数据中心丢包分析及解决方案
上周对数据中心tcp数据传输的超时重传时间进行了探究,是的,我们可以缩短重传超时时间,但为什么在数据中心内部也会出现丢包呢?下面会对这个问题进行探讨。
下面几种丢包情形是大家所熟悉的:1、数据中心内网的某个端口的带宽跑满2、四层,如lvs状态表溢出,新建连接时无法分配状态,所以放弃新连接3、七层,包括web服务器的监听队列backlog满,丢弃新建的连接请求接下来分析一个跟应用部署架构相关的丢包场景,如下图:
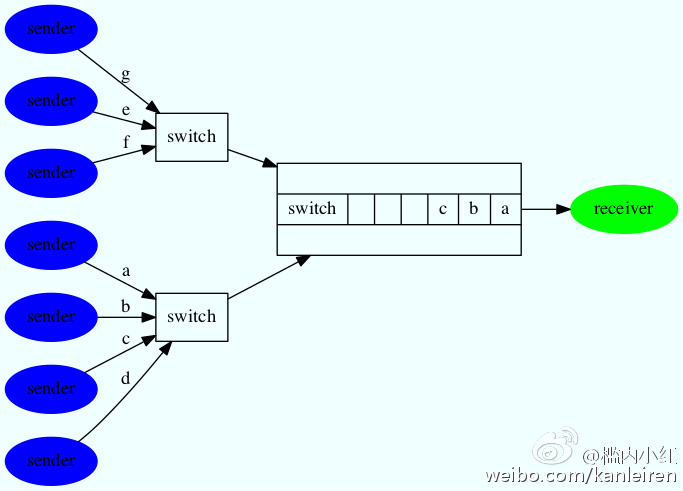
多个发送者向一个接受者发送数据,这样接受方上连的交换机端口,在任何一时刻只能发送一个数据包,而与此同时会收到多个待发送的数据包,交换机有两种办法来应对这样的传输场景:
1、发送数据的速度,比发送者发送的数据的速度快。比如,接受方上连的端口是万兆,而所有发送者都是千兆上连。
2、每个端口有一个ouput buffer,该端口的外发数据包,暂存在这个obuf中
交换机端口的output buffer满时,再往这个端口发送数据包时,新来的包就会被交换机丢弃,这就是网络层丢包的原因之一。
理论上讲,发送方增加一倍机器,对output buffer需求增加一倍,同样,发送方的发送数据的速度增加一倍,对output buffer的需求也会培加一倍。而交换机的buffer是有限的,这样丢包的机率跟发送方的数量和发送的速度正相关。
在数据中心内部有哪些地方,存在多方向一方发数据,而丢包呢,接着看下图:

如上图,丢包的情况如下:
1、多台七层设备,如haproxy,向四层lvs回数据包
2、多台real server,向七层如haproxy回数据包
3、服务器访问多台mc或redis,这样多台mc向服务器回数据包
4、服务器访问内部的服务,多台服务器向内部的lvs机器发送数据包;多台服务器访问同一个内部资源,如redis也是类似的场景
而同城多个idc之间,还存在一个丢包场景,如下图:

上面两个数据中心,通过内部专线连通,左边的数据中心多台服务器,发送数据到右边的数据中心的服务器上,左边的数据中心跟专线相连的交换机端口,存在交换机buffer不够,而丢包的情形。
上面分析了丢包的场景,接下来分析可能的解决方案,如下图:
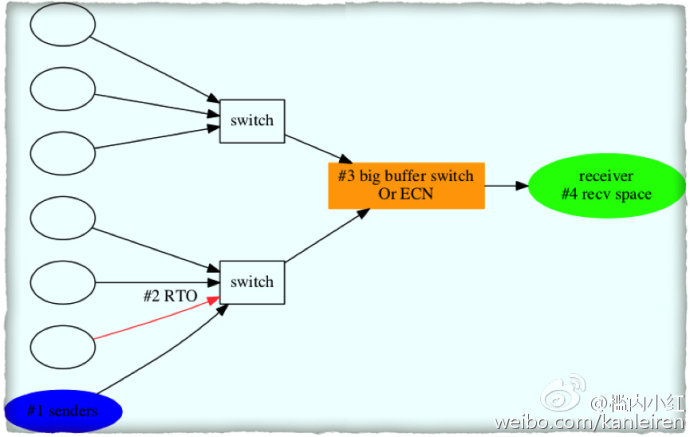
1、减少发送方的数量。这个需要修改部署架构。
2、降低数据传送的rto时间,这样在buffer刚满丢包时,发送方就能发现丢包,而快速降低发送速度,避免事态扩大。
3、 更换大buffer交换机,这个治标不治本。另外的方式是交换机支持ECN(Explict Congestion Notification),在output buffer达到某个阈值时,在发出去的包的ip头上增加ecn标志,接受方收到数据后,回传的数据包或ack包会带上ecn标志,发送方收到数据或 ack后,就能发现链路中资源吃紧,快速响应降低发送速度,重而避免出现buffer满。
4、接受方降低tcp的recv space,减少发送方的速度。
在跨idc丢包的场景中,依赖于所有项目都能协调一致进行调整,不然,一个项目做合法公民,与事无补,呵呵。
欢迎拍砖和提供更多的丢包场景。呵呵。
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

