深入理解 RxJava2:Scheduler(2)
前言
欢迎来到大家深入理解 RxJava2 系列第二篇,这里先插上一句,本系列文章用的源码都是基于 RxJava 2.2.0 正式版。本篇文章将先与大家一起理解 Scheduler 与 Worker ,顺着 RxJava2 的源码捋一下它们的实现原理。
Scheduler 与 Worker
Scheduler 与 Worker 在 RxJava2 中是一个非常重要的概念,他们是 RxJava 线程调度的核心与基石。用过的人肯定都会了解一些,但是想必了解 Worker 的读者们就不多了。很多人会疑惑,既然有了 Scheduler 可以直接调度 Runnable,为何又强加一个 Worker 的概念,诸位稍安勿躁,跟着笔者的思路一起走下去。
定义
笔者这里展示一下 Scheduler 最核心的定义部分:
public abstract class Scheduler {
@NonNull
public abstract Worker createWorker();
public Disposable scheduleDirect(@NonNull Runnable run) {
...
}
public Disposable scheduleDirect(@NonNull Runnable run, long delay, @NonNull TimeUnit unit) {
...
}
@NonNull
public Disposable schedulePeriodicallyDirect(@NonNull Runnable run, long initialDelay, long period, @NonNull TimeUnit unit) {
...
}
public abstract static class Worker implements Disposable {
@NonNull
public Disposable schedule(@NonNull Runnable run) {
...
}
@NonNull
public abstract Disposable schedule(@NonNull Runnable run, long delay, @NonNull TimeUnit unit);
@NonNull
public Disposable schedulePeriodically(@NonNull Runnable run, final long initialDelay, final long period, @NonNull final TimeUnit unit) {
...
}
}
}
从上面的定义可以看出,Scheduler 本质上就是用来调度 Runnable 的,支持立即、延时和周期形式的调用,而 Worker 是任务的最小单元的载体。在 RxJava2 内部的实现中,通常一个或者多个 Worker 对应一个 ScheduledThreadPoolExecutor 对象,这些暂且不表。
scheduleDirect / schedulePeriodicallyDirect
在 RxJava 1.x 时代, Scheduler 是没有 scheduleDirect/schedulePeriodicallyDirect 的,只能够先 createWorker ,再通过 Worker 来调度任务。这些方法是对 Worker 调用的简化,可以认为是创建了一个只能调度一次任务的 Worker 并立马调度了该任务。在 Scheduler 基类的源码中,也可以看出默认的实现是直接 createWorker 并创建对应的 Task 的(虽然在部分 Scheduler 覆盖的实现上并没有创建 Worker,但是可以认为存在虚拟的 Worker)。
createWorker
一个 Scheduler 可以创建多个 Worker,这两者是一对多的关系,而 Worker 与 Task 也是一对多的关系。
如下图所示:
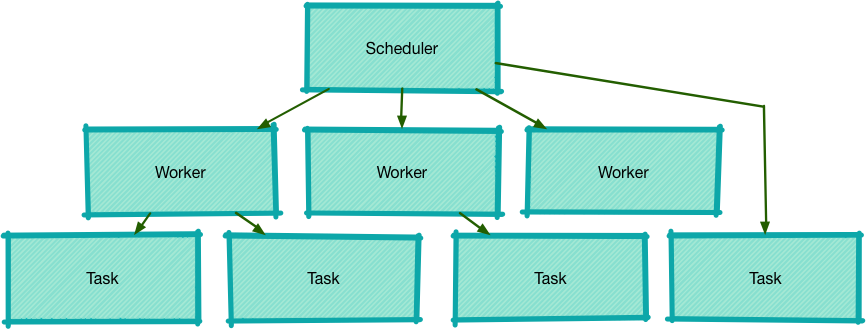
Worke 的存在为了确保两件事:
- 同一个 Worker 创建的 Task 都会确保串行,且立即执行的任务符合先进先出原则。
- Worker 绑定了调用了他的方法的 Runnable,当该 Worker 取消时,基于他的 Task 均被取消
因此当有操作符需要使用 Scheduler 时,可以通过 Worker 来将一系列的 Runnable 统一的调度和取消,最典型的例子就是 observeOn ,下面会详细分析。
Schedulers
RxJava2 默认内置了几种 Scheduler 的实现,适用于不同的场景,这些 Scheduler 均在 Schedulers 类中可以直接获得
| 方法 | 说明 |
|---|---|
| Schedulers.computation() | 适用于计算密集型任务 |
| Schedulers.io() | 适用于 IO 密集型任务 |
| Schedulers.trampoline() | 在某个调用 schedule 的线程执行 |
| Schedulers.newThread() | 每个 Worker 对应一个新线程 |
| Schedulers.single() | 所有 Worker 使用同一个线程执行任务 |
| Schedulers.from(Executor) | 使用 Executor 作为任务执行的线程 |
这里我们挑选两个最常用的 computation / io 源码稍作分析。
