走进科学之揭开神秘的 “零拷贝”
前言
"零拷贝"这三个字,想必大家多多少少都有听过吧,这个技术在各种开源组件中都使用了,比如kafka,rocketmq,netty,nginx等等开源框架都在其中引用了这项技术。所以今天想和大家分享一下有关于零拷贝的一些知识。
计算机中数据传输
在介绍零拷贝之前我想说下在计算机系统中数据传输的方式。数据传输系统的发展,为了写这一部分又祭出了我尘封多年的计算机组成原理:

早期阶段:
分散连接,串行工作,程序查询。 在这个阶段,CPU就像个保姆一样,需要手把手的把数据从I/O接口从读出然后再送给主存。  这个阶段具体流程是:
这个阶段具体流程是:
-
CPU主动启动I/O设备
-
然后CPU一直问I/O设备老铁你准备好了吗,注意这里是一直询问。
-
如果I/O设备告诉了CPU说:我准备好了。CPU就从I/O接口中读数据。
-
然后CPU又继续把这个数据传给主存,就像快递员一样。
这种效率很低数据传输过程一直占据着CPU,CPU不能做其他更有意义的事。
接口模块和DMA阶段
这一部分介绍的也是我们后面具体
接口模块
在冯诺依曼结构中,每个部件之间均有单独连线,不仅先多,而且导致扩展I/O设备很不容易,我们上面的早期阶段就是这个体系,叫作分散连接。扩展一个I/O设备得连接很多线。所以引入了总线连接方式,将多个设备连接在同一组总线上,构成设备之间的公共传输通道。  这个也是现在我们家用电脑或者一些小型计算器的数据交换结构。
这个也是现在我们家用电脑或者一些小型计算器的数据交换结构。
在这种模式下数据交换采用程序中断的方式,我们上面知道我们启动I/O设备之后一直在轮询问I/O设备是否准备好,要是把这个阶段去掉了就好了,程序中断很好的实现了我们的夙愿:
-
CPU主动启动I/O设备。
-
CPU启动之后不需要再问I/O,开始做其他事,类似异步化。
-
I/O准备好了之后,通过总线中断告诉CPU我已经准备好了。
-
CPU进行读取数据,传输给主存中。
DMA
虽然上面的方式虽然提高了CPU的利用率,但是在中断的时候CPU一样是被占用的,为了进一步解决CPU占用,又引入了DMA方式,在DMA方式中,主存和I/O设备之间有一条数据通路,这下主存和I/O设备之间交换数据时,就不需要再次中断CPU。
