Java爬虫之批量下载LibreStock图片(可输入关键词查询下载)
公司产品新版本刚刚上线,所以也终于得空休息一下了,有了一点时间。由于之前看到过爬虫,可以把网页上的数据通过代码自动提取出来,觉得挺有意思的,所以也想接触一下,但是网上很多爬虫很多都是基于Python写的,本人之前也学了一点Python基础,但是还没有那么熟练和自信能写出东西来。所以就想试着用Java写一个爬虫,说起马上开干!爬点什么好呢,一开始还纠结了一下,到底是文本还是音乐还是什么呢,突然想起最近自己开始练习写文章,文章需要配图,因为文字太枯燥,看着密密麻麻的文字,谁还看得下去啊,俗话说 好图配文章,阅读很清爽 ~ 哈哈哈ヾ(◍°∇°◍)ノ゙”,对,我的名字就叫俗话,皮了一下嘻嘻~。所以要配一个高质量的图片才能赏心悦目,所以就想要不爬个图片吧,这样以后妈妈再也不用担心我的文章配图了。加上我之前看到过一个国外的图片网站,质量绝对高标准,我还经常在上面找壁纸呢,而且支持各种尺寸高清下载,还可以自定义尺寸啊,最重要的是免费哦 ~ 简直不要太方便,在这里也顺便推荐给大家,有需要的可以Look一下,名字叫 LibreStock 。其实这篇文章的配图就是从这上面爬下来的哦~好了,说了这么多其实都是废话,下面开始进入正题。
概述
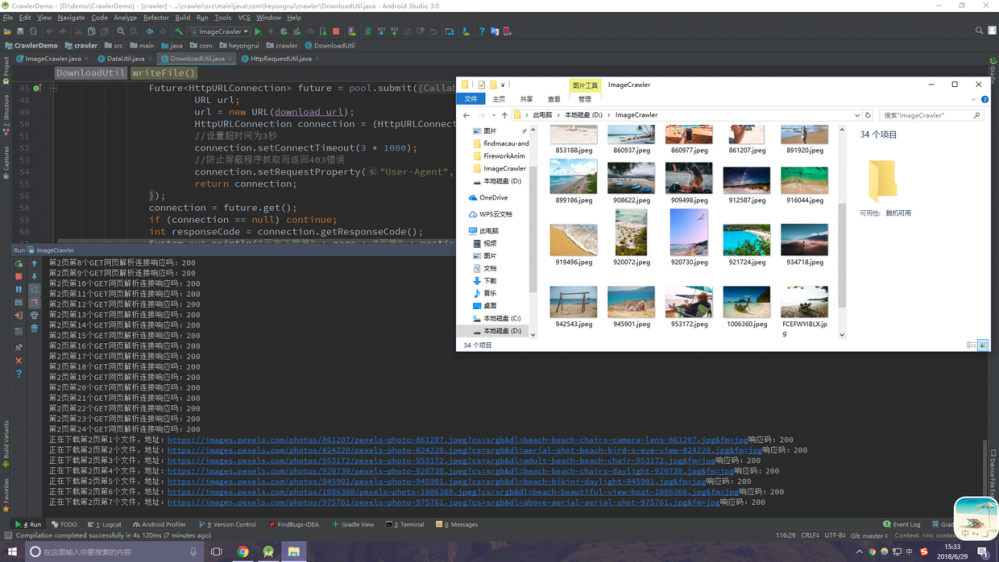
爬虫,顾名思义,是根据网页上的数据特征进行分析,然后编写逻辑代码对这些特征数据进行提取加工为自己可用的信息。 ImageCrawler 是一款基于Java编写的爬虫程序,可以爬取 LibreStock 上的图片数据并下载到本地,支持输入关键词爬取,运行效果如下。
分析
首先打开 LibreStock 网站,点击F12查看源码,如下图
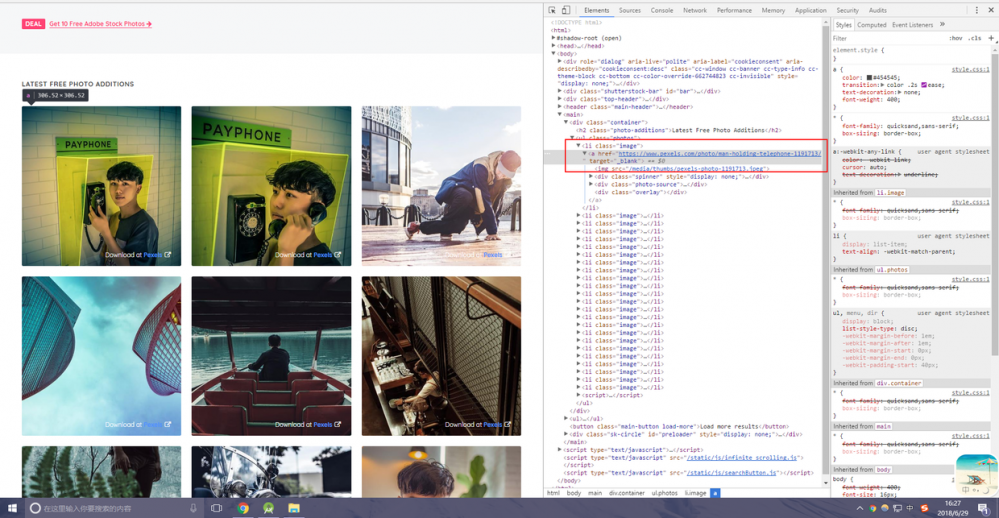
下有一个图片的超链接,这个就是对应图片的详情地址,所以这里还不能拿到图片的源地址,我们再点进去再看
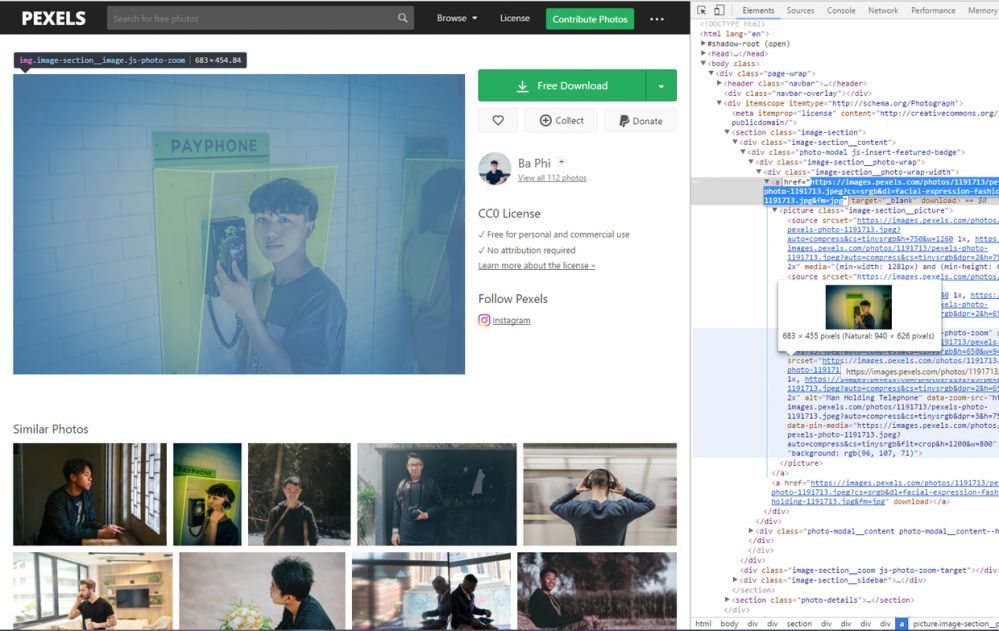
可以看到,在多层的div有一个href超链接,这个就是图片的源地址,但是好像下面还有href诶,而且也是图片的地址,这里不用管,我们取一个就可以。这个href是在image-section__photo-wrap-width的这个div里面的,所以大概特征我们就找到了。此处你认为就完成了就太天真了,经过我多次测试,踩了一些坑之后才发现并没有那么简单。
其实最开始我的做法是通过比较列表页的
下的src属性和图片详情页的源地址href属性,然后将src中的值进行提取拼接成一个固定格式的链接,这个链接就是这张图片的源地址(后面发现图片的源地址链接可以有很多,其中可以配置不同的图片参数,链接就是对应参数的图片),然后进行下载。后来发现此方法并不稳定,因为测试发现并不是所有图片源地址都支持这种格式,而且这种方法也只能获取到页面第一次加载的图片数,因为下拉会加载更多,这个时候是处理不了这种情况的,此时就很尴尬了 ~ 既然要爬取,肯定是要针对大量数据的,所以首先是要解决不能爬取下拉加载更多的这种情况,既然有数据加载,肯定会设计到网络访问,于是通过Fiddler进行抓包发现下拉到底部的时候会触发一个异步加载。
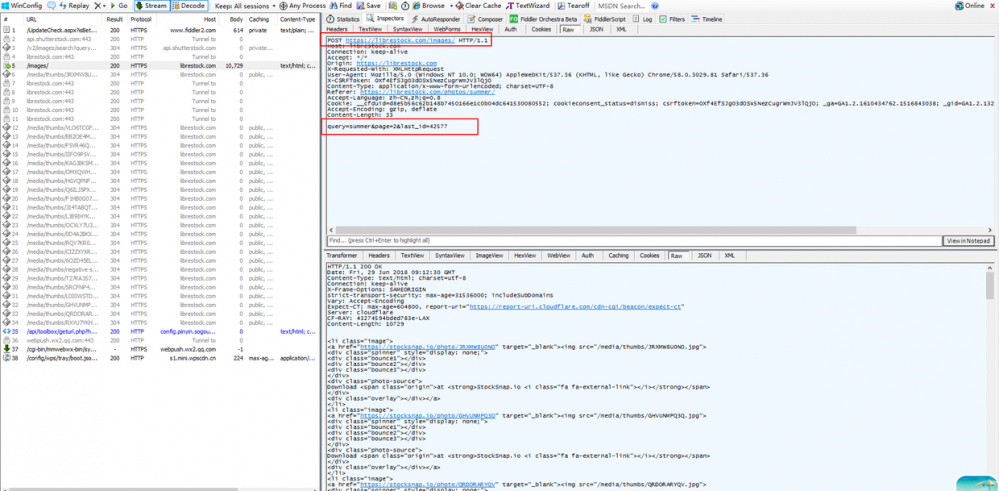
会请求一次接口,然后返回下一页的列表数据,既然知道了数据的获取方式,我们就可以伪造一个一模一样的数据请求,然后拿到下一页的数据。但是什么时候加载完呢,通过观察发现每次接口的返回数据里有一个js的部分,如下图:
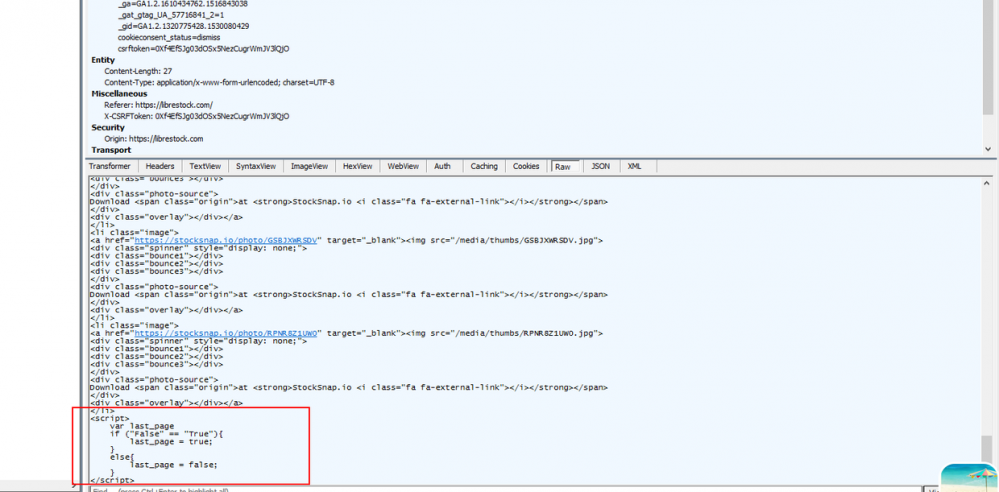
