面试 Q&A(三)
java虚拟机的内存模型
@autowrite 如何工作
- 所有的Spring的bean都被ioc容器管理,这个容器叫application context
- 每个web application 都有一个入口叫做dispatcherservlet
- 自动注入将一个bean的实例赋予给另外一个bean的实例,另外一个bean使用了这个bean的地方。自动注入意味着不需要使用new ..
- 除了使用@autowired也可以使用xml配置文件。在这种情况下,所有具有与现有bean匹配的名称或类型的字段都会自动获得注入的bean。实际上,这是自动配线的最初想法——在没有任何配置的情况下注入依赖项。其他注解如@Inject, @Resource也可以使用。
@autowired的注解可以在不同层次上应用:
- 类字段: spring将通过扫描自定义的package或通过在配置文件中直接查找bean
- 方法: 使用@Autowired注解的每个方法都要用到依赖注入。但要注意的是,方法签名中呈现的所有对象都必须是Spring所管理的bean。如果你有一个方法,比如setTest(Article article, NoSpringArticle noSpringArt) ,其中只有一个参数 (Article article)是由Spring管理的,那么就将抛出一个org.springframework.beans.factory.BeanCreationException异常。这是由于Spring容器里并没有指定的一个或多个参数所指向的bean,所以也就无法解析它们。
- 构造函数:@Autowired的工作方式和方法相同。 Spring管理可用于整个应用程序的Java对象bean。他们所在的Spring容器,被称为应用程序上下文。这意味着我们不需要处理他们的生命周期(初始化,销毁)。该任务由此容器来完成。另外,该上下文具有入口点,在Web应用程序中,是dispatcher servlet。容器(也就是该上下文)会在它那里被启动并且所有的bean都会被注入。
工作原理:
4个专门用于处理注解的Bean后置处理器。
- AutowiredAnnotationBeanPostProcessor
- CommonAnnotationBeanPostProcessor
- RequiredAnnotationBeanPostProcessor
- PersistenceAnnotationBeanPostProcessor
当 Spring 容器启动时,AutowiredAnnotationBeanPostProcessor 将扫描 Spring 容器中所有 Bean,当发现 Bean 中拥有@Autowired 注解时就找到和其匹配(默认按类型匹配)的 Bean,并注入到对应的地方中去。 源码分析如下:
通过org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor可以实现依赖自动注入。通过这个类来处理@Autowired和@Value这俩Spring注解。它也可以管理JSR-303的@Inject注解(如果可用的话)。在AutowiredAnnotationBeanPostProcessor构造函数中定义要处理的注解:
public class AutowiredAnnotationBeanPostProcessor extends InstantiationAwareBeanPostProcessorAdapter
implements MergedBeanDefinitionPostProcessor, PriorityOrdered, BeanFactoryAware {
...
/**
* Create a new AutowiredAnnotationBeanPostProcessor
* for Spring's standard {@link Autowired} annotation.
* <p>Also supports JSR-330's {@link javax.inject.Inject} annotation, if available.
*/
@SuppressWarnings("unchecked")
public AutowiredAnnotationBeanPostProcessor() {
this.autowiredAnnotationTypes.add(Autowired.class);
this.autowiredAnnotationTypes.add(Value.class);
try {
this.autowiredAnnotationTypes.add((Class<? extends Annotation>)
ClassUtils.forName("javax.inject.Inject", AutowiredAnnotationBeanPostProcessor.class.getClassLoader()));
logger.info("JSR-330 'javax.inject.Inject' annotation found and supported for autowiring");
}
catch (ClassNotFoundException ex) {
// JSR-330 API not available - simply skip.
}
}
...
}
复制代码
之后,有几种方法来对@Autowired注解进行处理。
第一个,private InjectionMetadata buildAutowiringMetadata(final Class<?> clazz)解析等待自动注入类的所有属性。它通过分析所有字段和方法并初始化org.springframework.beans.factory.annotation.InjectionMetadata类的实例来实现。
private InjectionMetadata buildAutowiringMetadata(final Class<?> clazz) {
LinkedList<InjectionMetadata.InjectedElement> elements = new LinkedList<>();
Class<?> targetClass = clazz;
do {
final LinkedList<InjectionMetadata.InjectedElement> currElements = new LinkedList<>();
//分析所有字段
ReflectionUtils.doWithLocalFields(targetClass, field -> {
//findAutowiredAnnotation(field)此方法后面会解释
AnnotationAttributes ann = findAutowiredAnnotation(field);
if (ann != null) {
if (Modifier.isStatic(field.getModifiers())) {
if (logger.isWarnEnabled()) {
logger.warn("Autowired annotation is not supported on static fields: " + field);
}
return;
}
boolean required = determineRequiredStatus(ann);
currElements.add(new AutowiredFieldElement(field, required));
}
});
//分析所有方法
ReflectionUtils.doWithLocalMethods(targetClass, method -> {
Method bridgedMethod = BridgeMethodResolver.findBridgedMethod(method);
if (!BridgeMethodResolver.isVisibilityBridgeMethodPair(method, bridgedMethod)) {
return;
}
AnnotationAttributes ann = findAutowiredAnnotation(bridgedMethod);
if (ann != null && method.equals(ClassUtils.getMostSpecificMethod(method, clazz))) {
if (Modifier.isStatic(method.getModifiers())) {
if (logger.isWarnEnabled()) {
logger.warn("Autowired annotation is not supported on static methods: " + method);
}
return;
}
if (method.getParameterCount() == 0) {
if (logger.isWarnEnabled()) {
logger.warn("Autowired annotation should only be used on methods with parameters: " +
method);
}
}
boolean required = determineRequiredStatus(ann);
PropertyDescriptor pd = BeanUtils.findPropertyForMethod(bridgedMethod, clazz);
currElements.add(new AutowiredMethodElement(method, required, pd));
}
});
elements.addAll(0, currElements);
targetClass = targetClass.getSuperclass();
}
while (targetClass != null && targetClass != Object.class);
//返回一个InjectionMetadata初始化的对象实例
return new InjectionMetadata(clazz, elements);
}
...
