JVM系列(三) - JVM对象探秘
对于 JVM 运行时区域有了一定了解以后,本文将更进一步介绍虚拟机内存中的数据的细节信息。以 JVM 虚拟机( Hotspot )的内存区域 Java 堆为例,探讨 Java 堆是如何 创建对象 、如何 布局对象 以及如何 访问对象 的。
正文
(一). 对象的创建
说到对象的创建,首先让我们看看 Java 中提供的几种对象创建方式:
| Header | 解释 |
|---|---|
| 使用new关键字 | 调用了构造函数 |
| 使用Class的newInstance方法 | 调用了构造函数 |
| 使用Constructor类的newInstance方法 | 调用了构造函数 |
| 使用clone方法 | 没有调用构造函数 |
| 使用反序列化 | 没有调用构造函数 |
下面举例说明五种方式的具体操作方式:
Employee.java
public class Employee implements Cloneable, Serializable {
private static final long serialVersionUID = 1L;
private String name;
public Employee() {}
public Employee(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Employee other = (Employee) obj;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
@Override
public String toString() {
return "Employee [name=" + name + "]";
}
@Override
public Object clone() {
Object obj = null;
try {
obj = super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return obj;
}
}
复制代码
1. new关键字
这是最常见也是最简单的创建对象的方式了。通过这种方式,我们可以调用任意的构造函数(无参的和带参数的)。
Employee emp1 = new Employee(); 复制代码
Employee emp1 = new Employee(name); 复制代码
2. Class类的newInstance方法
我们也可以使用 Class 类的 newInstance 方法创建对象。这个 newInstance 方法调用 无参 的构造函数创建对象。
- 方式一:
Employee emp2 = (Employee) Class.forName("org.ostenant.jvm.instance.Employee").newInstance();
复制代码
- 方式二:
Employee emp2 = Employee.class.newInstance(); 复制代码
3. Constructor类的newInstance方法
和 Class 类的 newInstance 方法很像, java.lang.reflect.Constructor 类里也有一个 newInstance 方法可以创建对象。我们可以通过这个 newInstance 方法调用 有参数 的和 私有 的 构造函数 。其中, Constructor 可以从对应的 Class 类中获得。
Constructor<Employee> constructor = Employee.class.getConstructor(); Employee emp3 = constructor.newInstance(); 复制代码
