Spring的声明式事务模型
组内每周都有技术分享,轮着来,人人有份。
上次分享了 Spring的统一事务模型 ,这次聊聊Spring的声明式事务模型。
和上次一样,周五分享完,周末把keynote整理成文稿,和诸君共食。
难度一般,老少咸宜。
关注微信公众号Bridge4You,回复Spring事务,即可获取这两次分享的keynote或者ppt。
什么是Spring的声明式事务
声明式事务,其实就是我们常用的@Transactional注解,加了个注解,马上就有了事务,非常神奇,比我们之前用TransactionTemplate那种编程式事务,方便太多:

声明式事务是怎么实现的
那么到底是什么力量,使得我们加个注解,就能够产生事务呢?
这个在之前的 玩转Spring —— 消失的事务 中也有提到,那就是aop。
你加了个注解,Spring就会生成一个代理对象,这个代理对象就会有事务的逻辑。
简单回顾下aop的原理。
首先,在Spring Bean初始化的过程中,有一个叫applyBeanPostProcessorsAfterInitialization的阶段,会获取BeanPostProcessor(下文简称BPP)列表,然后逐个执行BPP的postProcessAfterInitialization方法。而当你开启了Spring的aop功能,那么在这些BPP里头,就会有一个专门为aop服务的BPP,叫AbstractAutoProxyCreator:
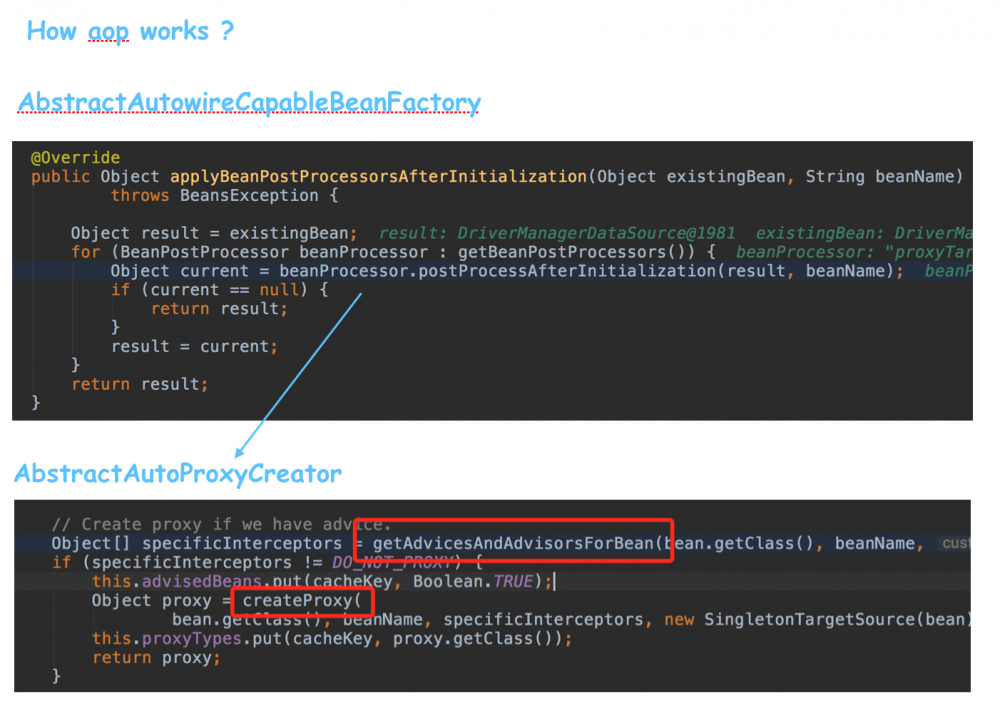
