Elasticsearch Java Rest Client 上手指南(下)
High Level Rest Clent到现在还不是完成版。我试了一下,5.6版本的 RestHighLevelClient 就这么些API
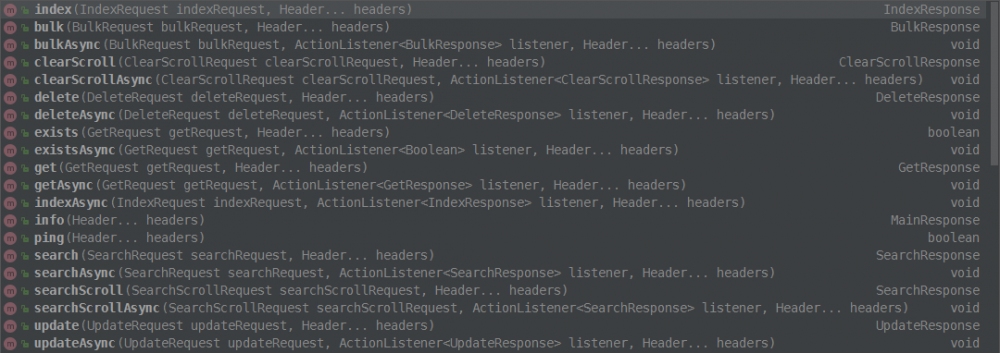 包含了基本的增删改查和批量操作
包含了基本的增删改查和批量操作
我翻了一下官方文档,凉凉。确实像官方文档说的那样,需要完善。虽然是High Level的Client,但是东西少的可怜。
增(index)删(delete)改(update)查(get)操作都是和Index,type,id严格绑定的。
不能跨Index操作
目前几乎所有的High Level Rest Clent的中文介绍全部是照搬ES的文档啊。我懒得抄,而且我司用的Elasticsearch 5.6
明显特性比版本6少了很多。所以,我倒是想填这个坑,但是太大了。还是拉倒吧。强烈建议直接去翻官方文档,这个API版本不同版本的差别很大,一定去看自己使用的版本!现有的中文博客参考价值有限。包括本篇。
-
Java High Level REST Client
-
Document APIs
0x1 基本增删改查
-
第一步创建高级Client
RestClient restClient = RestClient .builder(new HttpHost("localhost", 9200, "http")) .build(); RestHighLevelClient highLevelClient = new RestHighLevelClient(restClient); -
一次演示增删改查
//增, source 里对象创建方式可以是JSON字符串,或者Map,或者XContentBuilder 对象 IndexRequest indexRequest = new IndexRequest("指定index", "指定type", "指定ID") .source(builder); highLevelClient.index(indexRequest); //删 DeleteRequest deleteRequest = new DeleteRequest("指定index", "指定type", "指定ID"); highLevelClient.delete(deleteRequest); //改, source 里对象创建方式可以是JSON字符串,或者Map,或者XContentBuilder 对象 UpdateRequest updateRequest = new UpdateRequest("指定index", "指定type", "指定ID").doc(builder); highLevelClient.update(updateRequest); //查 GetRequest getRequest = new GetRequest("指定index", "指定type", "指定ID"); highLevelClient.get(getRequest);
- 以上四个方法都有一个 * Async的方法是异步回调的,只需添加ActionListener对象即可
- Get查询不是唯一的查询方法,还有SearchRequest等, 但是这个GetRequest只支持单Index操作
- Get操作支持限定查询的字段,传入fetchSourceContext对象即可
- Update 操作演示的并不是全量替换,而是和现有文档作合并,除了doc操作还有使用Groovy script操作。
- upsert类似update操作,不过如果文档不存在会作为新的doc存入ES
0x2 Bulk批量操作
其实就是把一大堆IndexRequest, UpdateRequest, DeleteRequest操作放在一起。
所以缺点就是必须指定Index,否则操作没戏。
简单示例
BulkRequest request = new BulkRequest();
request.add(new IndexRequest("指定index", "指定type", "指定ID_1").source(XContentType.JSON,"field", "foo"));
request.add(new DeleteRequest("指定index", "指定type", "指定ID_2"));
request.add(new UpdateRequest("指定index", "指定type", "指定ID_3") .doc(XContentType.JSON,"other", "test"));
BulkResponse bulkResponse = client.bulk(request);
for (BulkItemResponse bulkItemResponse : bulkResponse) {
if (bulkItemResponse.isFailed()) {
BulkItemResponse.Failure failure = bulkItemResponse.getFailure();
continue;
}
DocWriteResponse itemResponse = bulkItemResponse.getResponse();
if (bulkItemResponse.getOpType() == DocWriteRequest.OpType.INDEX
|| bulkItemResponse.getOpType() == DocWriteRequest.OpType.CREATE) {
IndexResponse indexResponse = (IndexResponse) itemResponse;
} else if (bulkItemResponse.getOpType() == DocWriteRequest.OpType.UPDATE) {
UpdateResponse updateResponse = (UpdateResponse) itemResponse;
} else if (bulkItemResponse.getOpType() == DocWriteRequest.OpType.DELETE) {
DeleteResponse deleteResponse = (DeleteResponse) itemResponse;
}
}
0x3 SearchRequest高级查询
支持多文档查询、聚合操作。可以完全取代GetRequest。
// 创建 SearchRequest searchRequest = new SearchRequest(); SearchSourceBuilder builder = new SearchSourceBuilder(); searchSourceBuilder.query(xxxQuery); searchRequest.source(builder);
可以在创建的时候指定index, SearchRequest searchRequest = new SearchRequest("some_index*"); ,支持带*号的模糊匹配
当然,这并不是最厉害的地方,最NB的地方是,支持QueryBuilder,兼容之前TransportClient的代码
-
我自己写的跨Index模糊查询
