分布式存储系统关键问题
(一)关键问题
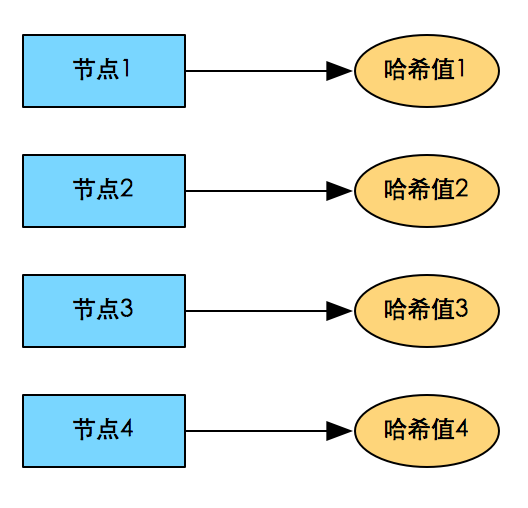 关键:找出一个散列特性很好的哈希函数
问题:增加、减少服务器时的大量数据迁移
解决:1)将<哈希值,服务器>元数据存储在元数据服务器中;2)一致性哈希
一致性哈希: 给系统每个节点分配一个随机token,这些token构成一个hash环。执行数据存放操作时,先计算key的hash值,然后存放到顺时针方向第一个大于或者等于该hash值的token所在节点。
关键:找出一个散列特性很好的哈希函数
问题:增加、减少服务器时的大量数据迁移
解决:1)将<哈希值,服务器>元数据存储在元数据服务器中;2)一致性哈希
一致性哈希: 给系统每个节点分配一个随机token,这些token构成一个hash环。执行数据存放操作时,先计算key的hash值,然后存放到顺时针方向第一个大于或者等于该hash值的token所在节点。
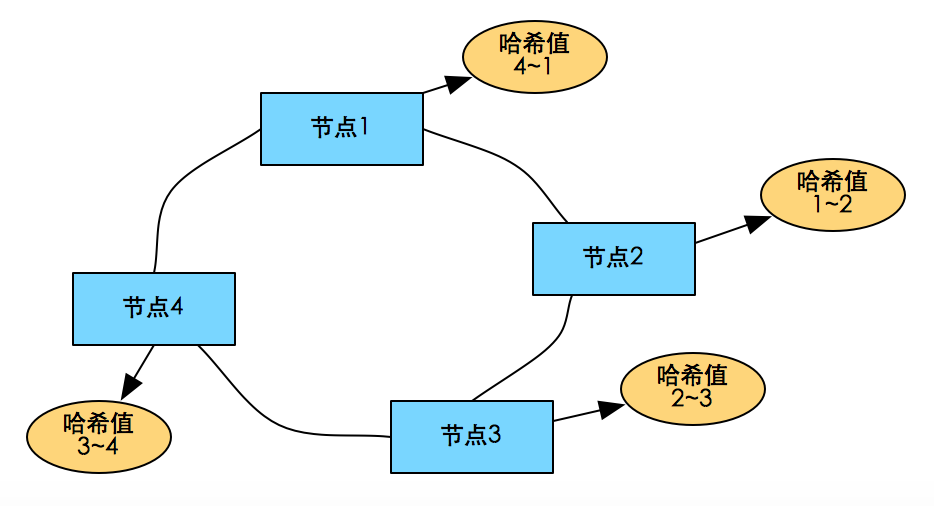 关键:哈希值变成了一个范围,每个物理节点上存储的数据是哈希值处于前一段范围的数据。
优点: 节点增加/删除时只会影响到在hash环中相邻的节点,而对其他节点没影响。
维护每台机器在哈希环中的位置方式:1) 记录它前一个&后一个节点的位置信息,每次查找可能遍历整个哈希环所有服务器;2) O(logN)位置信息,查找的时间复杂度为O(logN);3) 每台服务器维护整个集群中所有服务器的位置信息,查找服务器的时间复杂度为O(1)
虚拟节点:将哈希取模的模数取得很大,就会得到更多的哈希值,这个哈希值成为逻辑节点,一个物理机器可以根据自己的能力选择若干个逻辑节点的存储节点。
关键:哈希值变成了一个范围,每个物理节点上存储的数据是哈希值处于前一段范围的数据。
优点: 节点增加/删除时只会影响到在hash环中相邻的节点,而对其他节点没影响。
维护每台机器在哈希环中的位置方式:1) 记录它前一个&后一个节点的位置信息,每次查找可能遍历整个哈希环所有服务器;2) O(logN)位置信息,查找的时间复杂度为O(logN);3) 每台服务器维护整个集群中所有服务器的位置信息,查找服务器的时间复杂度为O(1)