看上图代码,AbstractAutoProxyCreator的postProcessAfterInitialization非常简单,调用getAdvicesAndAdvisorsForBean方法,获取Advice和Advisor列表,然后利用这些Advice和Advisor,调用createProxy方法,去创建代理对象。
Advice和Advisor都是什么东西?放一张图:
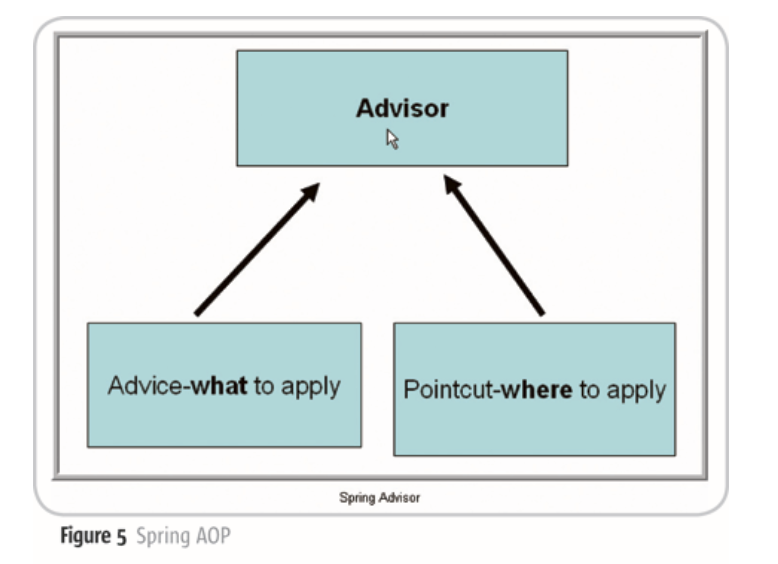
Advisor = advice + pointcut,advice定义切面要做什么,pointcut定义切面在哪执行,两者共同形成了切面Advisor。
好,现在问题来了,假设你是Spring的开发人员,你们已经开发好了上面这套aop的功能,那么要怎么实现,加个@Transational注解,就能产生事务切面呢?
很简单,你只需要写一个事务的Advisor,定义好事务的Advice(事务创建、回滚、提交)和Pointcut(在哪产生事务),就ok了。
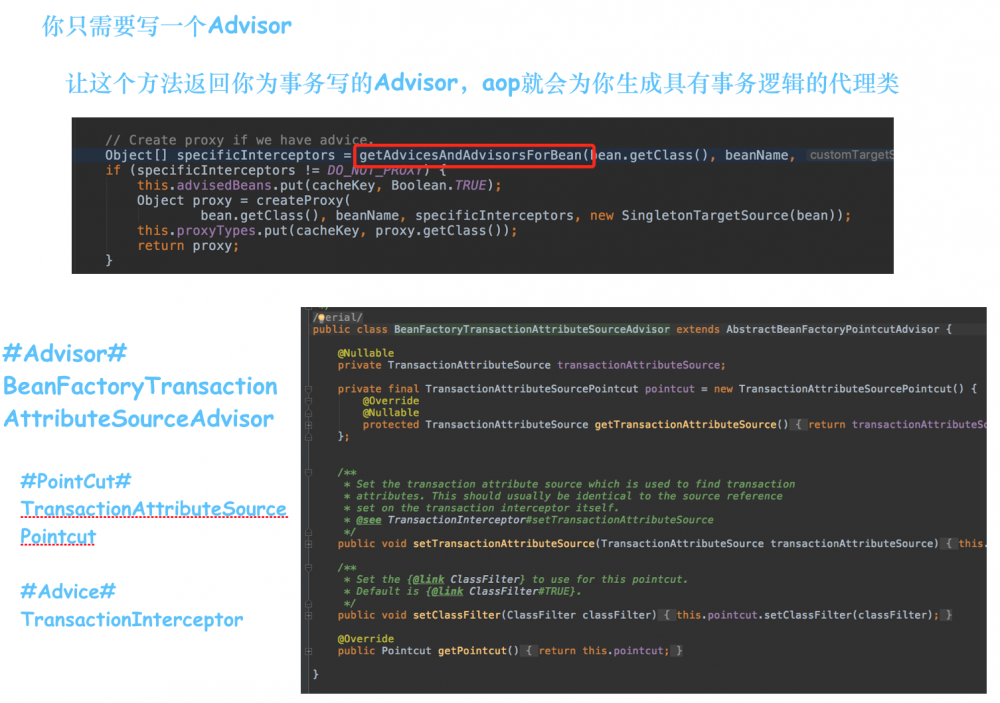
Spring中,事务对应的Advisor是BeanFactoryTransactionAttributeSourceAdvisor,它的adivce是TransactionInterceptor,pointcut是TransactionAttributeSourcePointcut。