/**
* 'Native' processing method for direct calls with an arbitrary target instance,
* resolving all of its fields and methods which are annotated with {@code @Autowired}.
* @param bean the target instance to process
* @throws BeanCreationException if autowiring failed
*/
public void processInjection(Object bean) throws BeanCreationException {
Class<?> clazz = bean.getClass();
InjectionMetadata metadata = findAutowiringMetadata(clazz.getName(), clazz, null);
try {
metadata.inject(bean, null, null);
}
catch (BeanCreationException ex) {
throw ex;
}
catch (Throwable ex) {
throw new BeanCreationException(
"Injection of autowired dependencies failed for class [" + clazz + "]", ex);
}
}
复制代码
InjectionMetadata类包含要注入的元素的列表。注入是通过Java的API Reflection (Field set(Object obj, Object value) 或Method invoke(Object obj,Object ... args)方法完成的。此过程直接在AutowiredAnnotationBeanPostProcessor的方法中调用public void processInjection(Object bean) throws BeanCreationException。它将所有可注入的bean检索为InjectionMetadata实例,并调用它们的inject()方法。
public class InjectionMetadata {
...
public void inject(Object target, @Nullable String beanName, @Nullable PropertyValues pvs) throws Throwable {
Collection<InjectedElement> checkedElements = this.checkedElements;
Collection<InjectedElement> elementsToIterate =
(checkedElements != null ? checkedElements : this.injectedElements);
if (!elementsToIterate.isEmpty()) {
boolean debug = logger.isDebugEnabled();
for (InjectedElement element : elementsToIterate) {
if (debug) {
logger.debug("Processing injected element of bean '" + beanName + "': " + element);
}
//看下面静态内部类的方法
element.inject(target, beanName, pvs);
}
}
}
...
public static abstract class InjectedElement {
protected final Member member;
protected final boolean isField;
...
/**
* Either this or {@link #getResourceToInject} needs to be overridden.
*/
protected void inject(Object target, @Nullable String requestingBeanName, @Nullable PropertyValues pvs)
throws Throwable {
if (this.isField) {
Field field = (Field) this.member;
ReflectionUtils.makeAccessible(field);
field.set(target, getResourceToInject(target, requestingBeanName));
}
else {
if (checkPropertySkipping(pvs)) {
return;
}
try {
//具体的注入看此处咯
Method method = (Method) this.member;
ReflectionUtils.makeAccessible(method);
method.invoke(target, getResourceToInject(target, requestingBeanName));
}
catch (InvocationTargetException ex) {
throw ex.getTargetException();
}
}
}
...
}
}
复制代码
AutowiredAnnotationBeanPostProcessor类中的另一个重要方法是private AnnotationAttributes findAutowiredAnnotation(AccessibleObject ao)。它通过分析属于一个字段或一个方法的所有注解来查找@Autowired注解。如果未找到@Autowired注解,则返回null,字段或方法也就视为不可注入。
@Nullable
private AnnotationAttributes findAutowiredAnnotation(AccessibleObject ao) {
if (ao.getAnnotations().length > 0) {
for (Class<? extends Annotation> type : this.autowiredAnnotationTypes) {
AnnotationAttributes attributes = AnnotatedElementUtils.getMergedAnnotationAttributes(ao, type);
if (attributes != null) {
return attributes;
}
}
}
return null;
}
复制代码
常用的linux命令
问1:如何查看当前的Linux服务器运行级别?
