ConcurrentHashMap 的 size 方法原理分析
作者 | 许光明

杏仁后端工程师。少青年程序员,关注服务端技术和农药。
前言
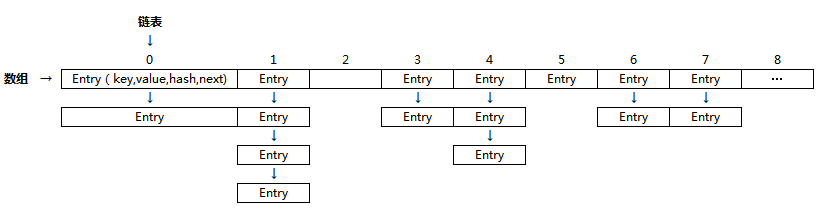
JAVA 语言提供了大量丰富的集合, 比如 List, Set, Map 等。其中 Map 是一个常用的一个数据结构,HashMap 是基于 Hash 算法实现 Map 接口而被广泛使用的集类。HashMap 里面是一个数组,然后数组中每个元素是一个单向链表。但是 HashMap 并不是线程安全的, 在多线程场景下使用存在并发和死循环问题。HashMap 结构如图所示:
线程安全的解决方案
线程安全的 Map 的实现有 HashTable 和 ConcurrentHashMap 等。HashTable 对集合读写操作通过 Synchronized 同步保障线程安全, 整个集合只有一把锁, 对集合的操作只能串行执行,性能不高。ConcurrentHashMap 是另一个线程安全的 Map, 通常来说他的性能优于 HashTable。 ConcurrentHashMap 的实现在 JDK1.7 和 JDK 1.8 有所不同。
在 JDK1.7 版本中,ConcurrentHashMap 的数据结构是由一个 Segment 数组和多个 HashEntry 组成。简单理解就是ConcurrentHashMap 是一个 Segment 数组,Segment 通过继承 ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 Segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。