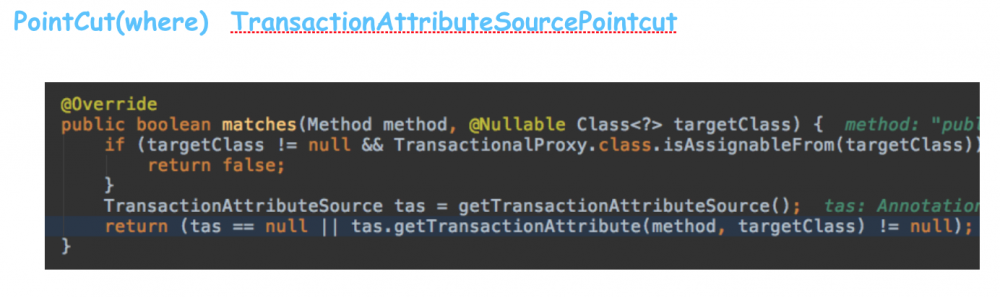
pointcut: TransactionAttributeSourcePointcut非常简单,就是判断方法上有没有@Transational注解:
而advice: TransactionInterceptor也不复杂,跟我们之前看的编程式事务里的TransactionTemplate还有几分相似:

声明式事务 vs 编程式事务
结合上次分享,我们已经研究了编程式事务和声明式事务的原理,那么,这两种使用事务的方式,到底孰优孰劣呢?参考了Spring官方文档的建议,上图一张:

在实际使用中,你会发现,使用声明式事务,定义事务隔离级别和传播级别是非常方便的,而使用编程式事务,则比较麻烦,每次都需要new一个TransactionTemplate(为什么??):

可能你会问,什么时候我们才需要去修改隔离级别或者传播级别?
别急,下面聊到这个话题。
事务传播级别
事务传播级别,就像下图代码片段一样,你可以在@Transactional注解里,定义一个传播级别的属性:
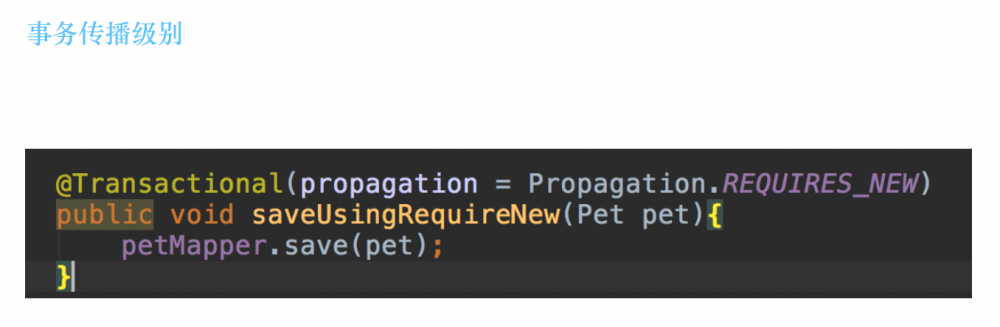
事务传播级别总共有以下这几种:

其中require new和nested的区别,是大多数最感到疑惑的。
先来个问题,下面两个函数,分别调用100次,哪个更快?

我在自己的机器上试了一下:
- nested: 232ms
- req new: 3256ms
为什么nested比req new快这么多???