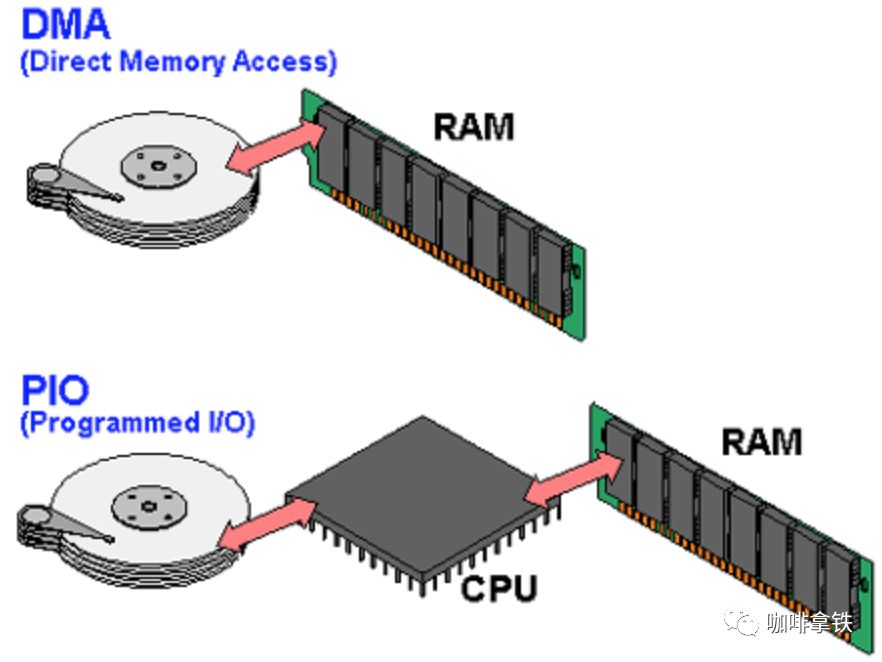
一般来说我们只需要关注DMA和中断两种即可,下面介绍的都是用来适合大型计算机的一些,这里只说简单的过一下:
具有通道结构的阶段
在小型计算机中采用DMA方式可以实现高速I/O设备与主机之间组成数据的交换,但在大中型计算机中,I/O配置繁多,数据传送平凡,若采用DMA方式会出现一系列问题。
-
每台I/O设备都配置专用额DMA接口,不仅增加了硬件成本,而且解决DMA和CPU访问冲突问题,会使控制变得十分复杂。
-
CPU需要对众多的DMA接口进行管理,同样会影响工作效率。
所以引入了通道,通道用来管理I/O设备以及主存与I/O设备之间交换信息的部件,可以视为一种具有特殊功能的处理器。它是从属于CPU的一个专用处理器,CPU不直接参与管理,故提高了CPU的资源利用率
具有I/O处理机的阶段
输入输出系统发展到第四阶段,出现了I/O处理机。I/O处理机又称为外围处理机,它独立于主机工作,既可以完成I/O通道要完成的I/O控制,又完成格式处理,纠错等操作。具有I/O处理机的输出系统与CPU工作的并行度更高,这说明I.O系统对主机来说具有更大的独立性。
小结
我们可以看到数据传输进化的目标是一直在减少CPU占有,提高CPU的资源利用率。
数据拷贝
先介绍一下今天我们的需求,在磁盘中有个文件,现在需要通过网络传输出去。 如果是你应该怎么做?通过上面的一些介绍,相信你心中应该有些想法了吧。
传统拷贝
如果我们用Java代码实现的话用我们会有如下的的实现:伪代码参考如下:
这是我们传统的拷贝方式具体的数据流转图如下,PS:这里不考虑Java中传输数据时需要先将堆中的数据拷贝到直接内存中。 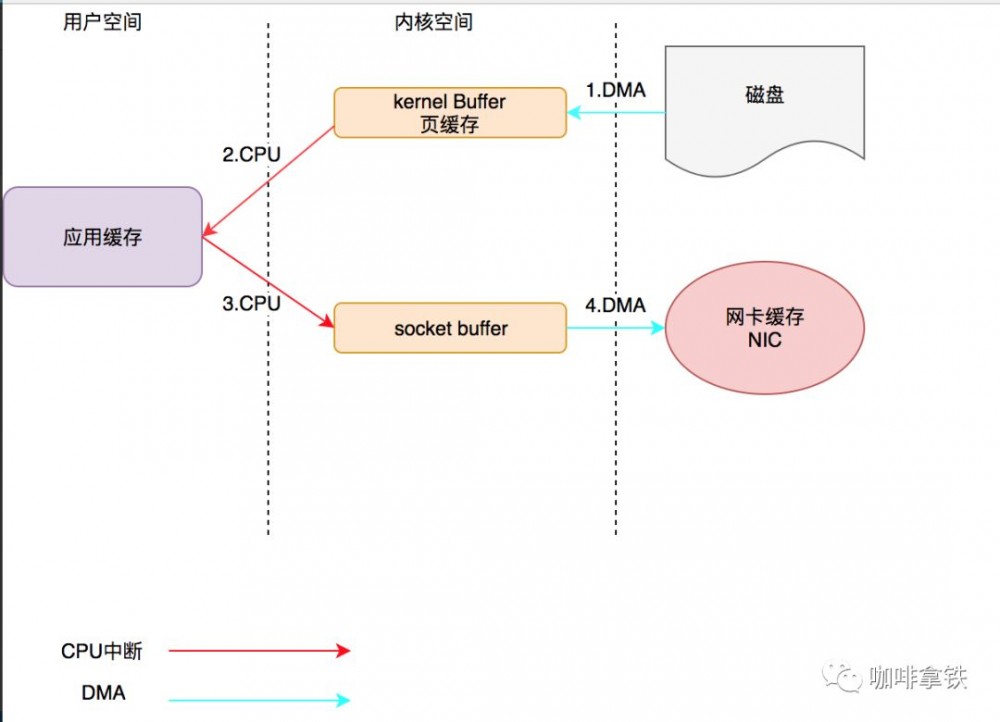
可以看见我们总管需要经历四个阶段,2次DMA,2次CPU中断,总共四次拷贝,有四次上下文切换,并且会占用两次CPU。
-
CPU发指令给I/O设备的DMA,由DMA将我们磁盘中的数据传输到内核空间的内核buffer。
-
第二阶段触发我们的CPU中断,CPU开始将将数据从kernel buffer拷贝至我们的应用缓存
-
CPU将数据从应用缓存拷贝到内核中的socket buffer.
