利用Spring管理热加载的Groovy对象
原因
最近做的项目属于数据分析类型,要求数据分析功能做到快速上线。该项目当前使用的语言是Java + Groovy。 使用Groovy的原因很简单,因为 Groovy 脚本支持热加载功能。项目中,简单的数据分析工作,如一些统计、排序、过滤等,都放在Groovy里完成。需要上线新的数据分析功能时,只需要编写一个新的脚本,并热加载到JVM中即可。
现在希望将一些数据源访问、数据预处理的工作也放到 Groovy 脚本中完成,并具有这样的功能:项目在线上稳定运行期间,可以通过修改数据库中的脚本来完成新产品的上线。
解决方案
- PlanA: Java + 热加载
- PlanB: Groovy + 热加载
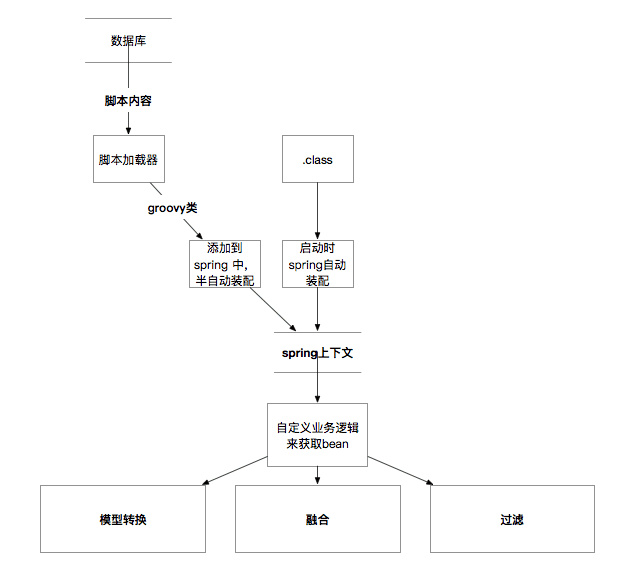
最终选择的方案是PlanB:让 Groovy 脚本需要具有访问数据源、调用rpc服务等等的能力。核心思路是利用Spring对Groovy脚本进行管理。
- Groovy 脚本保存在数据库中。定时任务不断轮训数据库检测Groovy脚本的更新时间,若有更新,则读取脚本内容,并解析为Class。
- 然后利用Spring提供的工具类BeanDefinitionBuilder,生成BeanDefinition。BeanDefinition中保存了Groovy脚本的meta信息,比如对其他类的依赖。
- 接着,将BeanDefinition放入Spring上下文ApplicationContext中,并调用初始化方法,对bean进行依赖注入。
- 最后,调用context.getBean(“xxx”)拿到该脚本。
当然,需要注意的细节有很多,比如服务降级、安全控制等,这里就不展开说了。
简单实现
Hello.groovy 这是保存在数据库中的Groovy脚本。
import org.springframework.beans.factory.annotation.Autowired
class Hello {
@Autowired
HelloService service;
HelloService getService() {
return service
}
def run() {
print(service.hello())
}
}
HelloService.java 这是项目中已经提供的服务,现实项目中可以是访问数据源等功能。
import org.springframework.stereotype.Component;
@Component
public class HelloService {
public String hello() {
return "now hello";
}
}
第一步,需要拿到Spring上下文 ApplicationContext。这个有很多种实现,比如继承ApplicationContextAware接口等。
第二步,获取到编译后的脚本,如下。
//从数据库中获取到脚本内容 String scriptContent = "......"; //编译 Class clazz = new GroovyClassLoader().parseClass(scriptContent);
第三步,将bean放入上下文,并进行依赖注入
BeanDefinitionBuilder beanDefinitionBuilder = BeanDefinitionBuilder.genericBeanDefinition(clazz);
BeanDefinition beanDefinition = beanDefinitionBuilder.getRawBeanDefinition();
context.getAutowireCapableBeanFactory().applyBeanPostProcessorsAfterInitialization(beanDefinition, "hello");
beanFactory.registerBeanDefinition("hello", beanDefinition);
第四步,从上下文中获取Groovy脚本
Hello hello = context.getBean("hello");
hello.run();
//console中应当输出下面内容,此时说明HelloService已经成功注入到groovy脚本中了
//now hello
参考资料
- Groovy 使 Spring 更出色,第 2 部分 - 在运行时改变应用程序的行为 - 用 Groovy 为 Spring 应用程序添加可动态刷新的 bean
- 动态注入 Bean 到 Spring 容器
- spring 动态注册 bean 王雁
- Spring 动态注册 bean 李佳明
正文到此结束
热门推荐








相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