这个last_page就是标识,当加载到最后一页时,last_page就会为true,但是我们只能获取到返回的数据的字符串,怎么对这个js的函数进行判断呢,测试发现加载到最后一页时, False==True 这个会变成 True==True ,所以可以通过判断这个字符串来作为爬取的页数标识。好了,至此就解决了加载更多的问题。
我们可以拿到每一页的图片列表数据,但是图片列表里面没有图片的源地址,接下来就是解决这个问题,我之前一直都是想直接通过爬取列表页的数据就拿到源地址,但是发现通过拼接的源地址并不适用于所有的图片,于是我试着改变思路,通过
中的数据拿到图片的详细地址,再进行一次源码爬取,这样就可以拿到对应图片的详细页面的源码了,通过详情页的源码就可以获取到图片的源地址了。OK,大体流程就是这样了。
实施
通过分析已经清楚大致的流程了,接下来就是编码实现了。由于本人从事的是Android开发,所以项目就建在了一个Android项目里,但是可以单独运行的Java程序。 首先需要伪造一个一模一样的异步网络请求,观察上面图中的数据可以看出,请求包含一些头部的设置和token参数等配置信息,照着写下来就可以了,另外,请求是一个Post,还带有三个参数( query , page , last_id ), query 则是我们查询的图片的关键词, page 是当前页数, last_id 不清楚,不用管,设置为固定的和模板请求一样的即可。
public static String requestPost(String url, String query, String page, String last_id) {
String content = "";
HttpsURLConnection connection = null;
try {
URL u = new URL(url);
connection = (HttpsURLConnection) u.openConnection();
connection.setRequestMethod("POST");
connection.setConnectTimeout(50000);
connection.setReadTimeout(50000);
connection.setRequestProperty("Host", "librestock.com");
connection.setRequestProperty("Referer", "https://librestock.com/photos/scenery/");
connection.setRequestProperty("X-Requested-With", "XMLHttpRequest");
connection.setRequestProperty("Origin", "https://librestock.com");
connection.setRequestProperty("User-Agent", "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.3; Trident/7.0;rv:11.0)like Gecko");
connection.setRequestProperty("Accept-Language", "zh-CN");
connection.setRequestProperty("Connection", "Keep-Alive");
connection.setRequestProperty("Charset", "UTF-8");
connection.setRequestProperty("X-CSRFToken", "0Xf4EfSJg03dOSx5NezCugrWmJV3lQjO");