先看Spring代码里关于nested的注释:
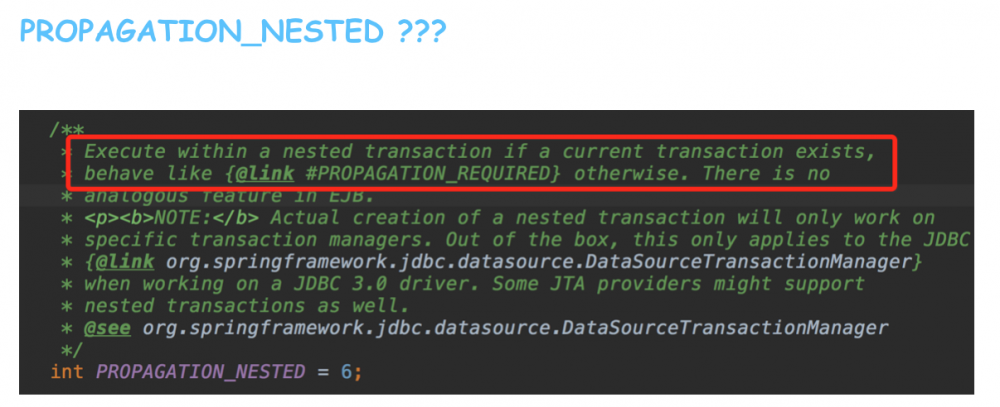
翻译过来大概就是:如果当前已经存在事务,那么在嵌套事务里执行;如果当前没有事务,那么和require传播级别一样。
看完还是云里雾里,还是看代码直接。
上次分享提到过,AbstractPlatformTransactionManager有一个getTransaction方法,用来获取事务:
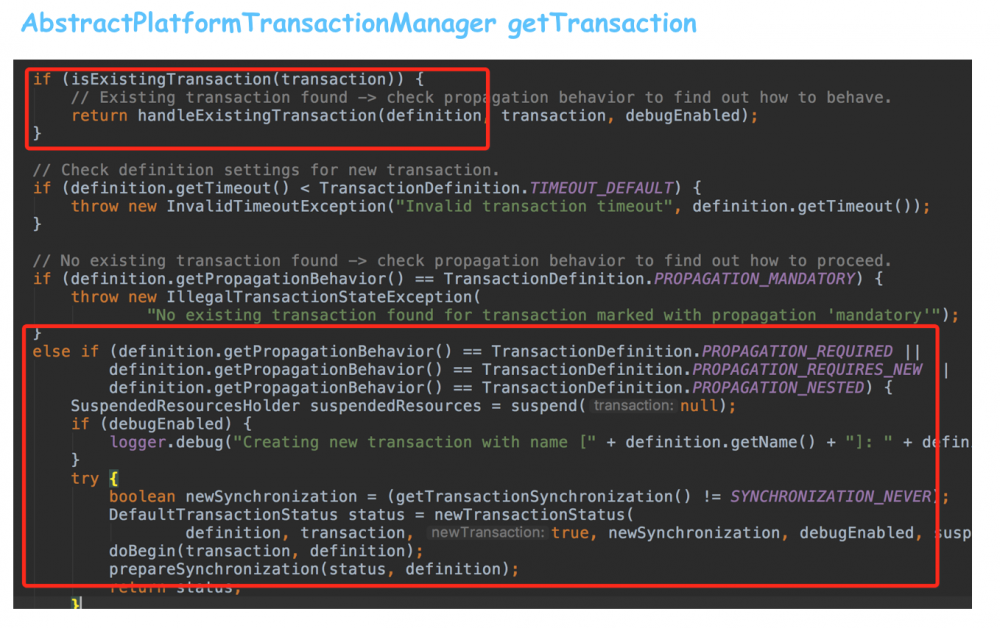
从代码可以看出,如果当前已经有事务,那么会去执行handleExistingTransaction方法,如果没有,那么require/require new/nested执行的代码都是一样的,都是去新建事务。
所以关键就在handleExistingTransaction方法:
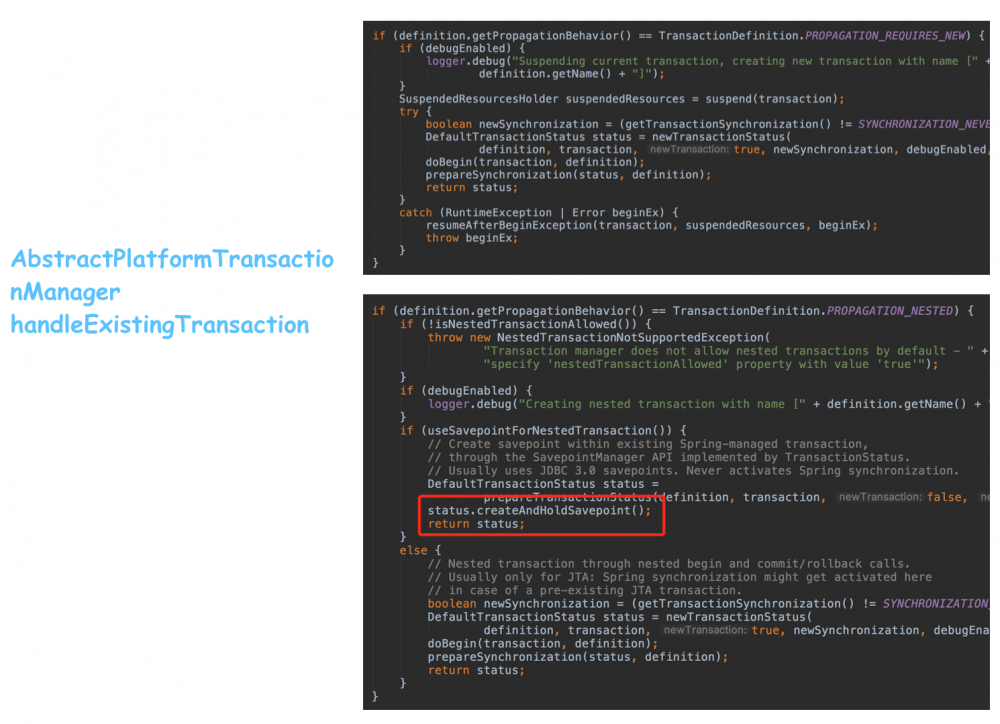
从上图代码,很明显可以看出,nested,如果当前已经有事务了,它不会再去创建事务,而是使用savepoint.