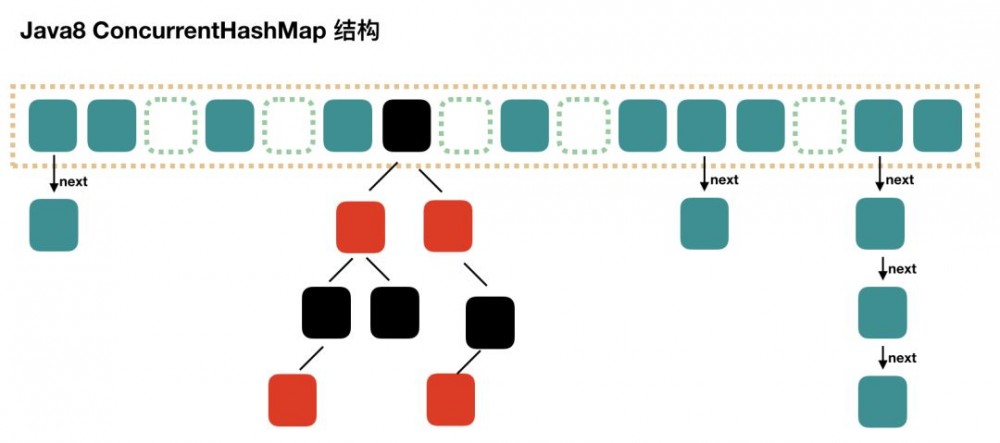
JDK1.8 的实现已经摒弃了 Segment 的概念,而是直接用 Node 数组 + 链表 + 红黑树的数据结构来实现,并发控制使用 Synchronized 和 CAS 来操作,整个看起来就像是优化过且线程安全的 HashMap,虽然在 JDK1.8 中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本。 通过 HashMap 查找的时候,根据 hash 值能够快速定位到数组的具体下标,如果发生 Hash 碰撞,需要顺着链表一个个比较下去才能找到我们需要的,时间复杂度取决于链表的长度,为 O(n)。为了降低这部分的开销,在 Java8 中,当链表中的元素超过了 8 个以后,会将链表转换为红黑树,在这些位置进行查找的时候可以降低时间复杂度为 O(logN)。
如何计算 ConcurrentHashMap Size
由上面分析可知,ConcurrentHashMap 更适合作为线程安全的 Map。在实际的项目过程中,我们通常需要获取集合类的长度, 那么计算 ConcurrentHashMap 的元素大小就是一个有趣的问题,因为他是并发操作的,就是在你计算 size 的时候,它还在并发的插入数据,可能会导致你计算出来的 size 和你实际的 size 有差距。本文主要分析下 JDK1.8 的实现。 关于 JDK1.7 简单提一下。
在 JDK1.7 中,第一种方案他会使用不加锁的模式去尝试多次计算 ConcurrentHashMap 的 size,最多三次,比较前后两次计算的结果,结果一致就认为当前没有元素加入,计算的结果是准确的。 第二种方案是如果第一种方案不符合,他就会给每个 Segment 加上锁,然后计算 ConcurrentHashMap 的 size 返回。其源码实现:
public int size() {
final Segment<K,V>[] segments = this.segments;
int size;
boolean overflow; // true if size overflows 32 bits
long sum; // sum of modCounts
long last = 0L; // previous sum
int retries = -1; // first iteration isn't retry
try {
for (;;) {
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
if (sum == last)
break;
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return overflow ? Integer.MAX_VALUE : size;
}
JDK1.8 实现相比 JDK 1.7 简单很多,只有一种方案,我们直接看 size() 代码:
public int size() {
long n = sumCount();
return ((n < 0L) ? 0 :
(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE : (int)n);
}
最大值是 Integer 类型的最大值,但是 Map 的 size 可能超过 MAX_VALUE, 所以还有一个方法 mappingCount() ,JDK 的建议使用 mappingCount() 而不是 size() 。 mappingCount() 的代码如下:
public long mappingCount() {
long n = sumCount();
return (n < 0L) ? 0L : n; // ignore transient negative values
}
以上可以看出,无论是 size() 还是 mappingCount() , 计算大小的核心方法都是 sumCount() 。 sumCount() 的代码如下:
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
分析一下 sumCount() 代码。ConcurrentHashMap 提供了 baseCount、counterCells 两个辅助变量和一个 CounterCell 辅助内部类。 sumCount() 就是迭代 counterCells 来统计 sum 的过程。 put 操作时,肯定会影响 size() ,在 put() 方法最后会调用 addCount() 方法。
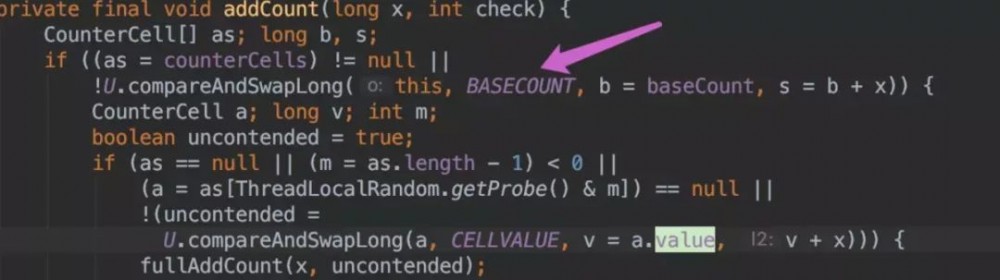
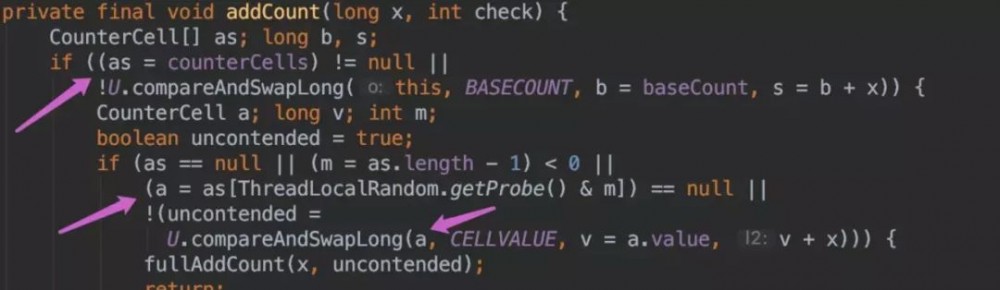
addCount() 代码如下:
-
如果 counterCells == null, 则对 baseCount 做 CAS 自增操作。
-
如果并发导致 baseCount CAS 失败了使用 counterCells。
-
如果counterCells CAS 失败了,在 fullAddCount 方法中,会继续死循环操作,直到成功。
然后,CounterCell 这个类到底是什么?我们会发现它使用了 @sun.misc.Contended 标记的类,内部包含一个 volatile 变量。@sun.misc.Contended 这个注解标识着这个类防止需要防止 "伪共享"。那么,什么又是伪共享呢?
缓存系统中是以缓存行(cache line)为单位存储的。缓存行是2的整数幂个连续字节,一般为32-256个字节。最常见的缓存行大小是64个字节。当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。
CounterCell 代码如下:
@sun.misc.Contended static final class CounterCell {
volatile long value;
CounterCell(long x) { value = x; }
}
总结
-
JDK1.7 和 JDK1.8 对 size 的计算是不一样的。 1.7 中是先不加锁计算三次,如果三次结果不一样在加锁。
-
JDK1.8 size 是通过对 baseCount 和 counterCell 进行 CAS 计算,最终通过 baseCount 和 遍历 CounterCell 数组得出 size。
-
JDK 8 推荐使用mappingCount 方法,因为这个方法的返回值是 long 类型,不会因为 size 方法是 int 类型限制最大值。
全文完
以下文章您可能也会感兴趣:
-
从 ThreadLocal 的实现看散列算法
-
理清 Promise 的状态及使用
-
逻辑思维:理清思路,表达自己的技巧
-
Actor 模型及 Akka 简介
-
中文房间之争:浅论到底什么是智能
-
从零搭建一个基于 lstio 的服务网格
-
容器管理利器:Web Terminal 简介
-
单元测试 -- 工程师 Style 的测试方法
-
理解 RabbitMQ Exchange
-
iOS 下的图片处理与性能优化
-
不懂产品的研发,不是好 CTO
-
技术选型的艺术
我们正在招聘 Java 工程师,欢迎有兴趣的同学投递简历到 rd-hr@xingren.com 。

杏仁技术站
长按左侧二维码关注我们,这里有一群热血青年期待着与您相会。
正文到此结束
- 本文标签: tab 安全 CTO volatile 文章 服务端 HashTable 源码 房间 时间 二维码 http MQ HashMap 测试 产品 代码 list 统计 IO 集合类 并发 web 线程 多线程 value src 图片 原理分析 retry java 管理 遍历 同步 cache 性能优化 单元测试 rmi https 数据 程序员 总结 IOS 工程师 缓存 mina UI App final kk 模型 synchronized node map 智能 锁 招聘 rabbitmq ConcurrentHashMap
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

