Java源码系列(11) - LinkedHashMap
一、类签名
LinkedHashMap<K,V> 继承自 HashMap<K,V> ,可知存入的节点key永远是唯一的。可以通过Android的 LruCache 了解 LinkedHashMap 用法。
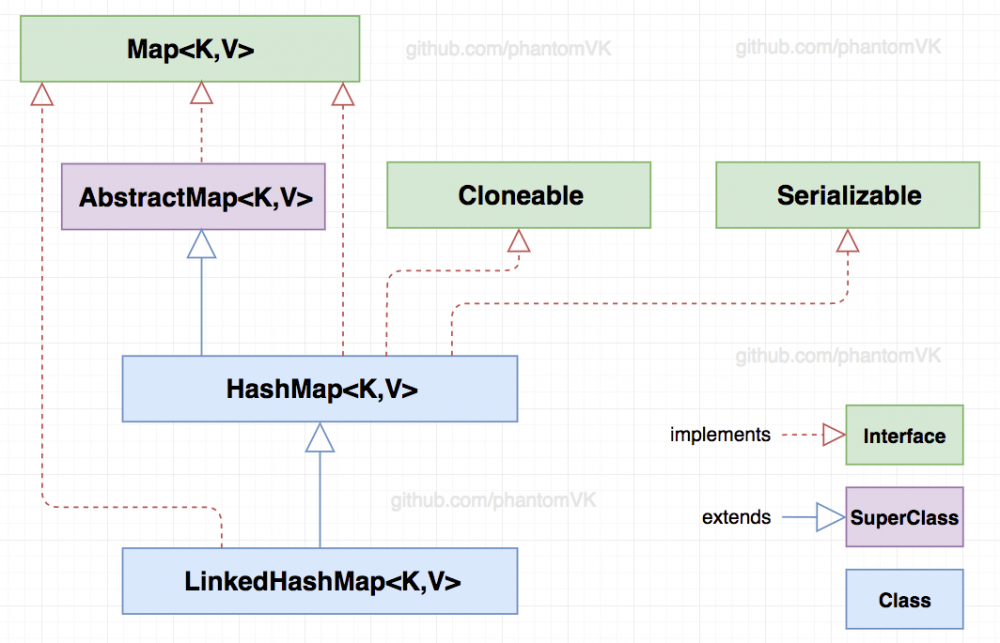
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
二、节点
Entry<K,V> 是 HashMap.Node<K,V> 的子类,增加 before 、 after 引用实现双向链表
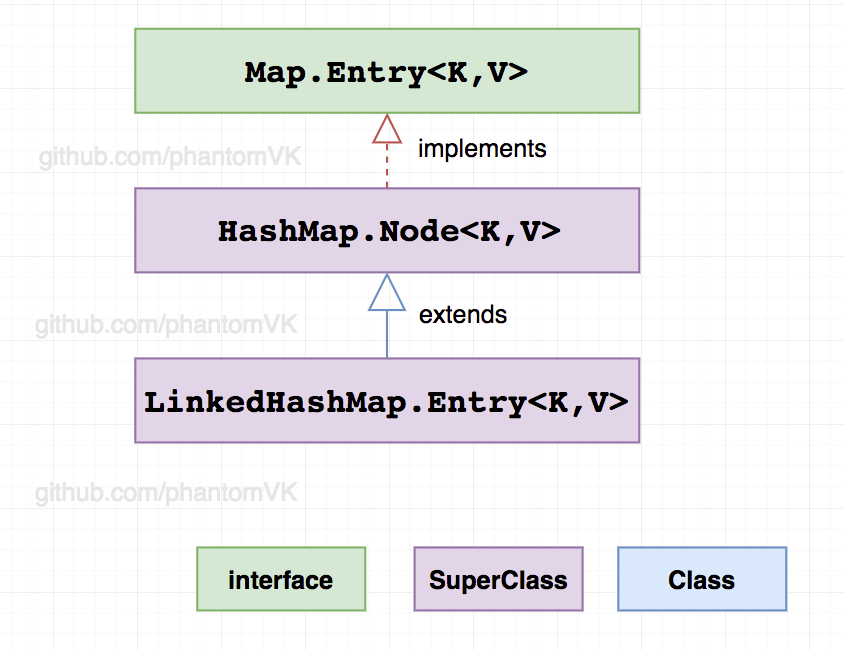
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after; // 前节点、后节点
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next); // 调用HashMap构造方法
}
}
三、数据成员
// 双向链表头,指向最早(最老)访问节点元素 transient LinkedHashMap.Entry<K,V> head; // 双向链表尾,指向最近(最年轻)访问节点元素 transient LinkedHashMap.Entry<K,V> tail; // 是否保持访问顺序,为true则每次访问节点都会放到链表尾部 final boolean accessOrder;
四、构造方法
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
public LinkedHashMap() {
super();
accessOrder = false;
}
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
// 维持存取顺序仅能通过此构造方法
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
五、成员方法
// 把节点插入到链表尾部
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
// 如果尾节点为空表明链表没有元素,则p就是头结点
if (last == null)
head = p;
else {
// 处理双向链表节点
p.before = last;
last.after = p;
}
}
// apply src's links to dst
private void transferLinks(LinkedHashMap.Entry<K,V> src,
LinkedHashMap.Entry<K,V> dst) {
LinkedHashMap.Entry<K,V> b = dst.before = src.before;
LinkedHashMap.Entry<K,V> a = dst.after = src.after;
if (b == null)
head = dst;
else
b.after = dst;
if (a == null)
tail = dst;
else
a.before = dst;
}
// 重写HashMap钩子方法
void reinitialize() {
super.reinitialize();
head = tail = null;
}
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<>(hash, key, value, e);
linkNodeLast(p);
return p;
}
Node<K,V> replacementNode(Node<K,V> p, Node<K,V> next) {
LinkedHashMap.Entry<K,V> q = (LinkedHashMap.Entry<K,V>)p;
LinkedHashMap.Entry<K,V> t =
new LinkedHashMap.Entry<>(q.hash, q.key, q.value, next);
transferLinks(q, t);
return t;
}
TreeNode<K,V> newTreeNode(int hash, K key, V value, Node<K,V> next) {
TreeNode<K,V> p = new TreeNode<>(hash, key, value, next);
linkNodeLast(p);
return p;
}
TreeNode<K,V> replacementTreeNode(Node<K,V> p, Node<K,V> next) {
LinkedHashMap.Entry<K,V> q = (LinkedHashMap.Entry<K,V>)p;
TreeNode<K,V> t = new TreeNode<>(q.hash, q.key, q.value, next);
transferLinks(q, t);
return t;
}
六、顺序操作
// 把节点从链表解除链接
void afterNodeRemoval(Node<K,V> e) { // unlink
// p:即是节点e
// b:e的前一个节点
// a:e的后一个节点
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
