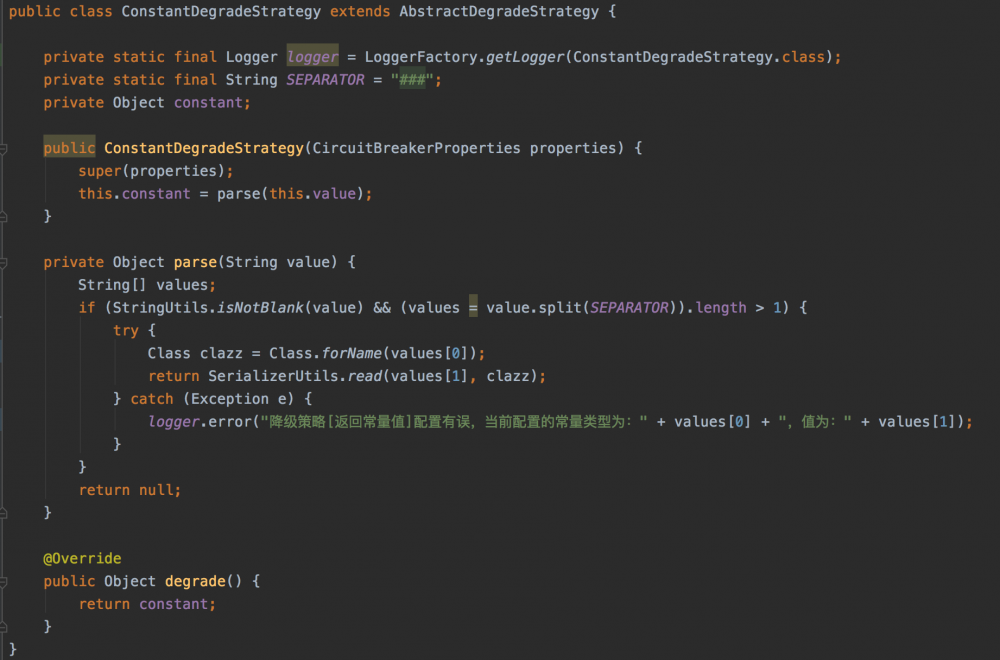
今天发现,如果每次都返回同一个对象,而且这个逻辑对业务来说是黑盒(业务不知道每次拿到的对象是同一个),如果对这个对象进行了操作,那肯定会影响到其它的请求,为了避免背锅,我们需要每次返回一个新的对象,第一反应是通过clone是否可行(因为每次json的序列化也会损耗性能),但是jdk自带的clone方法只是浅克隆,如果对象中包含了另一个复杂对象,clone出来的对象还是存在被修改的风险。
大家可以看下面一个例子:
class Master {
String name;
public Master(String name) {
this.name = name;
}
}
初始化一个Master类
class Dog implements Cloneable {
String name;
int age;
Master master;
public Dog(String name, int age, Master master) {
this.name = name;
this.age = age;
this.master = master;
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
@Override
public String toString() {
return "{name:" + name + ", age: " + age + ", master: "+ master.name + "}";
}
}
再初始化一条狗
public static void main(String[] args) throws Exception {
Master master = new Master("zj0");
Dog dog1 = new Dog("旺财", 1, master);
Dog dog2 = (Dog)dog1.clone();
dog1.name = "比利";
dog1.master.name = "zj1";
System.out.println(dog2);
}
最后运行一下,结果如下:
{name:旺财, age: 1, master: zj1}
dog1是原始狗,dog2是克隆出来的,但是我修改dog1的master的name时,克隆的master也跟着变化了,这显然不行。
虽然一直都知道Object的clone方法是浅克隆,也一直没继续探索一下,今天碰到了就顺手看下JVM的实现,好像很简单,在jvm.cpp文件中,搜索"JVM_Clone"
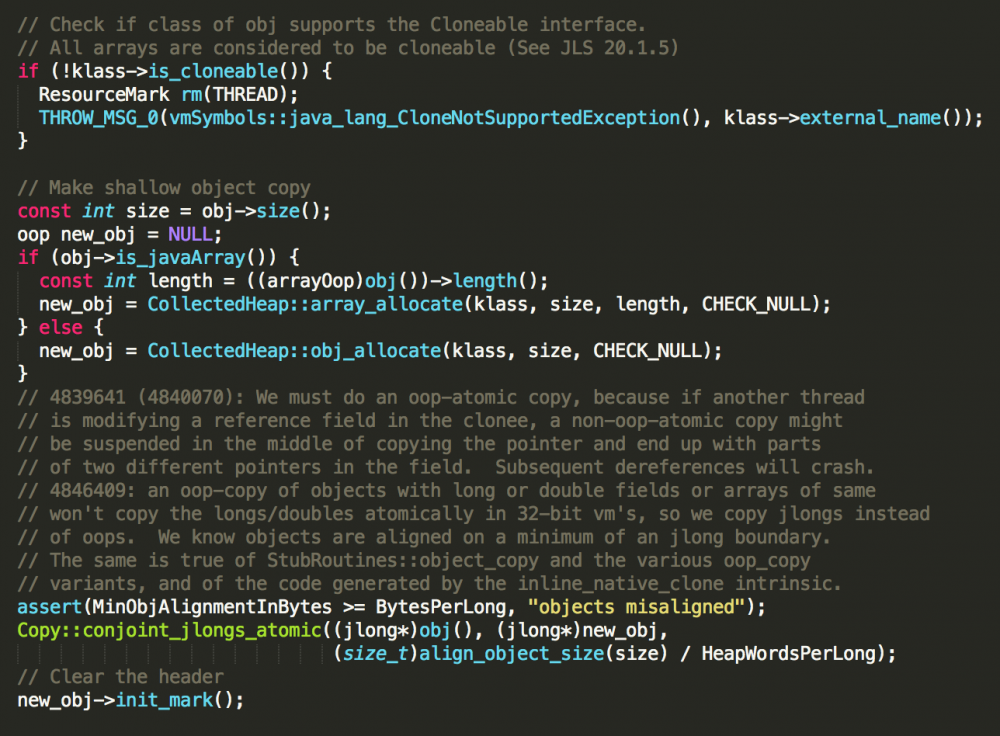
以前一直没用过clone这个方法,通过源码发现在运行的时候会检查类是否实现Cloneable接口,编译的时候不检查,想啥呢?
根据对象或者数据的大小,从堆中开辟一块同等大小的内存,然后把原始对象的数据都复制到新的内存地址,对于基本类型,可以把原始值复制过来,但是对于内部对象来说,其保存的只是一个地址,复制时也是对地址的复制,最终还是指向同一个对象,所以就造成了上述的问题。
更多精彩问题,欢迎加入知识星球
460+小伙伴正在讨论

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