答:who -r 和 runlevel 命令可以用来查看当前的Linux服务器的运行级别。
Linux的运行级别有7种:
0 所有进程将被终止,机器将有序的停止,关机时系统处于这个运行级别
1 单用户模式。用于系统维护,只有少数进程运行,同时所有服务也不启动
2 多用户模式。和运行级别3一样,只是网络文件系统(NFS)服务没被启动
3 多用户模式。允许多用户登录系统,是系统默认的启动级别 4 留给用户自定义的运行级别
5 多用户模式,并且在系统启动后运行X-Window,给出一个图形化的登录窗口
6 所有进程被终止,系统重新启动
问2:如何查看Linux的默认网关?
答:用route -n 或 netstat -nr命令,我们可以查看默认网关,除了默认网关信息,这两个命令还可以显示当前的路由表。
问3:cpio 命令是什么?
答:cpio命令是通过重定向的方式将文件进行打包备份,还原恢复的工具,它可以解压以“.cpio”或者“.tar”结尾的文件。
详细请查看cpio命令详解
问4:patch命令是什么,如何使用?
答:顾名思义,patch命令用来用来将补丁写进文本文件里面。patch命令通常是接受diff的输出,并把文件的旧版本转换为新版本。
举个例子:
diff -Naur old_file new _file > diff_file 旧文件和新文件要么都是单个的文件要么就是包含文件的目录,-r参数支持目录树递归。一旦diff文件创建好,我们就可以在旧文件上打上补丁,把他变成新文件:
patch < diff_file 问题5:如何识别Linux系统中指定文件(/etc/fstab)的关联包(即查询一个已经安装的文件属于哪个软件包)?
答:命令rmp -qf /etc/fstab可以列出提供”/etc/fstab”这个文件的包。
RPM是RedHat Package Manager(RedHat软件包管理工具)类似Windows里面的“添加/删除程序”
rpm 执行安装包,二进制包(Binary)以及源代码包(Source)两种。二进制包可以直接安装在计算机中,而源代码包将会由RPM自动编译、安装。源代码包经常以src.rpm作为后缀名。
常用命令组合:
- ivh:安装显示安装进度--install--verbose--hash - Uvh:升级软件包--Update; - qpl:列出RPM软件包内的文件信息[Query Package list]; - qpi:列出RPM软件包的描述信息[Query Package install package(s)]; - qf:查找指定文件属于哪个RPM软件包[Query File]; - Va:校验所有的RPM软件包,查找丢失的文件[View Lost]; - e:删除包 rpm -q samba //查询程序是否安装 rpm -ivh /media/cdrom/RedHat/RPMS/samba-3.0.10-1.4E.i386.rpm //按路径安装并显示进度 rpm -ivh --relocate /=/opt/gaim gaim-1.3.0-1.fc4.i386.rpm //指定安装目录 rpm -ivh --test gaim-1.3.0-1.fc4.i386.rpm //用来检查依赖关系;并不是真正的安装; rpm -Uvh --oldpackage gaim-1.3.0-1.fc4.i386.rpm //新版本降级为旧版本 rpm -qa | grep httpd #[搜索指定rpm包是否安装]--all搜索*httpd* rpm -ql httpd #[搜索rpm包]--list所有文件安装目录 rpm -qpi Linux-1.4-6.i368.rpm #[查看rpm包]--query--package--install package信息 rpm -qpf Linux-1.4-6.i368.rpm #[查看rpm包]--file rpm -qpR file.rpm #[查看包]依赖关系 rpm2cpio file.rpm |cpio -div #[抽出文件] rpm -ivh file.rpm #[安装新的rpm]--install--verbose--hash rpm -ivh rpm -Uvh file.rpm #[升级一个rpm]--upgrade rpm -e file.rpm #[删除一个rpm包]--erase 复制代码
常用参数:
Install/Upgrade/Erase options: -i, --install install package(s) -v, --verbose provide more detailed output -h, --hash print hash marks as package installs (good with -v) -e, --erase erase (uninstall) package -U, --upgrade=<packagefile>+ upgrade package(s) --replacepkge 无论软件包是否已被安装,都强行安装软件包 --test 安装测试,并不实际安装 --nodeps 忽略软件包的依赖关系强行安装 --force 忽略软件包及文件的冲突 Query options (with -q or --query): -a, --all query/verify all packages -p, --package query/verify a package file -l, --list list files in package -d, --docfiles list all documentation files -f, --file query/verify package(s) owning file 复制代码
问题6:Linux系统中的/proc文件系统有什么用?
答:/proc文件系统是一个基于内存的文件系统,维护着有关于当前正在运行的内核状态信息,其中包括CPU、内存、分区划分、 I/O地址、直接内存访问通道和正在运行的进程。这个文件系统所代表的并不是各种实际存储信息的文件,他们指向的是内存里的信息。 /proc文件系统是由系统自动维护的。
问题7: 如何在/usr目录下找出大小超过10MB的文件?
答:find /usr -size +10M
问题8:如何在/home目录下找出120天之前被修改过的文件?
答:find /home -mtime +120
问题9:如何在/var目录下找出90天之内未被访问过的文件?
答:find /var ! -atime -90
问题10:在整个目录树下查找文件“core”,如果发现则无需提示,直接删除他们?