-
DMA将数据从socket buffer中的数据拷贝到网卡缓存。
优点:开发成本低,适合一些对性能要求不高的,比如一些什么管理系统这种我觉得就应该够了
缺点:多次上下文切换,占用多次CPU,性能比较低。
sendFile实现零拷贝
上面是零拷贝呢?在wiki中的定位:通常是指计算机在网络上发送文件时,不需要将文件内容拷贝到用户空间(User Space)而直接在内核空间(Kernel Space)中传输到网络的方式。
在java NIO中FileChannal.transferTo()实现了操作系统的sendFile,我们可以同下面伪代码完成上面需求:
我们通过java.nio中的channel替代了我们上面的socket和fileInputStream,从而完成了我们的零拷贝。
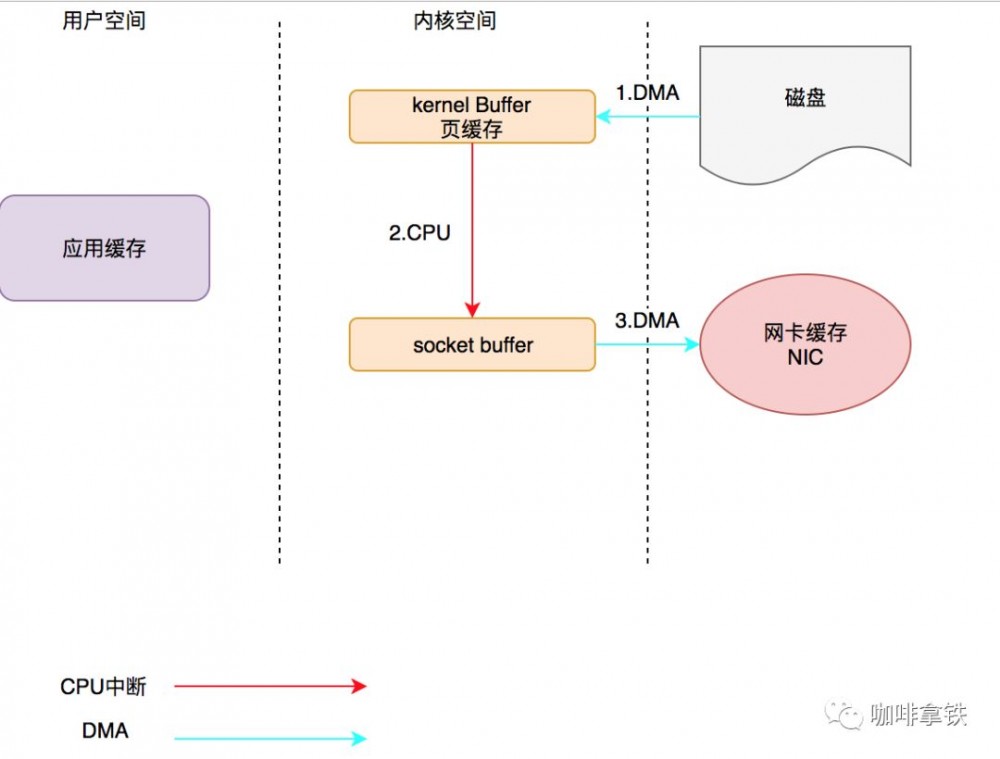
上面具体过程如下:
-
调用sendfie(),CPU下发指令叫DMA将磁盘数据拷贝到内核buffer中。
-
DMA拷贝完成发出中断请求,进行CPU拷贝,拷贝到socket buffer中。sendFile调用完成返回。 3.DMA将socket buffer拷贝至网卡buffer。
可以看见我们根本没有把数据复制到我们的应用缓存中,所以这种方式就是零拷贝。但是这种方式依然很蛋疼,虽然减少到了只有三次数据拷贝,但是还是需要CPU中断复制数据。为啥呢?因为DMA需要知道内存地址我才能发送数据啊。所以在Linux2.4内核中做了改进,将Kernel buffer中对应的数据描述信息(内存地址,偏移量)记录到相应的socket缓冲区当中。 最终形成了下面的过程: 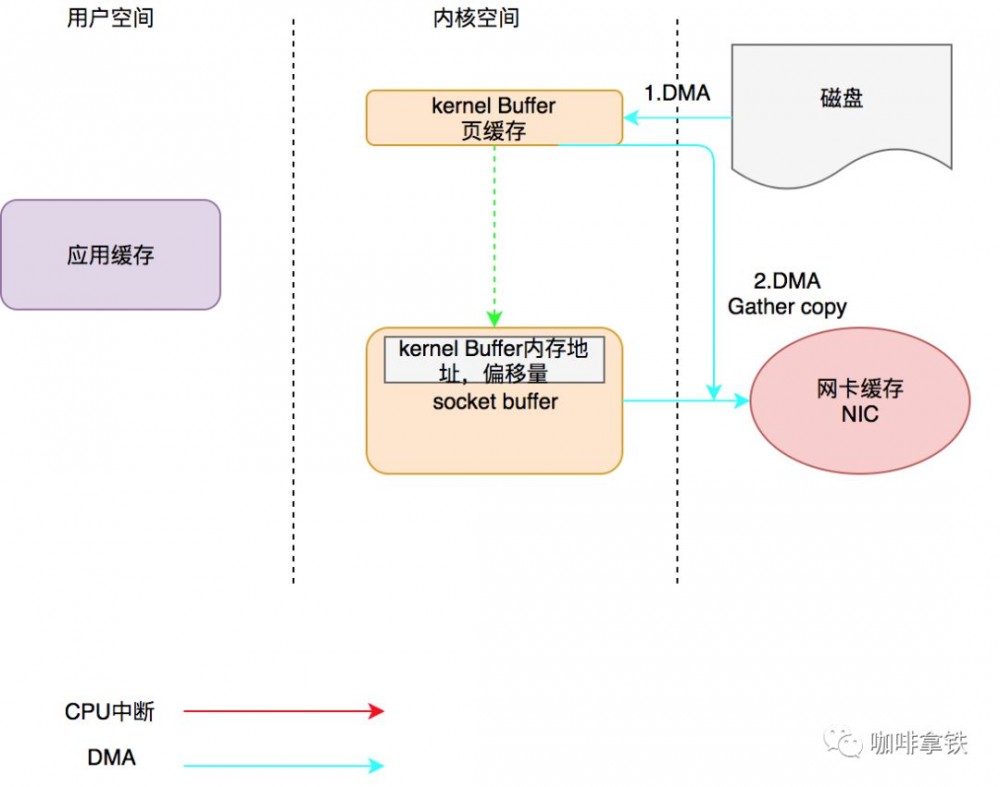