connection.setRequestProperty("Cookie", "__cfduid=d8e5b56c62b148b7450166e1c0b04dc641530080552;cookieconsent_status=dismiss;csrftoken=0Xf4EfSJg03dOSx5NezCugrWmJV3lQjO;_ga=GA1.2.1610434762.1516843038;_gid=GA1.2.1320775428.1530080429");
connection.setDoInput(true);
connection.setDoOutput(true);
connection.setUseCaches(false);
if (!TextUtil.isNullOrEmpty(query) && !TextUtil.isNullOrEmpty(page) && !TextUtil.isNullOrEmpty(last_id)) {
DataOutputStream out = new DataOutputStream(connection
.getOutputStream());
// 正文,正文内容其实跟get的URL中 '? '后的参数字符串一致
String query_string = "query=" + URLEncoder.encode(query, "UTF-8");
String page_string = "page=" + URLEncoder.encode(page, "UTF-8");
String last_id_string = "last_id=" + URLEncoder.encode(last_id, "UTF-8");
String parms_string = query_string + "&" + page_string + "&" + last_id_string;
out.writeBytes(parms_string);
//流用完记得关
out.flush();
out.close();
}
connection.connect();
int code = connection.getResponseCode();
System.out.println("第" + page + "页POST网页解析连接响应码:" + code);
if (code == 200) {
InputStream in = connection.getInputStream();
InputStreamReader isr = new InputStreamReader(in, "utf-8");
BufferedReader reader = new BufferedReader(isr);
String line;
while ((line = reader.readLine()) != null) {
content += line;
}
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (connection != null) {
connection.disconnect();
}
}
return content;
} 如上代码就是伪造的请求方法,返回当前请求的结果源码HTML,拿到源码以后,我们需要提取最后一页参数标识。如果是最后一页,则更新标识,将不再请求。
public boolean isLastPage(String html) {
//采用Jsoup解析
Document doc = Jsoup.parse(html);
//获取Js内容,判断是否最后一页
Elements jsEle = doc.getElementsByTag("script");
for (Element element : jsEle) {
String js_string = element.data().toString();