答:find / -name core -exec rm {} ; , -exec 参数后面跟的是command命令,它的终止是以;为结束标志的,所以这句命令后面的分号是不可缺少的,考虑到各个系统中分号会有不同的意义,所以前面加反斜杠。
问题11:strings命令有什么作用?
答:strings命令用来提取和显示非文本文件中的文本字符串。
问题12:tee过滤器有什么作用?
答:tee过滤器用来想多个目标发送输出的内容。如果用于管道的话,他可以将输出复制一份到文件,兵复制另外一份到屏幕上(或一些其他的程序)。
详细请查看tee命令详解
问题13:export PS1=" PWD:" 这条指令是在做什么?
答:这条export命令会更改登录提示符来显示用户名、本机名、和当前的工作目录。
问题14:ll | awk ‘{print $3, “owns”, $9}’这条命令是在做什么?
答:会显示这些文件的名称和他们的拥有者。
详细请看awk命令详解
问题15:Linux中at命令有什么用?
答:at命令用来安排一个程序在未来的做一次性执行。所以有提交的任务都会被放在/var/spool/at目录下,并且到了执行时间的时候通过atd守护进程来执行。
详细请看at命令详解
find
从命令行搜索文件,它可以用于根据各种搜索标准查找文件,如权限、用户所有权、修改数据/时间 find [searching path] [options] [keyword]
UDP和TCP的比较
有两种类型的Internet协议(IP)。它们是TCP或传输控制协议和UDP或用户数据报协议。TCP是面向连接的——一旦建立了连接,数据就可以双向发送。UDP是一种更简单、无连接的Internet协议。
TCP和UDP是两种传输层协议,在internet上广泛用于将数据从一个主机传输到另一个主机。
首先,TCP代表传输控制协议,UDP代表用户数据报协议,两者都被广泛用于构建Internet应用程序。
不同点
1)面向连接和无连接 它们之间的首要区别是TCP是面向连接的协议,而UDP是无连接协议。这意味着在客户端和服务器之间建立连接,然后才能发送数据。连接建立过程也称为TCP握手,其中控制消息在客户端和服务器之间互换。附加图像描述了TCP握手的过程,例如,在客户端和服务器之间交换哪些控制消息。
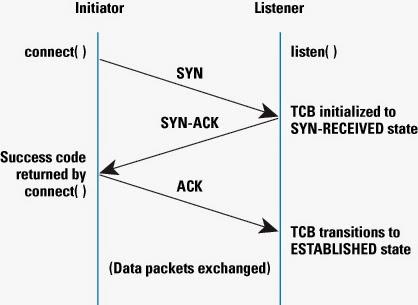
客户端是TCP连接的发起者,它将SYN消息发送到正在侦听TCP端口的服务器。服务器接收并发送SYN-ACK消息,该消息再次由客户端接收并使用ACK进行响应。一旦服务器收到此ACK消息,就建立TCP连接并准备好进行数据传输。
另一方面,UDP是无连接协议,在发送消息之前未建立点对点连接。这就是为什么UDP更适合于消息的多播分发,单个传输中的一对多数据分布。
2)可靠性 TCP提供了传输保证,即保证使用TCP协议发送的消息被传递到客户端。如果消息在传输过程中丢失,则使用重发恢复消息,这由TCP协议本身处理。另一方面,UDP是不可靠的,它不提供任何交付保证。数据报包可能在传输过程中丢失。这就是为什么UDP不适合需要保证交付的程序。
3)顺序 除了提供保证之外,TCP还保证消息的顺序。消息将以服务器发送的相同顺序发送给客户端,尽管它们可能会按照顺序发送到网络的另一端。TCP协议将对您进行所有的排序和排序。UDP不提供任何排序或排序保证。
数据报包可以以任何顺序到达。这就是为什么TCP适用于需要按顺序交付的应用程序,尽管也有基于UDP的协议,它通过使用序列号和重发(例如TIBCO Rendezvous,实际上是一个基于UDP的应用程序)来提供排序和可靠性。
4)数据边界 TCP不保留数据边界,UDP保留。在传输控制协议中,数据以字节流的形式发送,并且没有向信号消息(段)边界传输任何明显的指示。在UDP上,数据包是单独发送的,只有到达时才检查其完整性。数据包有一定的边界,这在接收端套接字上的读取操作将产生一个完整的消息,就像它最初发送的那样。尽管TCP也会在组装完所有字节后发送完整的消息。消息在发送之前存储在TCP缓冲区中,以优化网络带宽的使用。