savepoint的原理是什么?我参考了Oracle上的一份邮件讨论:
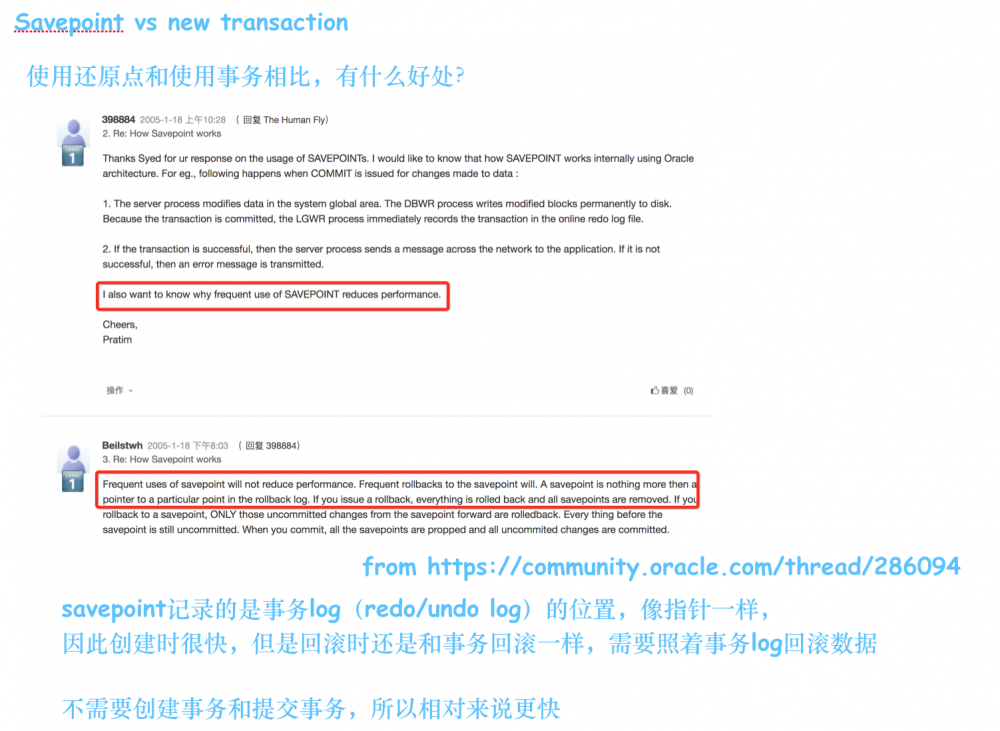
savepoint就像一个执行,指向事务log的位置,当你需要回滚时,只需回滚到对应log的位置。
使用savepoint时,不需要新建连接、也不需要执行事务提交、释放锁等复杂耗时的操作,所以比每次都去创建事务的req new要更快。
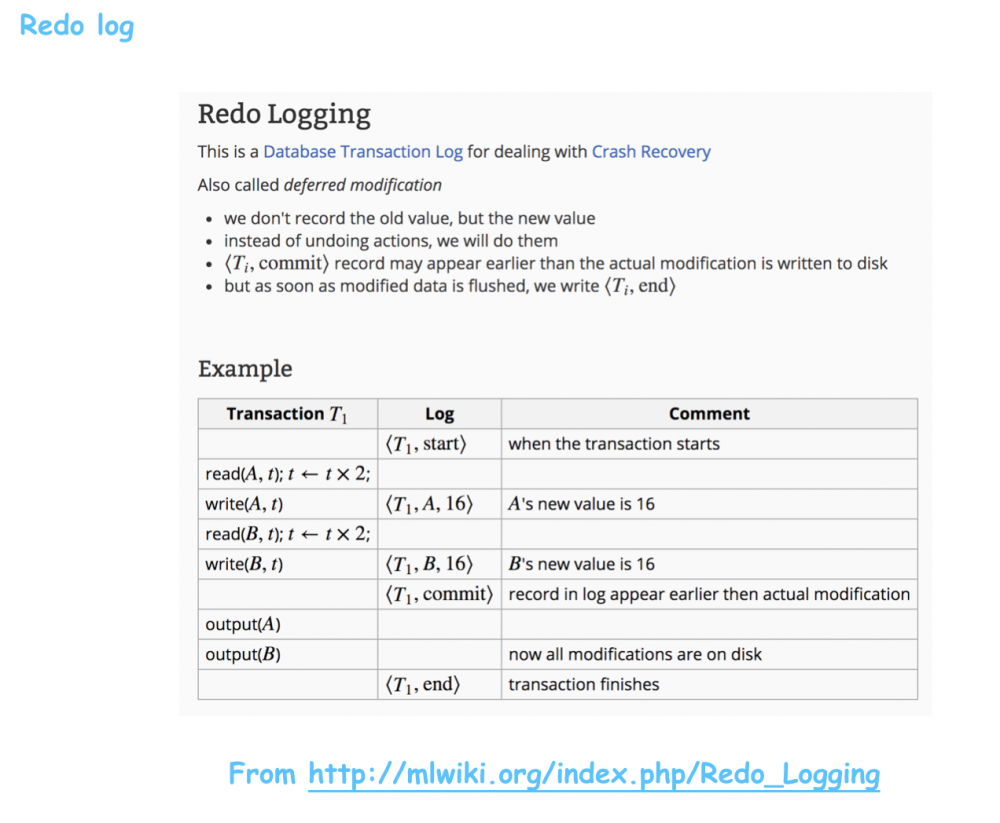
关于事务日志,大家可以看这两篇文章关于 Undo log 和 Redo log 的文章,里头讲的很透彻:

嗯,弄懂了req new和nested的原理,现在是时候回答之前提出的问题了,什么时候需要去修改事务传播级别?
什么时候需要用到Require New
req new的特点在于,当传播级别设置为req new的子方法执行完之后,就会自行提交,不管这个子方法后面的其他代码是不是会抛异常,都不会导致这个子方法的操作被回滚。
这个特点非常适合用在操作记录上,比如当用户调用save方法时,不管是否save成功,你都要记录操作日志,这时候如果使用默认的传播级别require,那么如果记录完操作日志,后面的代码抛异常了,就会导致操作日志的记录被回滚:

什么时候需要用到nested
nested的特点在于,利用还原点来回滚,轻量级,性能好。
利用这个特点,我们可以在批量操作时使用nested:

如上图,假设我们有一大批数据需要进行转换,为了防止某一次transfer方法抛出异常,导致外层事务回滚,我们加上了try-catch.
如果transfer方法设置为默认隔离级别require,那么如果transfer方法抛异常,则由于异常被捕获,失败的那次transfer方法修改的数据不会被回滚。
而如果使用req new,则会导致性能问题,原因跟上文分析的一样。
这时候nested就可以派上用场了,它既可以实现单个方法失败回滚,又无需每次都创建事务,因为它内部使用的是savepoint.
总结
这次分享,我们:
- 研究了Spring声明式事务的原理,了解Spring是如何利用AOP实现事务切面的;
- 比较了声明式事务和编程式事务的优缺点;
- 比较了两种传播级别的区别:Require New vs Nested,并研究了这两种传播级别的适用场景
内容综合了Spring的IOC和AOP的知识,所以如果读者没有了解过这两方面的内容,读起来可能比较吃力。
过几天我再把之前写过的Spring的文章整理一下,按照知识深度循序渐进排好序,分享给大家。
参考
- Spring事务官方文档
- req new的使用场景
- nested的使用场景
- savepoint的原理
- Spring事务的一些坑
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

