【golang】HashMap原理和实现
原理
我们都知道怎么使用goLang中的map来存储键值对类型的数据,但是它的内部实现是怎么样的?
其实map是一种HashMap,表面上看它只有键值对结构,实际上在存储键值对的过程中涉及到了数组和链表。HashMap之所以高效,是因为其结合了顺序存储(数组)和链式存储(链表)两种存储结构。数组是HashMap的主干,在数组下有有一个类型为链表的元素。
这是一个简单的HashMap的结构图:
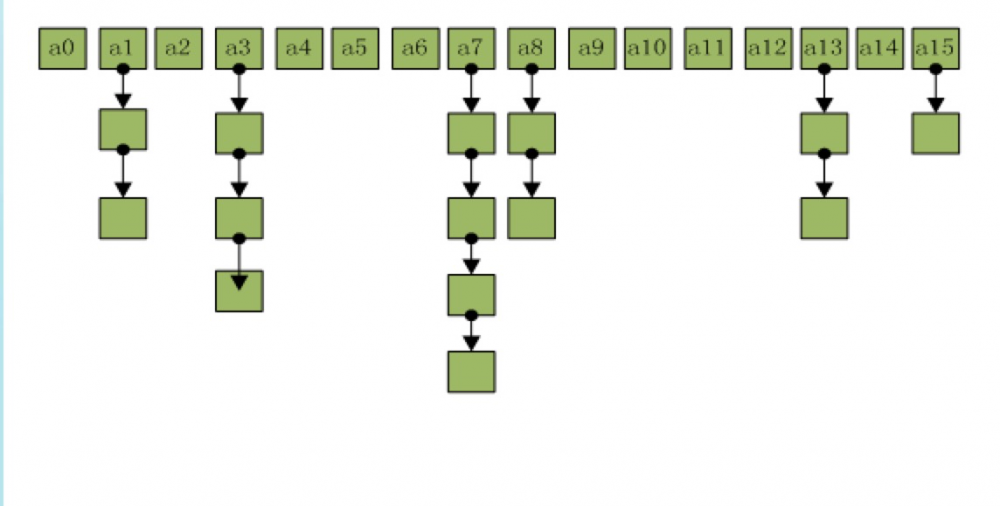
HashMap结构
当我们存储一个键值对时,HashMap会首先通过一个哈希函数将key转换为数组下标,真正的key-value是存储在该数组对应的链表里。
HashMap的数组往往是有限的,那当要存储的键值对很多数组不够或者两个键值对哈希运算后的值相同时,不就会有不同的键值对存储在同一个数组下吗?是的,这个就叫做哈希碰撞。当发生哈希碰撞时,键值对就会存储在该数组对应链表的下一个节点上。
尽管这样,HashMap的操作效率也是很高的。当不存在哈希碰撞时查找复杂度为O(1),存在哈希碰撞时复杂度为O(N)。所以,但从性能上讲HashMap中的链表出现越少,性能越好;当然,当存储的键值对非常多时,从存储的角度链表又能分担一定的压力。
代码实现
KVMap
首先,HashMap存储的是键值对,所以需要一个键值对类型。
//链表结构里数据的数据类型 键值对
type KV struct {
Key string
Value string
}
LinkNode
键值对又是主要存储在链表里的,所以需要一个链表类。
//链表结构
type LinkNode struct {
//节点数据
Data KV
//下一个节点
NextNode *LinkNode
}
//创建只有头结点的链表
func CreateLink() *LinkNode {
//头结点数据为空 是为了标识这个链表还没有存储键值对
var linkNode = &LinkNode{KV{"",""}, nil}
return linkNode
}
当发生哈希碰撞时,键值对会存储在新建的链表节点上。这里需要一个添加节点的功能,我们这里采用尾插法添加节点。
//尾插法添加节点,返回链表总长度
func (link *LinkNode) AddNode(data KV) int {
var count = 0
//找到当前链表尾节点
tail := link
for {
count += 1
if tail.NextNode == nil {
break
}else {
tail = tail.NextNode
}
}
var newNode = &LinkNode{data, nil}
tail.NextNode = newNode
return count+1
}
HashMap
接下来,就是猪脚HashMap登场了。
//HashMap木桶(数组)的个数
const BucketCount = 16
type HashMap struct {
//HashMap木桶
Buckets [BucketCount]*LinkNode
}
//创建HashMap
func CreateHashMap() *HashMap {
myMap := &HashMap{}
//为每个元素添加一个链表对象
for i := 0; i < BucketCount ; i++ {
myMap.Buckets[i] = CreateLink()
}
return myMap
}
我们需要一个哈希散列算法,将key转化为一个0-BucketCount的整数,作为存放它的数组的下标。这里这个散列算法,应尽可能随机地使新增的键值对均匀地分布在每个数组下。
一般像go的map和Java的HashMap都会有一个复杂的散列算法来达到这个目的,我们这里只是为了讲HashMap原理,暂且就用一个简单的方法来求出下标。
//自定义一个简单的散列算法,它可以将不同长度的key散列成0-BucketCount的整数
func HashCode(key string) int {
var sum = 0
for i := 0; i < len(key); i++ {