5)速度 总之,TCP很慢,UDP很快。由于TCP必须创建一个连接,确保有保证和有序的交付,所以它所做的工作要比UDP多得多。
6)重量型vs轻量型 由于上面提到的开销,与轻量级UDP协议相比,传输控制协议被认为是重量级的。UDP的一个简单的咒语,在不需要任何创建连接和保证交付或订单保证的情况下发送消息,使其重量更轻。这也反映在它们的头大小中,头大小用于携带元数据。
7)头 TCP的头比UDP大。TCP报头的一般大小是20字节,大于8字节的两倍,是UDP数据报报头的大小。TCP报头包含序列号、Ack编号、数据偏移、保留、控制位、窗口、紧急指针、选项、填充、校验和、源端口和目标端口。而UDP头只包含长度、源端口、目的端口和校验和。下面是TCP和UDP报头的样子:

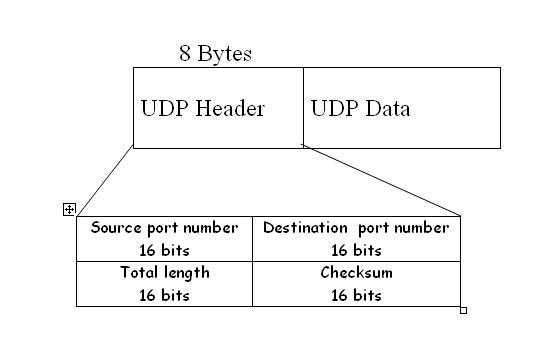
8)拥堵或流量控制 TCP流量控制。TCP需要三个包来设置套接字连接,然后才能发送任何用户数据。TCP处理可靠性和拥塞控制。另一方面,UDP没有流控制选项。
9)使用和应用 在internet上TCP和UDP在哪里使用?在了解了TCP和UDP之间的关键差异之后,我们可以很容易地得出适合它们的情况。由于TCP提供了交付和排序保证,因此它最适合需要高可靠性的应用程序,而且传输时间相对不那么重要。
而UDP更适合需要快速、高效传输的应用程序,如游戏。UDP的无状态特性对于回答大量客户端的小查询的服务器也很有用。在实践中,TCP被用于金融领域,例如FIX protocol是基于TCP的协议,UDP在游戏和娱乐站点中被大量使用。
10)基于TCP和UDP的协议 基于TCP的高级端协议的最好例子之一是HTTP和HTTPS,这在internet上随处可见。实际上,您所熟悉的大多数常见协议(如Telnet、FTP和SMTP)都是基于传输控制协议的。UDP没有像HTTP那样流行的东西,但是UDP是在DHCP(动态主机配置协议)和DNS(域名系统)这样的协议中使用的。另一些基于用户数据报协议的协议是简单网络管理协议(SNMP)、TFTP、BOOTP和NFS(早期版本)。
顺便说一句,在基于Linux的TCP/UDP应用程序中工作时,最好记住基本的网络命令,例如telnet和netstat,它们对于调试或排除任何连接问题都有很大的帮助。
这就是TCP和UDP协议的不同之处。永远记得要提到TCP是连接的,可靠的,缓慢的,提供保证的交付和保持消息的顺序,而UDP是无连接的,不可靠的,没有订购保证,但是一个快速的协议。TCP开销也比UDP高得多,因为它比UDP每包传输更多的元数据。
值得一提的是,传输控制协议的报头大小为20字节,而用户数据报协议的报头大小为8字节。使用TCP,如果你不能承受丢失任何消息,而UDP更适合高速数据传输,在这种情况下,一个数据包的丢失是可以接受的,例如视频流或在线多人游戏。
使用Spring的一些优点
在给出使用Spring框架的好处之前,让我们简单地描述一下Spring。
Spring框架是一种用于企业Java (JEE)的功能强大的轻量级应用程序开发框架。
以下是Spring的好处:
- 轻量级:Spring框架在大小和透明性方面都是轻量级的。
- Spring通过依赖注入和基于接口的编程实现了松耦合。
- 控制反转:在Spring框架中,通过控制反转实现松耦合。对象提供它们自己的依赖项,而不是创建或查找依赖项对象。
- 面向方面编程(AOP):通过将应用程序业务逻辑与系统服务分离,Spring框架支持面向方面编程并支持内聚开发。
- 容器:Spring框架创建并管理应用程序对象的生命周期和配置。
- MVC框架:Spring框架是一个MVC web应用程序框架。该框架可以通过接口进行配置,并支持多种视图技术。
- 事务管理:对于事务管理,Spring框架提供了一个通用的抽象层。它不与J2EE环境绑定,可以在无容器环境中使用。
- JDBC异常处理:Spring框架的抽象JDBC层提供了异常层次结构,这简化了错误处理策略。
实现栈,O(1)如何实现?