这种方式让CPU全程不参与拷贝,因此效率是最好的。
在第三方开源框架中Netty,RocketMQ,kafka中都有类似的代码,大家如果感兴趣可以下来自行搜索。
mmap映射
上面我们提到了零拷贝的实现,但是我们只能将数据原封不动的发给用户,并不能自己使用。于是Linux提供的一种访问磁盘文件的特殊方式,可以将内存中某块地址空间和我们要指定的磁盘文件相关联,从而把我们对这块内存的访问转换为对磁盘文件的访问,这种技术称为内存映射(Memory Mapping)。 我们通过这种技术将文件直接映射到用户态的内存地址,这样对文件的操作不再是write/read,而是直接对内存地址的操作。
在Java中依靠MappedByteBuffer进行mmap映射,具体的MappedByteBuffer可以详情参照这篇文章:https://www.jianshu.com/p/f90866dcbffc 。
最后
自此,零拷贝的神秘面纱也被揭盖,零拷贝只是为了减少CPU的占用,让CPU做更多真正业务上的事。通过这篇文章,大家可以自己下来看看Netty是怎么做零拷贝的相信将会有更加深刻的印象。
由于作者本人水平不够,如果有什么错误,还请指正。如果上面问题有什么疑问的话可以关注公众号,来和我一起讨论吧,关注即可免费领取海量最新java学习资料视频,以及最新面试资料。
如果大家觉得这篇文章对你有帮助,或者你有什么疑问想提供1v1免费vip服务,都可以关注我的公众号,关注即可免费领取海量最新java学习资料视频,以及最新面试资料,你的关注和转发是对我最大的支持,O(∩_∩)O:

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