sum += int(key[i])
}
return (sum % BucketCount)
}
往HashMap里添加键值对
//添加键值对
func (myMap *HashMap)AddKeyValue(key string, value string) {
//1.将key散列成0-BucketCount的整数作为Map的数组下标
var mapIndex = HashCode(key)
//2.获取对应数组头结点
var link = myMap.Buckets[mapIndex]
//3.在此链表添加结点
if link.Data.Key == "" && link.NextNode == nil {
//如果当前链表只有一个节点,说明之前未有值插入 修改第一个节点的值 即未发生哈希碰撞
link.Data.Key = key
link.Data.Value = value
fmt.Printf("node key:%v add to buckets %d first node/n", key, mapIndex)
}else {
//发生哈希碰撞
index := link.AddNode(KV{key, value})
fmt.Printf("node key:%v add to buckets %d %dth node/n", key, mapIndex, index)
}
}
根据键从HashMap里取出对应的值
//按键取值
func (myMap *HashMap)GetValueForKey(key string) string {
//1.将key散列成0-BucketCount的整数作为Map的数组下标
var mapIndex = HashCode(key)
//2.获取对应数组头结点
var link = myMap.Buckets[mapIndex]
var value string
//遍历找到key对应的节点
head := link
for {
if head.Data.Key == key {
value = head.Data.Value
break
}else {
head = head.NextNode
}
}
return value
}
Main_test
package main
import (
"chaors.com/LearnGo/BlockchainCryptography/HashMap"
)
func main() {
myMap := HashMap.CreateHashMap()
myMap.AddKeyValue("001", "1")
myMap.AddKeyValue("002", "2")
myMap.AddKeyValue("003", "3")
myMap.AddKeyValue("004", "4")
myMap.AddKeyValue("005", "5")
myMap.AddKeyValue("006", "6")
myMap.AddKeyValue("007", "7")
myMap.AddKeyValue("008", "8")
myMap.AddKeyValue("009", "9")
myMap.AddKeyValue("010", "10")
myMap.AddKeyValue("011", "11")
myMap.AddKeyValue("012", "12")
myMap.AddKeyValue("013", "13")
myMap.AddKeyValue("012", "14")
myMap.AddKeyValue("015", "15")
}
RUN
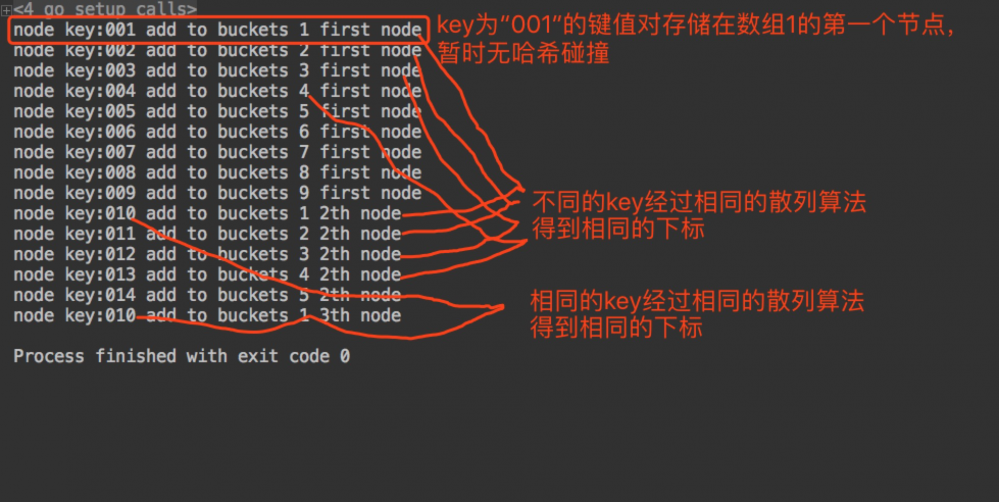
main_test.png
一个简单的HashMap就实现了,虽然我们的散列算法只是用了一个简单的转换算法,这对我们理解HashMap原理已经足够了。
更多技术文章请访问 chaors
.
.
.
.
互联网颠覆世界,区块链颠覆互联网!
--------------------------------------------------20180710 22:43
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