if (js_string.contains("/"False/" == /"True/"")) {
return false;
} else if (js_string.contains("/"True/" == /"True/"")) {
return true;
}
}
return false;
} 拿到列表源码,我们还需要解析出列表中的图片的详情链接。测试发现列表的详情href的div格式又是可变的,这里遇到两种格式,不知道有没有第三种,但是两种已经可以适应绝大部分了。
//获取html标签中的img的列表数据
Elements elements = doc.select("li[class=image]");//第一种格式
if (elements == null || elements.size() == 0) {
elements = doc.select("ul[class=photos]").select("li[class=image]");//第二种格式
}
if (elements == null) return imageModels;
int size = elements.size();
for (int i = 0; i < size; i++) {
Element ele = elements.get(i);
Elements hrefEle = ele.select("a[href]");
if (hrefEle == null || hrefEle.size() == 0) {
System.out.println("第" + page + "页第" + (i + 1) + "个文件hrefEle为空");
continue;
}
String img_detail_href = hrefEle.attr("href"); 拿到图片详情页的超链接后,再请求一次详情页面链接,拿到详情页面的源码,
String img_detail_entity = HttpRequestUtil.requestGet(img_detail_href, page, (i + 1));//获取详情源码
然后就可以对源码进行解析,拿到图片的源地址,测试发现图片源地址的格式也有多种,经过实践发现大概分为四种,获取到图片源地址,我们可以对这个源地址url进行提取文件名作为下载保存的文件名,然后保存到图片模型中,所以根据详情页源码提取出图片源地址的代码如下:
public ImageModel getModel(String img_detail_html) throws Exception {
if (TextUtil.isNullOrEmpty(img_detail_html)) return null;
//采用Jsoup解析
Document doc = Jsoup.parse(img_detail_html);
//获取html标签中的内容
String image_url = doc.select("div[class=img-col]").select("img[itemprop=url]").attr("src");//第一种
if (TextUtil.isNullOrEmpty(image_url)) {
image_url = doc.select("div[class=image-section__photo-wrap-width]").select("a[href]").attr("href");//第二种
}
if (TextUtil.isNullOrEmpty(image_url)) {
image_url = doc.select("span[itemprop=image]").select("img").attr("src");//第三种