虚拟节点:将哈希取模的模数取得很大,就会得到更多的哈希值,这个哈希值成为逻辑节点,一个物理机器可以根据自己的能力选择若干个逻辑节点的存储节点。
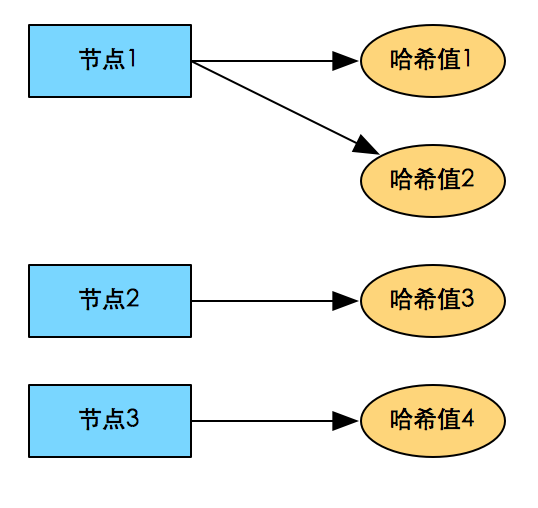 优点:将传统哈希的一(物理节点)对一(哈希值)的分布变成了一(物理节点)对多(哈希值)的分布。可以根据物理节点的能力调整数据的分布。
2)顺序分布 => 顺序扫描
表格上的数据按照主键整体有序
优点:将传统哈希的一(物理节点)对一(哈希值)的分布变成了一(物理节点)对多(哈希值)的分布。可以根据物理节点的能力调整数据的分布。
2)顺序分布 => 顺序扫描
表格上的数据按照主键整体有序
- 数据分布
关键:找出一个散列特性很好的哈希函数
问题:增加、减少服务器时的大量数据迁移
解决:1)将<哈希值,服务器>元数据存储在元数据服务器中;2)一致性哈希
一致性哈希: 给系统每个节点分配一个随机token,这些token构成一个hash环。执行数据存放操作时,先计算key的hash值,然后存放到顺时针方向第一个大于或者等于该hash值的token所在节点。
关键:哈希值变成了一个范围,每个物理节点上存储的数据是哈希值处于前一段范围的数据。
优点: 节点增加/删除时只会影响到在hash环中相邻的节点,而对其他节点没影响。
维护每台机器在哈希环中的位置方式:1) 记录它前一个&后一个节点的位置信息,每次查找可能遍历整个哈希环所有服务器;2) O(logN)位置信息,查找的时间复杂度为O(logN);3) 每台服务器维护整个集群中所有服务器的位置信息,查找服务器的时间复杂度为O(1)
虚拟节点:将哈希取模的模数取得很大,就会得到更多的哈希值,这个哈希值成为逻辑节点,一个物理机器可以根据自己的能力选择若干个逻辑节点的存储节点。
优点:将传统哈希的一(物理节点)对一(哈希值)的分布变成了一(物理节点)对多(哈希值)的分布。可以根据物理节点的能力调整数据的分布。
2)顺序分布 => 顺序扫描
表格上的数据按照主键整体有序
- 负载均衡
- 复制&多备份
- 数据一致性
- 容错
- 可扩展性
正文到此结束
- 本文标签: 分布式文件系统
- 版权声明: 本文由HARRIES原创发布,转载请遵循《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

