牛客网刷题(纯java题型 31~60题)
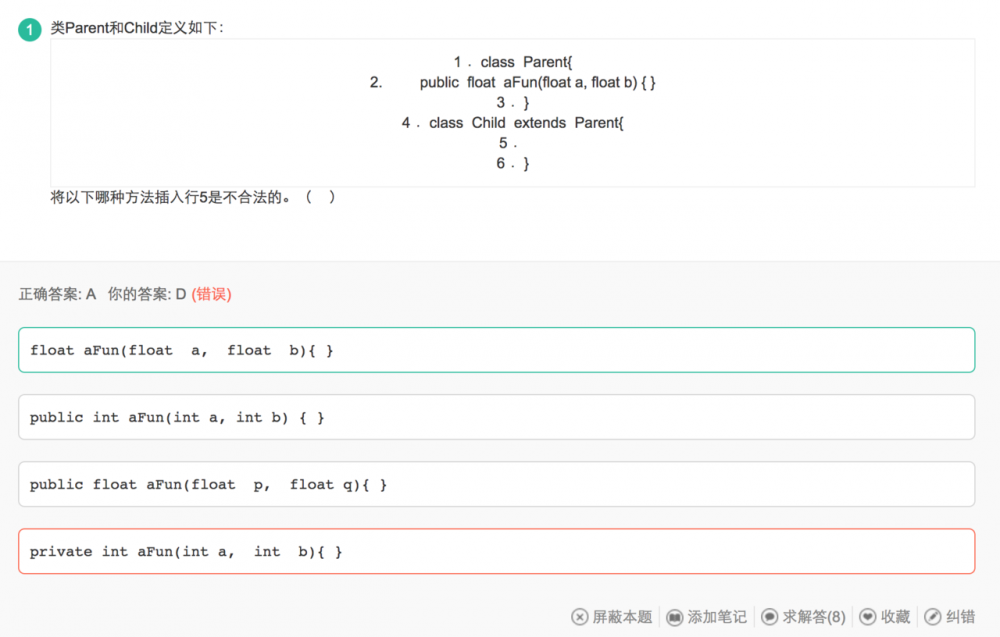

重写Override应该满足"三同一大一小"
三同:方法名相同,参数列表相同,返回值相同或者子类的返回值是父类的子类(这一点是经过验证的)
一大: 子类的访问修饰符比父类开放
一小: 子类抛出的异常比父类的小(具体,或者说子类抛出的异常是父类抛出的异常的子类
通过intellij测试的结果:
在子类中,如果一个方法满足与父类的方法的方法签名(方法名称+参数列表)相同,则一定属于override,那么子类中次方法的返回值就必须满足是父类的子类,且子类方法的修饰符必须比父类更开放
子类中,如果一个方法与父类的方法签名不同(方法名称+参数列表),那么这个方法就是一个子类的新方法,不属于override,也不属于overload,与父类的同名方法没有任何关系
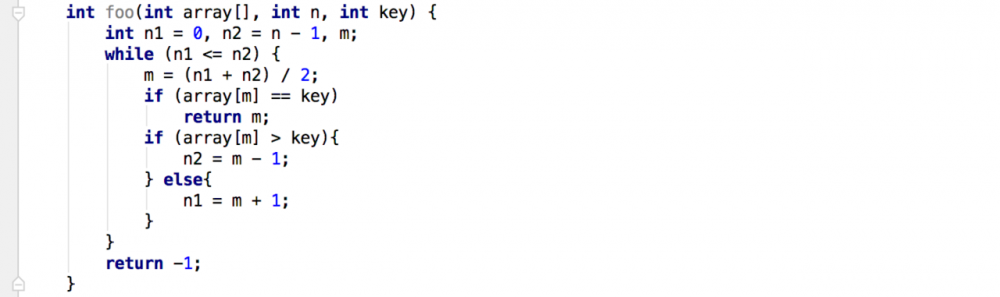
图中的算法是二分查找,二分查找的时间复杂度计算:
第一次折半, n/2
第二次折半,n/(2^2)
第k次折半,n/(2^k)
因为k次折半之后,一定会出现只剩下一个数字的情况,也就是找到了要找的元素
那么也就有 n/(2^k) ==1
所以,k == log2(n),即二分查找的时间复杂度为log2(n)
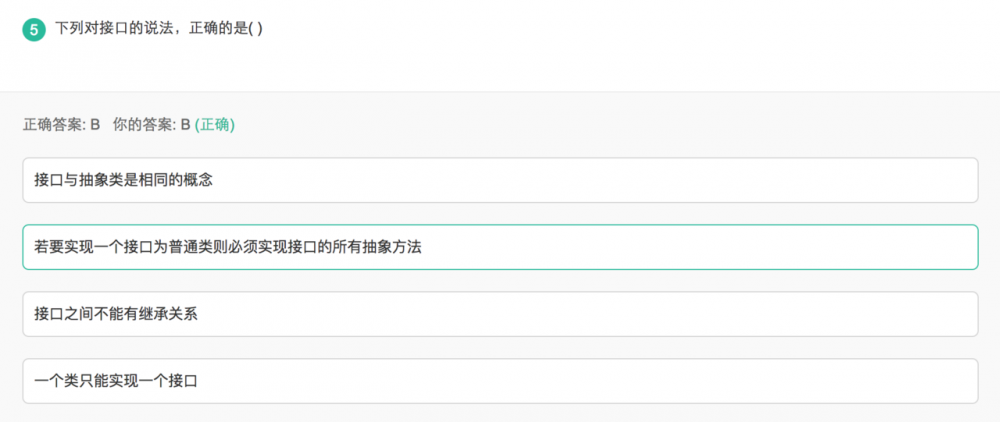
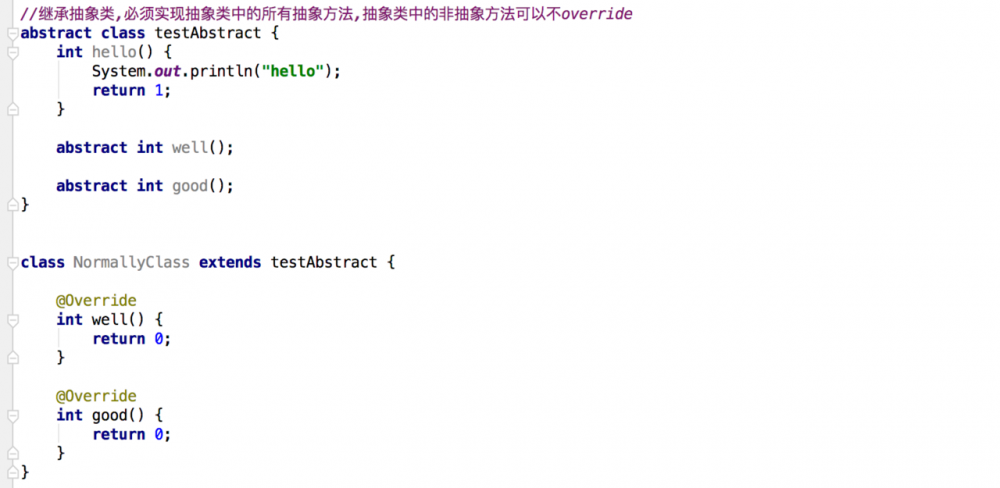
抽象类实现接口,可以不实现接口中的任意方法或者所有方法