这是一个使用链表实现堆栈的Java程序。堆栈是一个内存区域,它包含任何函数使用的所有局部变量和参数,并记住调用函数的顺序,以便函数返回正确。每次调用一个函数时,它的局部变量和参数都被“推到”堆栈上。当函数返回时,这些局部变量和参数将被“弹出”。因此,程序堆栈的大小随着程序的运行而不断波动,但是它有一些最大的大小。堆栈是第一个(LIFO)抽象数据类型和线性数据结构的最后一个。链表是由一组节点组成的数据结构,它们共同代表一个序列。这里我们需要应用链表的应用来执行栈的基本操作。 下面是使用链表实现堆栈的Java程序的源代码。Java程序被成功编译并在Windows系统上运行。程序输出如下所示。
/*
* Java Program to Implement Stack using Linked List
*/
import java.util.*;
/* Class Node */
class Node
{
protected int data;
protected Node link;
/* Constructor */
public Node()
{
link = null;
data = 0;
}
/* Constructor */
public Node(int d,Node n)
{
data = d;
link = n;
}
/* Function to set link to next Node */
public void setLink(Node n)
{
link = n;
}
/* Function to set data to current Node */
public void setData(int d)
{
data = d;
}
/* Function to get link to next node */
public Node getLink()
{
return link;
}
/* Function to get data from current Node */
public int getData()
{
return data;
}
}
/* Class linkedStack */
class linkedStack
{
protected Node top ;
protected int size ;
/* Constructor */
public linkedStack()
{
top = null;
size = 0;
}
/* Function to check if stack is empty */
public boolean isEmpty()
{
return top == null;
}
/* Function to get the size of the stack */
public int getSize()
{
return size;
}
/* Function to push an element to the stack */
public void push(int data)
{
Node nptr = new Node (data, null);
if (top == null)
top = nptr;
else
{
nptr.setLink(top);
top = nptr;
}
size++ ;
}
/* Function to pop an element from the stack */
public int pop()
{
if (isEmpty() )
throw new NoSuchElementException("Underflow Exception") ;
Node ptr = top;
top = ptr.getLink();
size-- ;
return ptr.getData();
}
/* Function to check the top element of the stack */
public int peek()
{
if (isEmpty() )
throw new NoSuchElementException("Underflow Exception") ;
return top.getData();
}
/* Function to display the status of the stack */
public void display()
{
System.out.print("/nStack = ");
if (size == 0)
{
System.out.print("Empty/n");
return ;
}
Node ptr = top;
while (ptr != null)
{
System.out.print(ptr.getData()+" ");
ptr = ptr.getLink();
}
System.out.println();
}
}
复制代码
使用一个队列实现栈
// x is the element to be pushed and s is stack push(s, x) 1) Let size of q be s. 2) Enqueue x to q 3) One by one Dequeue s items from queue and enqueue them. // Removes an item from stack pop(s) 1) Dequeue an item from q 复制代码
import java.util.LinkedList;
import java.util.Queue;
public class stack
{
Queue<Integer> q = new LinkedList<Integer>();
// Push operation
void push(int val)
{
// get previous size of queue
int size = q.size();
// Add current element
q.add(val);
// Pop (or Dequeue) all previous
// elements and put them after current
// element
for (int i = 0; i < size; i++)
{
// this will add front element into
// rear of queue
int x = q.remove();
q.add(x);
}
}
// Removes the top element
int pop()
{
if (q.isEmpty())
{
System.out.println("No elements");
return -1;
}
int x = q.remove();
return x;
}
// Returns top of stack
int top()
{
if (q.isEmpty())
return -1;
return q.peek();
}
// Returns true if Stack is empty else false
boolean isEmpty()
{
return q.isEmpty();
}
// Driver program to test above methods
public static void main(String[] args)
{
stack s = new stack();
s.push(10);
s.push(20);
System.out.println("Top element :" + s.top());
s.pop();
s.push(30);
s.pop();
System.out.println("Top element :" + s.top());
}
}
复制代码
用两个队列实现一个栈
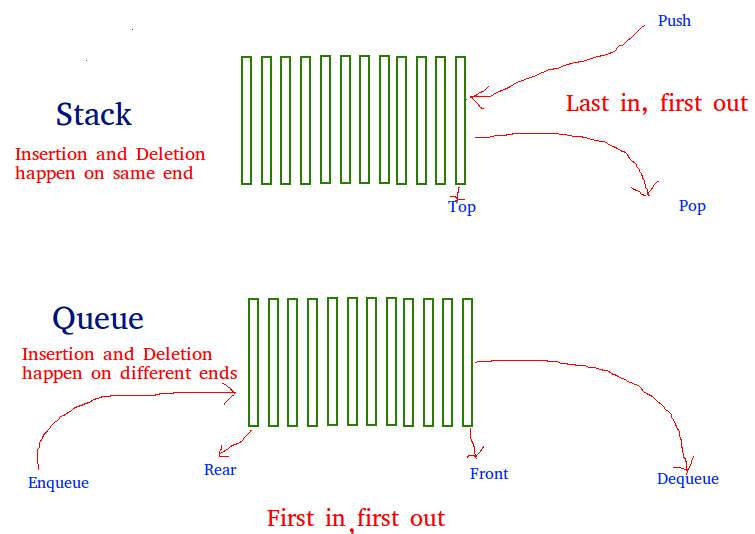
Method 1 (By making push operation costly)
This method makes sure that newly entered element is always at the front of ‘q1’, so that pop operation just dequeues from ‘q1’. ‘q2’ is used to put every new element at front of ‘q1’.