}
if (TextUtil.isNullOrEmpty(image_url)) {
image_url = doc.select("div[id=download-image]").select("img").attr("src");//第四种
}
if (TextUtil.isNullOrEmpty(image_url)) return null;
ImageModel imageModel = new ImageModel();
String image_name = TextUtil.getFileName(image_url);
imageModel.setImage_url(image_url);
imageModel.setImage_name(image_name);
return imageModel;
} 综上上面的代码,从网页列表源码中提取出多个图片模型的代码如下:
public Vector<ImageModel> getImgModelsData(String html, int page) throws Exception {
//获取的数据,存放在集合中
Vector<ImageModel> imageModels = new Vector<>();
//采用Jsoup解析
Document doc = Jsoup.parse(html);
//获取html标签中的img的列表数据
Elements elements = doc.select("li[class=image]");
if (elements == null || elements.size() == 0) {
elements = doc.select("ul[class=photos]").select("li[class=image]");
}
if (elements == null) return imageModels;
int size = elements.size();
for (int i = 0; i < size; i++) {
Element ele = elements.get(i);
Elements hrefEle = ele.select("a[href]");
if (hrefEle == null || hrefEle.size() == 0) {
System.out.println("第" + page + "页第" + (i + 1) + "个文件hrefEle为空");
continue;
}
String img_detail_href = hrefEle.attr("href");
if (TextUtil.isNullOrEmpty(img_detail_href)) {
System.out.println("第" + page + "页第" + (i + 1) + "个文件img_detail_href为空");
continue;
}
String img_detail_entity = HttpRequestUtil.requestGet(img_detail_href, page, (i + 1));
if (TextUtil.isNullOrEmpty(img_detail_entity)) {
System.out.println("第" + page + "页第" + (i + 1) + "个文件网页实体img_detail_entity为空");
continue;
}
ImageModel imageModel = getModel(img_detail_entity);
if (imageModel == null) {
System.out.println("第" + page + "页第" + (i + 1) + "个文件模型imageModel为空");