普通类实现接口,必须实现接口中的所有方法,接口中的字段field,普通类可以直接使用
普通类继承了抽象类,子必须实现抽象类中的所有抽象方法,对于抽象类中的非抽象方法,可以Override,也可以不Override

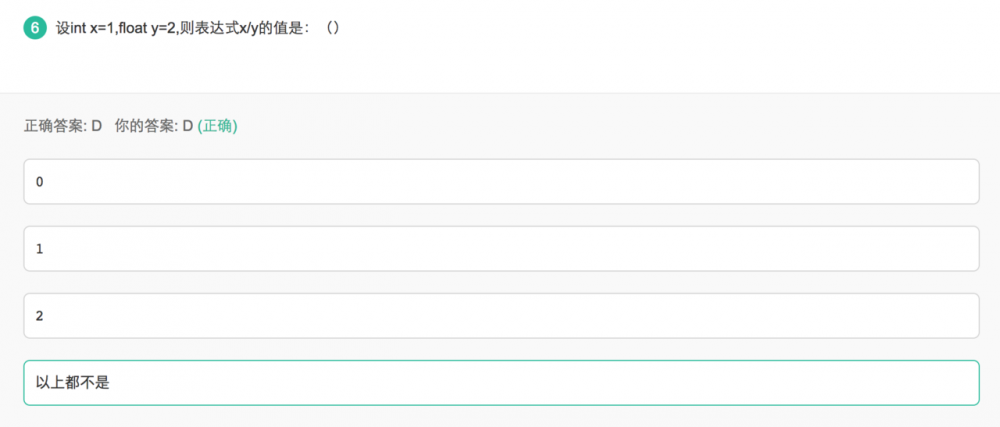
整数类型,默认为int,小数类型,默认为double,而不是float
例如, float result = (float)1.0; //否则报错
多种不同类型的数字进行运算,结果会是以最高精度的为准(自动向上转型),题中1/2.0 为int/double,所以结果应该为double类型的0.5; 即
double result = 1/2.0;
或者 float result =(float)(1/2.0);

依赖注入是通过反射实现的,是一种设计思想,与具体的框架无关,别的框架,也可以实现依赖注入
常见的依赖注入方式包括Setter方法和构造方法
Mock,也叫做伪对象,在测试中利用mock来代替真实的对象,方便测试的进行
封装:将对象的状态信息隐藏在对象内部,不允许外部直接访问
反射机制:在运行状态下,可以调用类的所有属性和方法,包括private属性和方法,所以破坏了封装性
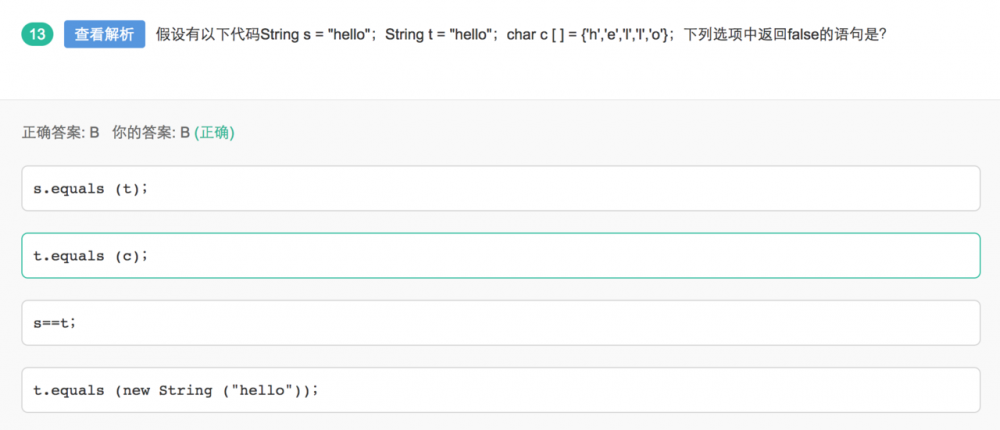

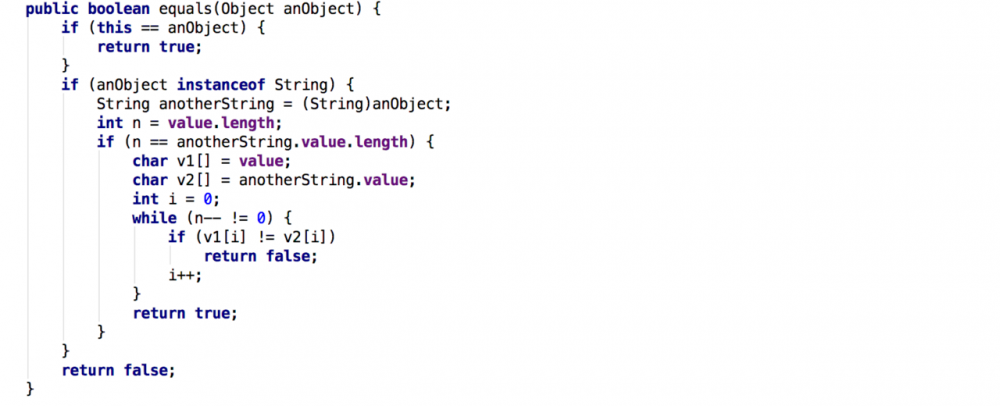
String类的equals方法,只有instanceof之后,发现equal(object)中的object为String类型的对象,才会转换成String,然后比较char[]
执行过程:
boolean b = true?false:true==true?false:true;
-->
true?false:(true==true)?false:true;
true?false:true?false:true;
true?false:(true?false:true);
true?false:false;
false;
赋值语句= 的优先级最低
==的优先级高于三目运算符
为了将左边的三目运算符算完,必须要现将后面的三目运算符算完,所以需要从右向左计算
Spring是一系列轻量级java EE框架的集合,正确
Spring提供了AOP方式的日志系统,不正确
Spring提供了AOP,但是没有提供日志系统,需要使用log4j等开源框架来利用AOP属性,实现日志系统
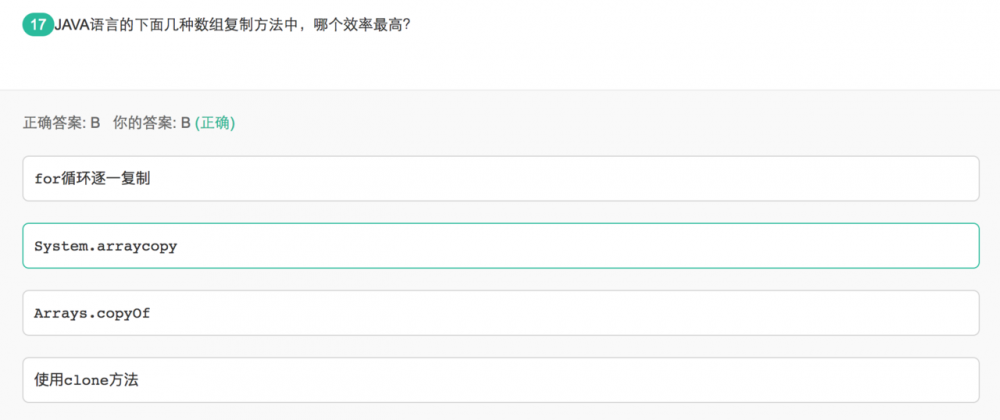
Arrays.copyOf 调用了System.arraycopy方法,所以System.arraycopy > Arrays.copyOf
System.arraycopy是native方法
clone 方法也是native方法
从评论区的反馈来看: 效率: System.arraycopy > clone > Arrays.copyOf


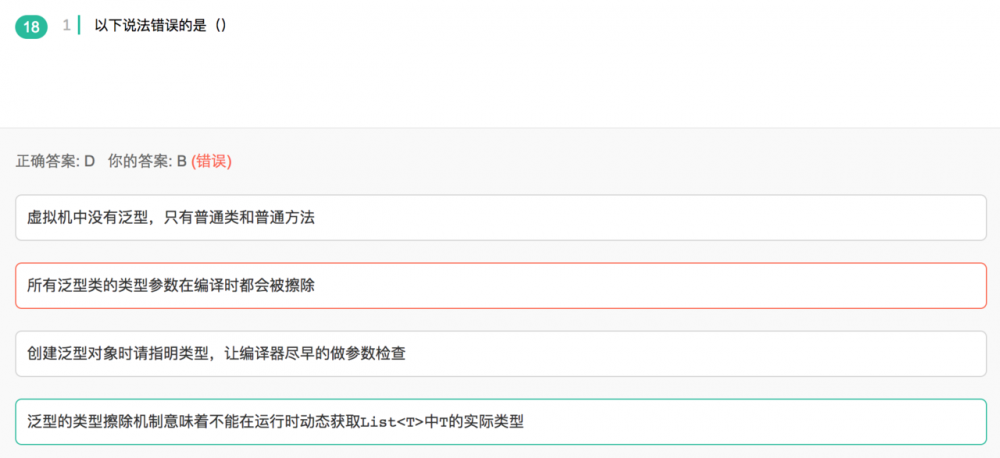
创建泛型的时候,尽可能早的指出泛型的类型,争取让编译器检查出错误,而不是在jvm运行的时候抛出类不匹配的异常
jvm理解泛型的方法:
1,虚拟机中没有泛型,只有普通类和普通方法,所有的泛型类,泛型方法的,在编译阶段就已经被处理成了普通类和普通方法(通过类型擦除进行处理),也就是讲泛型擦除成了Object或者边界类型(extend等)