push(s, x) // x is the element to be pushed and s is stack 1) Enqueue x to q2 2) One by one dequeue everything from q1 and enqueue to q2. 3) Swap the names of q1 and q2 // Swapping of names is done to avoid one more movement of all elements // from q2 to q1. pop(s) 1) Dequeue an item from q1 and return it. 复制代码
/* Program to implement a stack using
two queue */
#include<bits/stdc++.h>
using namespace std;
class Stack
{
// Two inbuilt queues
queue<int> q1, q2;
// To maintain current number of
// elements
int curr_size;
public:
Stack()
{
curr_size = 0;
}
void push(int x)
{
curr_size++;
// Push x first in empty q2
q2.push(x);
// Push all the remaining
// elements in q1 to q2.
while (!q1.empty())
{
q2.push(q1.front());
q1.pop();
}
// swap the names of two queues
queue<int> q = q1;
q1 = q2;
q2 = q;
}
void pop(){
// if no elements are there in q1
if (q1.empty())
return ;
q1.pop();
curr_size--;
}
int top()
{
if (q1.empty())
return -1;
return q1.front();
}
int size()
{
return curr_size;
}
};
// driver code
int main()
{
Stack s;
s.push(1);
s.push(2);
s.push(3);
cout << "current size: " << s.size()
<< endl;
cout << s.top() << endl;
s.pop();
cout << s.top() << endl;
s.pop();
cout << s.top() << endl;
cout << "current size: " << s.size()
<< endl;
return 0;
}
// This code is contributed by Chhavi
Output :
current size: 3
3
2
1
current size: 1
复制代码
Method 2 (By making pop operation costly)
In push operation, the new element is always enqueued to q1. In pop() operation, if q2 is empty then all the elements except the last, are moved to q2. Finally the last element is dequeued from q1 and returned.
push(s, x) 1) Enqueue x to q1 (assuming size of q1 is unlimited). pop(s) 1) One by one dequeue everything except the last element from q1 and enqueue to q2. 2) Dequeue the last item of q1, the dequeued item is result, store it. 3) Swap the names of q1 and q2 4) Return the item stored in step 2. // Swapping of names is done to avoid one more movement of all elements // from q2 to q1. 复制代码
/* Program to implement a stack
using two queue */
#include<bits/stdc++.h>
using namespace std;
class Stack
{
queue<int> q1, q2;
int curr_size;
public:
Stack()
{
curr_size = 0;
}
void pop()
{
if (q1.empty())
return;
// Leave one element in q1 and
// push others in q2.
while (q1.size() != 1)
{
q2.push(q1.front());
q1.pop();
}
// Pop the only left element
// from q1
q1.pop();
curr_size--;
// swap the names of two queues
queue<int> q = q1;
q1 = q2;
q2 = q;
}
void push(int x)
{
q1.push(x);
curr_size++;
}
int top()
{
if (q1.empty())
return -1;
while( q1.size() != 1 )
{
q2.push(q1.front());
q1.pop();
}
// last pushed element
int temp = q1.front();
// to empty the auxiliary queue after
// last operation
q1.pop();
// push last element to q2
q2.push(temp);
// swap the two queues names
queue<int> q = q1;
q1 = q2;
q2 = q;
return temp;
}
int size()
{
return curr_size;
}
};
// driver code
int main()
{
Stack s;
s.push(1);
s.push(2);
s.push(3);
s.push(4);
cout << "current size: " << s.size()
<< endl;
cout << s.top() << endl;
s.pop();
cout << s.top() << endl;
s.pop();
cout << s.top() << endl;
cout << "current size: " << s.size()
<< endl;
return 0;
}
复制代码
用数组实现
public class Stack<E> {
private E[] arr = null;
private int CAP;
private int top = -1;
private int size = 0;
@SuppressWarnings("unchecked")
public Stack(int cap) {
this.CAP = cap;
this.arr = (E[]) new Object[cap];
}
public E pop() {
if(this.size == 0){
return null;
}
this.size--;
E result = this.arr[top];
this.arr[top] = null;//prevent memory leaking
this.top--;
return result;
}
public boolean push(E e) {
if (!isFull())
return false;
this.size++;
this.arr[++top] = e;
return false;
}
public boolean isFull() {
if (this.size == this.CAP)
return false;
return true;
}
public String toString() {
if(this.size==0){
return null;
}
StringBuilder sb = new StringBuilder();
for(int i=0; i<this.size; i++){
sb.append(this.arr[i] + ", ");
}
sb.setLength(sb.length()-2);
return sb.toString();
}
public static void main(String[] args) {
Stack<String> stack = new Stack<String>(11);
stack.push("hello");
stack.push("world");
System.out.println(stack);
stack.pop();
System.out.println(stack);
stack.pop();
System.out.println(stack);
}
}
复制代码
java 父类的接口,子类会继承么?