continue;
}
imageModel.setPage(page);
imageModel.setPostion((i + 1));
//将每一个对象的值,保存到List集合中
imageModels.add(imageModel);
}
//返回数据
return imageModels;
} 获取到图片的源地址后,接下来就是下载到本地了,一个页面有多个图片,所以下载用线程池比较合适。因为一个列表页是24张图片,所以这里线程池的大小就设为24,解析完一个页面的列表,就把这个页面的图片列表传给下载器, 当这个列表的任务完成以后,就去解析下一页的数据,然后重复循环这个过程,直到判断是最后一页了,就结束此次爬取。
public void startDownloadList(Vector<ImageModel> downloadList, String keyword) {
HttpURLConnection connection = null;
//循环下载
try {
for (int i = 0; i < downloadList.size(); i++) {
pool = Executors.newFixedThreadPool(24);
ImageModel imageModel = downloadList.get(i);
if (imageModel == null) continue;
final String download_url = imageModel.getImage_url();
final String filename = imageModel.getImage_name();
int page = imageModel.getPage();
int postion = imageModel.getPostion();
Future<HttpURLConnection> future = pool.submit(new Callable<HttpURLConnection>() {
@Override
public HttpURLConnection call() throws Exception {
URL url;
url = new URL(download_url);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
//设置超时间为3秒
connection.setConnectTimeout(3 * 1000);
//防止屏蔽程序抓取而返回403错误
connection.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
return connection;
}
});
connection = future.get();
if (connection == null) continue;
int responseCode = connection.getResponseCode();
System.out.println("正在下载第" + page + "页第" + postion + "个文件,地址:" + download_url + "响应码:" + connection.getResponseCode());
if (responseCode != 200) continue;
InputStream inputStream = connection.getInputStream();
if (inputStream == null) continue;
writeFile(inputStream, "d://ImageCrawler//" + keyword + "//", URLDecoder.decode(filename, "UTF-8"));