2,即使是泛型,也可以在运行时,动态的(利用反射机制)动态的获取到泛型的实际类型



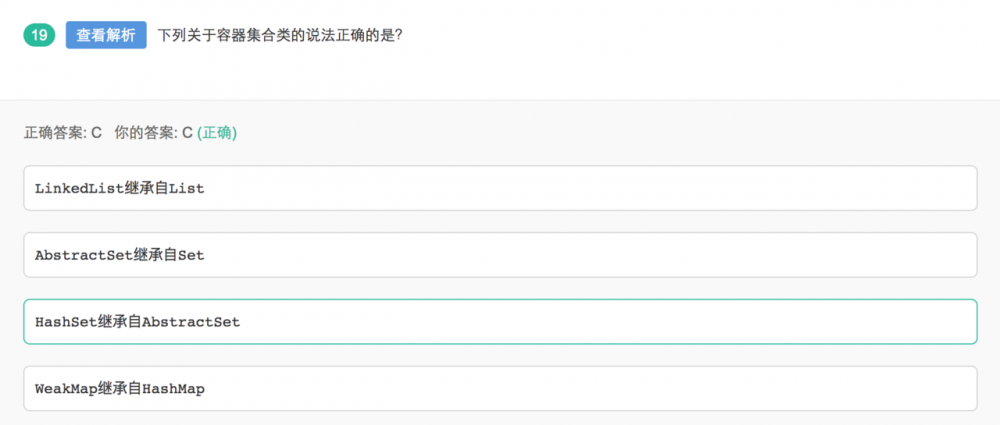

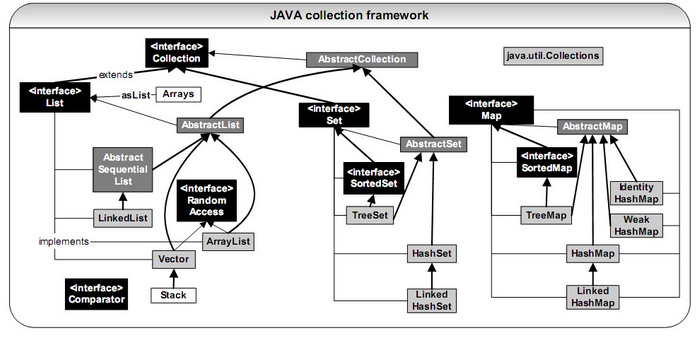
List和Set 接口继承了Collection接口,但是Map接口没有继承Collection接口
List包括ArrayList和Vector,Stack继承了Vector
Set包括Treeset,HashSet,LinkedHashSet,linkedHashSet继承了HashSet
Map包括TreeMap,HashMap,LinkedHashMap(继承了HashMap),WeakHashMap,IdentityHashMap, 其中,WeakHashMap和IdentityHashMap没有继承Hashmap,只是继承了AbstractMap,实现了Map接口,与HashMap一样(这一点与)

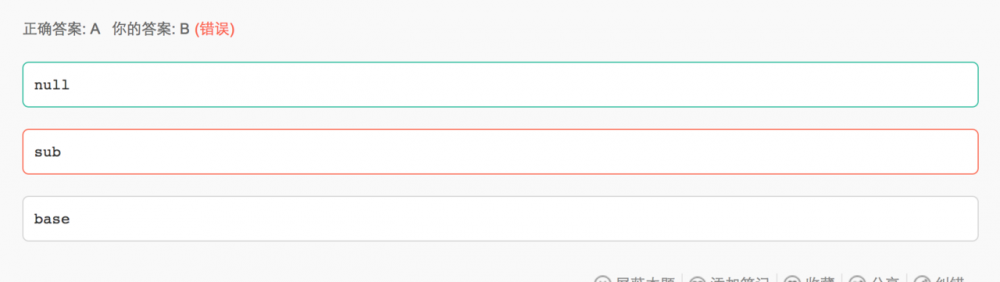
类的加载顺序:
1,父类的静态代码块,静态属性,但不包括静态方法
即:static{} + static T typeName;
2,子类的静态代码块,静态属性,但是不包括静态方法
3,父类的非静态代码块
4,父类的构造方法(构造方法晚于非静态代码块)
5,子类的非静态代码块
6,子类的构造方法(构造方法晚于非静态代码块)
代入到本题中,就是:
先执行Sub方法,然后执行Sub的基类Base的静态方法(没有),然后执行Sub的静态方法(没有),然后执行父类的非静态代码块(没有),然后执行父类的构造函数(里面有一个callName方法,因为sub中override了callName方法,所以父类的构造函数里面的callName方法,执行的是Sub类中的override的callName方法),然偶引用sub中callName中的baseName属性,但是此时还没有执行到Sub类中的private String basename="basename" ,所以此时baseName还保持在null的状态,会打印出null的值
synchronized与volatile的区别:
synchronize既可以保证原子性,又可以保证修改可见性,而volatile只能保证修改可见性
volatile的本质是告诉jvm,寄存器中的值是不可信的,直接去内存中取值 ,synchronized是锁定当前变量,同一时间只能有一个线程访问变量
volatile不会阻塞线程,而synchronized会阻塞线程
volatile标记的变量不会被编译器优化,而synchronized标记的变量会被线程优化
反射的主要作用:
运行时判断一个类所属的对象:isInstance();
运行时得到一个对象所属的类: getClass();
运行时构造一个类的对象: Class.forName("ClassName").newInstance();
运行时获取一个类的任意成员变量和方法,getFields,getMethods等
运行时调用任意类的任意方法
生成动态代理(需要特殊记)
集合中各种类的同步性:
List中,常见的LinkedList,ArrayList,都不是同步的
List中,不常见的Vector,以及继承与Vector的Stack,都是同步的
Set中,常见的HashSet,以及集成与HashSet的linkedHashset,都不是同步的
Set中,不常见的TreeSet,也是不同步的
Map中,常见的HashMap,linkedhashmap,都是不同步的
Map中,不常见的TreeMap,WeakHashMap,IdentityHashMap是不同步的
总结,常见的linkedlist,arraylist,hashset,linkedhashset,hashmap,linkedhashmap都是不同步的
常见的set,map都没有同步的,只有list中vector是同步的
只有vector和继承与vector的stack是同步的
StringBuffer是同步的,而StringBuilder是不同步的
HashMap不同步,但是Hashtable同步 (hashtable继承了Dictionary,实现了Map接口,属于map)
Properties继承与Hashtable,Properties也是同步的

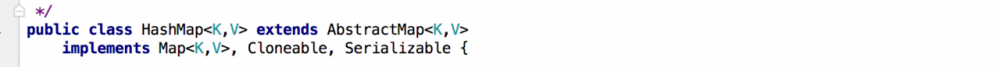
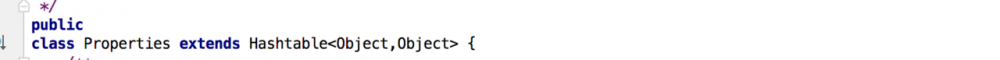
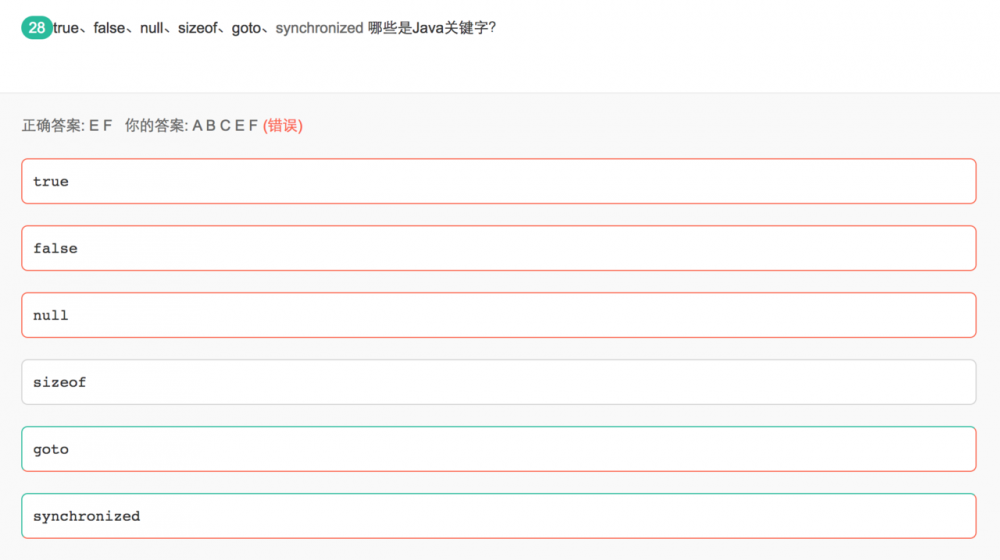
true,false,null,都是保留字,而不是关键字

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