// 置空节点p的前后引用
p.before = p.after = null;
if (b == null) {
// 可知节点e是链表头结点,则e的下一个节点a作为链表的头结点
head = a;
} else {
// 可知节点e本是中间结点,把e下一个节点a作为e上一个节点的后续节点
b.after = a;
}
if (a == null) {
// 可知节点e本是链表尾节点,则e的上一个节点b作为链表的尾节点
tail = b;
} else {
// 可知节点e本身是中间节点,把e上一个节点b作为e下一个节点的前置节点
a.before = b;
}
}
// 父类HashMap调用putVal()中会调用此方法
void afterNodeInsertion(boolean evict) { // 移除最少使用的节点
LinkedHashMap.Entry<K,V> first; // first是最少使用的节点
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key; // 获取first的key
removeNode(hash(key), key, null, false, true); // 通过key找到对应Node并移除
}
}
// 把节点移动到链表尾
void afterNodeAccess(Node<K,V> e) {
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
// p:即是节点e
// b:e的前一个节点
// a:e的后一个节点
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
// 置空节点p的后引用
p.after = null;
if (b == null) {
// 可知节点e本是头结点,则e的下一个节点a作为链表的头结点
head = a;
} else {
// 可知节点e本是中间结点,把e下一个节点a作为e上一个节点的后续节点
b.after = a;
}
if (a != null) {
// 可知节点e本身是中间节点,把e上一个节点b作为e下一个节点的前置节点
a.before = b;
} else {
// 可知节点e本是尾节点,则e的上一个节点b作为链表的尾节点
last = b;
}
if (last == null) {
head = p; // 链表只有p一个节点
} else {
// 作为尾节点
p.before = last;
last.after = p;
}
tail = p; // tail引用指向p
++modCount; // 修改次数递增
}
}
七、获取
// 检查LinkedHashMap是否包含指定value
public boolean containsValue(Object value) {
// 从链表头结点开始遍历,逐个查找Entry.value是否等于value
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after) {
V v = e.value;
if (v == value || (value != null && value.equals(v)))
return true; // 包含对应value,返回true
}
return false; // 不包含对应value,返回false
}
// 通过Key获取对应Entry的value
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null) {
// 通过key获取Node为空,返回null作为结果
return null;
}
if (accessOrder) {
// 通过key获取Node不为空,执行afterNodeAccess(e)调整顺序
afterNodeAccess(e);
}
return e.value; // 最后把获取的Entry的value返回
}
// 通过Key获取对应Entry的value
public V getOrDefault(Object key, V defaultValue) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null) {
// 通过key获取Node为空,返回defaultValue作为结果
return defaultValue;
}
if (accessOrder) {
// 通过key获取Node不为空,执行afterNodeAccess(e)调整顺序
afterNodeAccess(e);
}
return e.value; // 最后把获取的Entry的value返回
}
八、移除
// 清除所有引用
public void clear() {
super.clear(); // 把HashMap所有Entry都清空
head = tail = null; // 置空head引用和tail引用
}
// 方法主要用于在子类重写,决定最少使用的节点能否被移除
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
-
上一篇
Java源码系列(10) -- Hashtable
正文到此结束
热门推荐










相关文章

近期评论
-
主要用的是AI
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