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (null != connection)
connection.disconnect();
if (null != pool)
pool.shutdown();
while (true) {
if (pool.isTerminated()) {//所有子线程结束,执行回调
if (downloadCallBack != null) {
downloadCallBack.allWorksDone();
}
break;
}
}
}
} 保存到本地的代码如下,保存到的是自定义文件夹的目录,目录的名称是输入的爬取的关键词,下载的图片的名字是根据源地址的url提取得到
public void writeFile(InputStream inputStream, String downloadDir, String filename) {
try {
//获取自己数组
byte[] buffer = new byte[1024];
int len = 0;
ByteArrayOutputStream bos = new ByteArrayOutputStream();
while ((len = inputStream.read(buffer)) != -1) {
bos.write(buffer, 0, len);
}
bos.close();
byte[] getData = bos.toByteArray();
//文件保存位置
File saveDir = new File(downloadDir);
if (!saveDir.exists()) {
saveDir.mkdir();
}
File file = new File(saveDir + File.separator + filename);
FileOutputStream fos = new FileOutputStream(file);
fos.write(getData);
if (fos != null) {
fos.close();
}
if (inputStream != null) {
inputStream.close();
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
} 好了,所有的工作都完成了,让我们跑起来看看效果吧 ~ 输入 wallpaper 为查询的关键词,然后回车,可以看到控制台输出了信息(对于我这个强迫症来首,看起来很舒适),文件夹也生成了对应的图片文件,OK,大功告成!
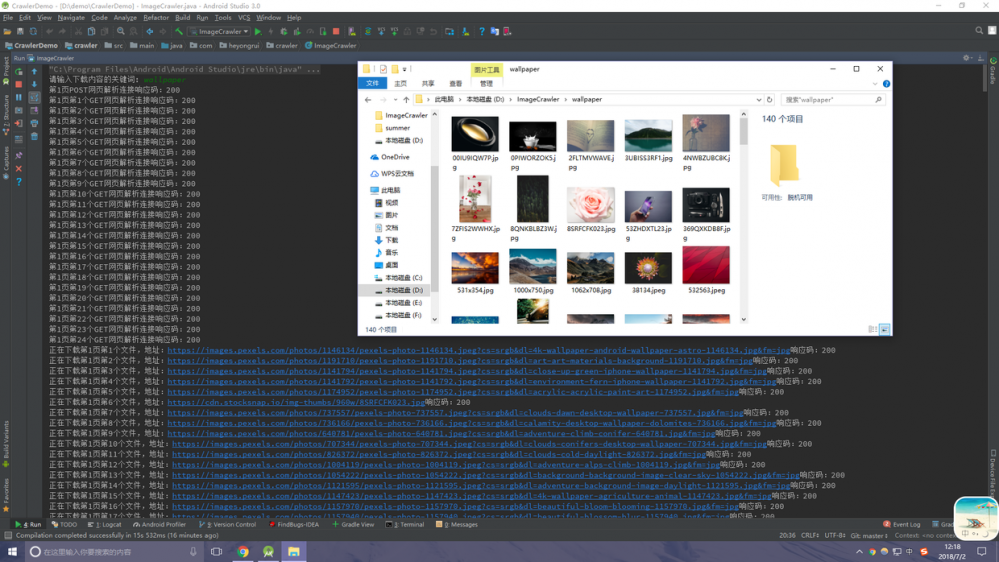
以上就是整个爬取的流程,最后,完整的代码已经上传到了 github ,欢迎各位小伙伴fork。
正文到此结束
- 本文标签: lib python executor Agent java git 网站 CTO XML Connection ACE cache token rmi ip cat 时间 Select final Word ORM Keep-Alive 目录 mina 产品 代码 Document 开发 关键词 Property 模型 质量 线程 GitHub parse 参数 http 线程池 id db tar IDE 解析 DDL 免费 MQ windows 数据 jsoup REST entity 下载 IO 源码 js UI Android list src 文章 图片 测试 https 配置 HTML key
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