SearchRequest searchRequest = new SearchRequest("gdp_tops*"); SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); sourceBuilder.query(QueryBuilders.termQuery("city", "北京市")); sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS)); searchRequest.source(sourceBuilder); try { SearchResponse response = highLevelClient.search(searchRequest); Arrays.stream(response.getHits().getHits()) .forEach(i -> { System.out.println(i.getIndex()); System.out.println(i.getSource()); System.out.println(i.getType()); }); System.out.println(response.getHits().totalHits); } catch (IOException e) { e.printStackTrace(); } -
官方给出的聚合查询
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); TermsAggregationBuilder aggregation = AggregationBuilders.terms("by_company") .field("company.keyword"); aggregation.subAggregation(AggregationBuilders.avg("average_age") .field("age")); searchSourceBuilder.aggregation(aggregation); -
当然还支持异步查询
官方示例
client.searchAsync(searchRequest, new ActionListener<SearchResponse>() { @Override public void onResponse(SearchResponse searchResponse){ } @Override public void onFailure(Exception e){ } }); -
查询结果处理
查询结束后会得到一个SearchResponse对象,可以拿到查询状态,消耗时间,查询到的总条目数等参数,具体结果操作
SearchHit[] searchHits = hits.getHits(); for (SearchHit hit : searchHits) { // 结果的Index String index = hit.getIndex(); // 结果的type String type = hit.getType(); // 结果的ID String id = hit.getId(); // 结果的评分 float score = hit.getScore(); // 查询的结果 JSON字符串形式 String sourceAsString = hit.getSourceAsString(); // 查询的结果 Map的形式 Map<String, Object> sourceAsMap = hit.getSourceAsMap(); // Document的title String documentTitle = (String) sourceAsMap.get("title"); // 结果中的某个List List<Object> users = (List<Object>) sourceAsMap.get("user"); // 结果中的某个Map Map<String, Object> innerObject = (Map<String, Object>) sourceAsMap.get("innerObject"); } -
聚合查询
前面演示的是正常查询,聚合查询官方文档也有展示
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); TermsAggregationBuilder aggregation = AggregationBuilders.terms("by_company") .field("company.keyword"); aggregation.subAggregation(AggregationBuilders.avg("average_age") .field("age")); searchSourceBuilder.aggregation(aggregation);
和query查询一样, searchSourceBuilder 使用 aggregation() 方法即可
查询到的结果处理也跟普通查询类似,处理一下Bucket就可以展示到接口了
Aggregations aggregations = searchResponse.getAggregations();
Terms byCompanyAggregation = aggregations.get("by_company");
Bucket elasticBucket = byCompanyAggregation.getBucketByKey("Elastic");
Avg averageAge = elasticBucket.getAggregations().get("average_age");
double avg = averageAge.getValue();
0x4 分页和滚动搜索
有时候结果需要分页查询,推荐使用 searchSourceBuilder 的
sourceBuilder.from(0); sourceBuilder.size(5);
有时候需要查询的数据太多,可以考虑使用 SearchRequest.scroll() 方法拿到 scrollId ;之后再使用 SearchScrollRequest
其用法如下:
SearchRequest searchRequest = new SearchRequest("posts");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(matchQuery("title", "Elasticsearch"));
searchSourceBuilder.size(size);
searchRequest.source(searchSourceBuilder);
searchRequest.scroll(TimeValue.timeValueMinutes(1L));
SearchResponse searchResponse = client.search(searchRequest);
String scrollId = searchResponse.getScrollId();
SearchScrollRequest scrollRequest = new SearchScrollRequest(scrollId);
scrollRequest.scroll(TimeValue.timeValueSeconds(30));
SearchResponse searchScrollResponse = client.searchScroll(scrollRequest);
scrollId = searchScrollResponse.getScrollId();
hits = searchScrollResponse.getHits();
assertEquals(3, hits.getTotalHits());
assertEquals(1, hits.getHits().length);
assertNotNull(scrollId);
Scroll查询的使用场景是密集且前后有关联的查询。如果只是一般的分页,可以使用size from来处理
官方还列出了查询构造的方式。可以根据自己的需要,详细翻阅。
需要了解基础的,请查看: Elasticsearch Java Rest Client 上手指南(上)
转载请注明出处: https://micorochio.github.io/2018/07/22/elasticsearch_rest_high_level_client/
如有错误,请不吝指正。谢谢
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