可以
/**
* Created by mac on 2018/7/7.
*/
public interface interfacea {
public void print();
}
/**
* Created by mac on 2018/7/7.
*/
public class test implements interfacea{
@Override
public void print() {
System.out.println("implements interfaces from test");
}
}
/**
* Created by mac on 2018/7/7.
*/
public class testchild extends test{
public static void main(String[] args) {
testchild testchild = new testchild();
testchild.print();
}
}
output:
implements interfaces from test
复制代码
spring boot和spring的区别
- Spring Boot可以建立独立的Spring应用程序;
- 内嵌了如Tomcat,Jetty和Undertow这样的容器,也就是说可以直接跑起来,用不着再做部署工作了。
- 无需再像Spring那样搞一堆繁琐的xml文件的配置;
- 可以自动配置Spring;
- 提供了一些现有的功能,如量度工具,表单数据验证以及一些外部配置这样的一些第三方功能;
- 提供的POM可以简化Maven的配置;
Spring 框架就像一个家族,有众多衍生产品例如 boot、security、jpa等等。但他们的基础都是Spring 的 ioc和 aop ioc 提供了依赖注入的容器 aop ,解决了面向横切面的编程,然后在此两者的基础上实现了其他延伸产品的高级功能。Spring MVC是基于 Servlet 的一个 MVC 框架 主要解决 WEB 开发的问题,因为 Spring 的配置非常复杂,各种XML、 JavaConfig、hin处理起来比较繁琐。于是为了简化开发者的使用,从而创造性地推出了Spring boot,约定优于配置,简化了spring的配置流程。
说得更简便一些:Spring 最初利用“工厂模式”(DI)和“代理模式”(AOP)解耦应用组件。大家觉得挺好用,于是按照这种模式搞了一个 MVC框架(一些用Spring 解耦的组件),用开发 web 应用( SpringMVC )。然后有发现每次开发都写很多样板代码,为了简化工作流程,于是开发出了一些“懒人整合包”(starter),这套就是 Spring Boot。
Spring MVC的功能
Spring MVC提供了一种轻度耦合的方式来开发web应用。
Spring MVC是Spring的一个模块,式一个web框架。通过Dispatcher Servlet, ModelAndView 和 View Resolver,开发web应用变得很容易。解决的问题领域是网站应用程序或者服务开发——URL路由、Session、模板引擎、静态Web资源等等。
Spring Boot的功能
Spring Boot实现了自动配置,降低了项目搭建的复杂度。
众所周知Spring框架需要进行大量的配置,Spring Boot引入自动配置的概念,让项目设置变得很容易。Spring Boot本身并不提供Spring框架的核心特性以及扩展功能,只是用于快速、敏捷地开发新一代基于Spring框架的应用程序。也就是说,它并不是用来替代Spring的解决方案,而是和Spring框架紧密结合用于提升Spring开发者体验的工具。同时它集成了大量常用的第三方库配置(例如Jackson, JDBC, Mongo, Redis, Mail等等),Spring Boot应用中这些第三方库几乎可以零配置的开箱即用(out-of-the-box),大部分的Spring Boot应用都只需要非常少量的配置代码,开发者能够更加专注于业务逻辑。
Spring Boot只是承载者,辅助你简化项目搭建过程的。如果承载的是WEB项目,使用Spring MVC作为MVC框架,那么工作流程和你上面描述的是完全一样的,因为这部分工作是Spring MVC做的而不是Spring Boot。
对使用者来说,换用Spring Boot以后,项目初始化方法变了,配置文件变了,另外就是不需要单独安装Tomcat这类容器服务器了,maven打出jar包直接跑起来就是个网站,但你最核心的业务逻辑实现与业务流程实现没有任何变化。
Spring 是一个“引擎”;
Spring MVC 是基于Spring的一个 MVC 框架 ;
Spring Boot 是基于Spring4的条件注册的一套快速开发整合包。
正文到此结束
- 本文标签: Persistence ip CTO 敏捷 update Collection find 企业 rpm mongo UI 生命 jetty 代码 linux Property js 实例 参数 服务器 id cat core 端口 equals redis queue tomcat 域名 list java IO nfs final 测试 bug 金融 fstab pom 内存模型 BeanDefinition https Document 软件 站点 文件系统 产品 src windows LinkedList 数据 JPA servlet UDP value spring ORM swap 开发 协议 专注 配置 删除 maven API 处理器 awk 解析 SpringMVC 备份 AOP 进程 build tab session 调试 ACE TCP key rmi ioc tar dependencies 编译 模型 安装 http db 并发 管理 Security struct App BeanUtils web 工作原理 grep ftp 源码 回答 开发者 Word mail 时间 目录 bean DNS XML 一对多 ssl Spring Boot 网站 主机 node JDBC IDE
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