这两种newInstance方法就是大家所说的反射。事实上Class的newInstance方法内部调用Constructor的newInstance方法。
4. Clone方法
无论何时我们调用一个对象的 clone 方法, JVM 都会创建一个新的对象,将前面对象的内容全部 拷贝 进去。用 clone 方法创建对象并不会调用任何构造函数。
为了使用 clone 方法,我们需要先实现 Cloneable 接口并实现其定义的 clone 方法。
Employee emp4 = (Employee) emp3.clone(); 复制代码
5. 反序列化
当我们 序列化 和 反序列化 一个对象, JVM 会给我们创建一个 单独 的对象。在反序列化时, JVM 创建对象并不会调用任何构造函数。
为了反序列化一个对象,我们需要让我们的类实现 Serializable 接口。
ByteArrayOutputStream out = new ByteArrayOutputStream(); ObjectOutputStream oos = new ObjectOutputStream(out); oos.writeObject(emp4); ByteArrayInputStream in = new ByteArrayInputStream(oos.toByteArray()); ObjectInputStream ois =new ObjectInputStream(in); Employee emp5 = (Employee) in.readObject(); 复制代码
本文以 new 关键字为例,讲述 JVM 堆中对象实例的创建过程如下:
-
当虚拟机遇到一条
new指令时,首先会检查这个 指令的参数 能否在 常量池 中定位一个 符号引用 。然后检查这个 符号引用 的类字节码对象是否 加载、解析和初始化 。如果没有,将执行对应的类加载过程。 -
类加载完成以后,虚拟机将会为新生对象 分配 内存区域,对象所需内存空间大小在类加载完成后就已确定。
-
内存分配完成以后,虚拟机将分配到的内存空间都初始化为 零值 。
-
虚拟机对对象进行一系列的 设置 ,如 所属类的元信息 、 对象的哈希码 、 对象GC分带年龄 、 线程持有的锁 、 偏向线程ID 等信息。这些信息存储在 对象头 (
Object Header)。
上述工作完成以后,从虚拟机的角度来说,一个新的对象已经产生了。然而,从 Java 程序的角度来说,对象创建才刚开始。
## (二). 对象的布局
HotSpot 虚拟机中,对象在内存中存储的布局可以分为三块区域: 对象头 ( Header )、 实例数据 ( Instance Data )和 对齐填充 ( Padding )。
对象头
在 HotSpot 虚拟机中,对象头有两部分信息组成: 运行时数据 和 类型指针 。
1. 运行时数据用于存储对象自身运行时的数据,如 哈希码 (hashCode)、 GC分带年龄 、 线程持有的锁 、 偏向线程ID 等信息。
这部分数据的长度在 32 位和 64 位的虚拟机(暂不考虑开启压缩指针的场景)中分别为 32 个和 64 个 Bit ,官方称它为 “Mark Word” 。
在32位的HotSpot虚拟机中对象未被锁定的状态下,Mark Word的32个Bit空间中的25Bit用于存储对象哈希码(HashCode),4Bit用于存储对象分代年龄,2Bits用于存储锁标志位,1Bit固定为0。
在其他状态(轻量级锁定、重量级锁定、GC标记、可偏向)下对象的存储内容如下表所示:
| 存储内容 | 标志位 | 状态 |
|---|---|---|
| 对象哈希码、对象分代年龄 | 01 | 未锁定 |
| 指向锁记录的指针 | 00 | 轻量级锁定 |
| 指向重量级锁的指针 | 10 | 膨胀(重量级锁定) |
| 空,不需要记录信息 | 11 | GC标记 |
| 偏向线程ID、偏向时间戳、对象分代年龄 | 01 | 可偏向 |
2. 类型指针指向实例对象的 类元数据 的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。
如果对象是一个 Java 数组,那在 对象头 中还必须有一块用于记录 数组长度 的数据。
实例数据
实例数据部分是对象真正存储的 有效信息 ,无论是从 父类继承 下来的还是该类 自身的 ,都需要记录下来,而这部分的 存储顺序 受虚拟机的 分配策略 和 定义的顺序 的影响。
默认分配策略:
long/double -> int/float -> short/char -> byte/boolean -> reference
如果设置了 -XX:FieldsAllocationStyle=0 (默认是 1 ),那么 引用类型 数据就会优先分配存储空间:
reference -> long/double -> int/float -> short/char -> byte/boolean
结论:
分配策略总是按照字节大小由大到小的顺序排列,相同字节大小的放在一起。
对齐填充
HotSpot 虚拟机要求每个对象的 起始地址 必须是 8 字节的整数倍,也就是对象的大小必须是 8 字节的 整数倍 。而 对象头部分 正好是 8 字节的倍数( 32 位为 1 倍, 64 位为 2 倍),因此,当对象实例数据部分没有对齐的时候,就需要通过 对齐填充 来补全。
(三). 对象的访问定位
Java 程序需要通过 JVM 栈上的引用访问堆中的具体对象。对象的访问方式取决于 JVM 虚拟机的实现。目前主流的访问方式有 句柄 和 直接指针 两种方式。
指针:指向对象,代表一个对象在内存中的起始地址。 句柄: 可以理解为指向指针的指针,维护着对象的指针。句柄不直接指向对象,而是指向对象的指针(句柄不发生变化,指向固定内存地址),再由对象的指针指向对象的真实内存地址。
1. 句柄
Java 堆中划分出一块内存来作为 句柄池 ,引用中存储对象的 句柄地址 ,而句柄中包含了 对象实例数据 与 对象类型数据 各自的 具体地址 信息,具体构造如下图所示:
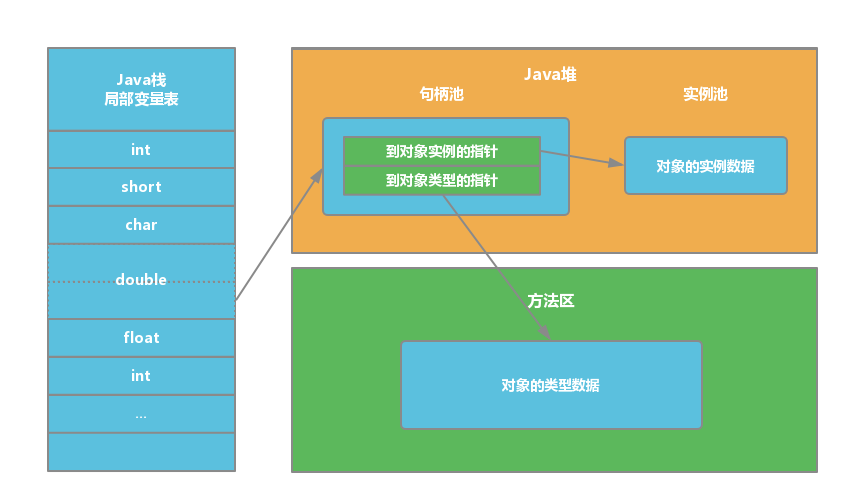
优势:引用中存储的是 稳定 的句柄地址,在对象被移动(垃圾收集时移动对象是非常普遍的行为)时只会改变 句柄中 的 实例数据指针 ,而 引用 本身不需要修改。
2. 直接指针
如果使用 直接指针 访问, 引用 中存储的直接就是 对象地址 ,那么 Java 堆对象内部的布局中就必须考虑如何放置访问 类型数据 的相关信息。
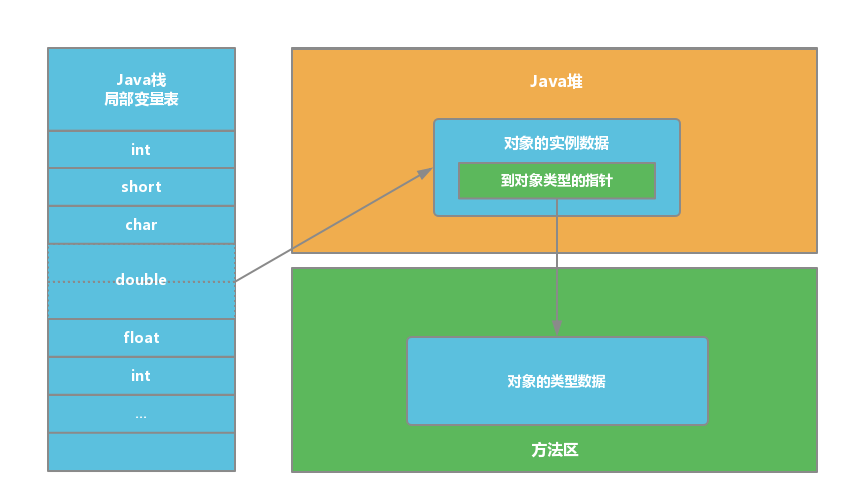
优势:速度更 快 ,节省了 一次指针定位 的时间开销。由于对象的访问在 Java 中非常频繁,因此这类开销积少成多后也是非常可观的执行成本。
参考
周志明,深入理解Java虚拟机:JVM高级特性与最佳实践,机械工业出版社
欢迎关注技术公众号: 零壹技术栈

本帐号将持续分享后端技术干货,包括虚拟机基础,多线程编程,高性能框架,异步、缓存和消息中间件,分布式和微服务,架构学习和进阶等学习资料和文章。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