NewThreadWorker
NewThreadWorker 在 computation / io / newThread 均有涉及,我们先了解一下这个类。
上面笔者有提到过 Worker 与 ScheduledThreadPoolExecutor 的关系,而这里的 NewThreadWorker 与 ScheduledThreadPoolExecutor 便是一对一的关系。在 NewThreadWorker 构造函数中会通过工厂方法创建一个corePoolSize 为 1 的 ScheduledThreadPoolExecutor 对象并持有之。
ScheduledThreadPoolExecutor 从 JDK1.5 开始存在,这个类继承于
ThreadPoolExecutor ,可以支持即使、延时和周期的任务。但是注意在 ScheduledThreadPoolExecutor 中 maximumPoolSize 参数是无效的,corePoolSize 表示其最大线程数,且它的队列是无界的。这里不再细说该类,否则涉及的就太多了。
有了这个类,RxJava2 实现 Worker 时便是站在了巨人的肩膀上,线程调度可以直接使用该类解决,略微麻烦之处就是封一层 Disposable 的逻辑。
具体细节读者可以从源码一探究竟。
ComputationScheduler
作为计算密集型的 Scheduler, ComputationScheduler 的线程数是与 CPU 核心密切相关的,原因是当线程数远远超过 CPU 核心数目时,CPU 的时间更多的损耗在了线程的上下文切换,因此比较通用的方式是保持最大线程数和 CPU 核心数一致。
最大线程数目
MAX_THREADS = cap(Runtime.getRuntime().availableProcessors(), Integer.getInteger(KEY_MAX_THREADS, 0));
static int cap(int cpuCount, int paramThreads) {
return paramThreads <= 0 || paramThreads > cpuCount ? cpuCount : paramThreads;
}
从上面代码可见 MAX_THREADS 大于 0,但是不超过 CPU 核心数,实际数值也受用户设置的 System Properties 的影响。
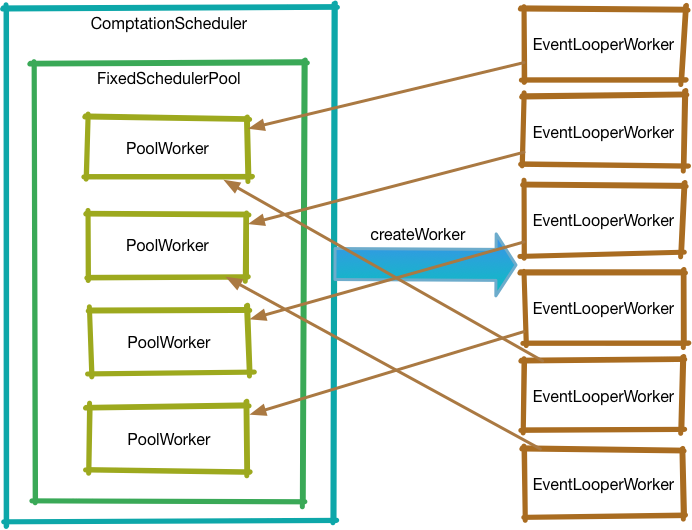
FixedSchedulerPool
顾名思义, FixedSchedulerPool 可以认为是固定数目的真正的 Worker 的缓存池。
确定了 MAX_THREADS 后,在 ComputationScheduler 的构造函数,会创建 FixedSchedulerPool 对象, FixedSchedulerPool 内部会直接创建一个长度为 MAX_THREADS 的 PoolWorker 数组。 PoolWorker 继承自 NewThreadWorker ,但是没有任何额外的代码。
static final class PoolWorker extends NewThreadWorker {
PoolWorker(ThreadFactory threadFactory) {
super(threadFactory);
}
}
也就是说当 FixedSchedulerPool 创建时,已经有 MAX_THREADS 个 corePoolSize 为 1 的 ScheduledThreadPoolExecutor 随之创建。
PoolWorker
从使用角度来说,有了 FixedSchedulerPool 好像就够了,我们只需要每次 createWorker 时从池子里取一个 PoolWorker 并返回即可。
但是这里忽略了一个要点,每个 Worker 是独立的,每个 Worker 内部的任务是绑定在这个 Worker 中的。如果按照上述的做法,暴露出去 PoolWorker ,会出现 2 个问题:
- createWorker 会可能会返回相同的 Worker,导致这个 Worker 被 dispose 后,其内部所有的任务会被一并取消,而违背了不同 Worker 之间的任务的独立性
-
PoolWorker也就是NewThreadWorker被 dispose 后,其关联的ScheduledThreadPoolExecutor被 shutdown,后续再次获取该 Worker 也会导致无法创建任务
EventLoopWorker
为了解决上述的问题,我们需要在 PoolWorker 外再包一层, createWorker 每次都会创建一个 EventLoopWorker 对象。
EventLoopWorker 其实是个代理对象,他会将 Runnable 代理给 FixedSchedulerPool 中取到的 PoolWorker 来调度,并且他会负责管理经由他创建的任务,当自身被取消时,会将创建的任务统统取消。
示意图
IoScheduler
与 ComputationScheduler 恰恰相反,IO 密集型的 Scheduler 线程数是无上限的。这是因为 IO 设备的速度是远远低于 CPU 速度的,在等待 IO 操作时, CPU 往往是闲置的,因此应该创建更多的线程让 CPU 尽可能的利用。当然并不是说线程越多越好,线程数目膨胀到一定程度既会影响 CPU 的效率,也会消耗大量的内存。在 IoScheduler 中,每个 Worker 在空置一段时间后就会被清除以控制线程的数目。
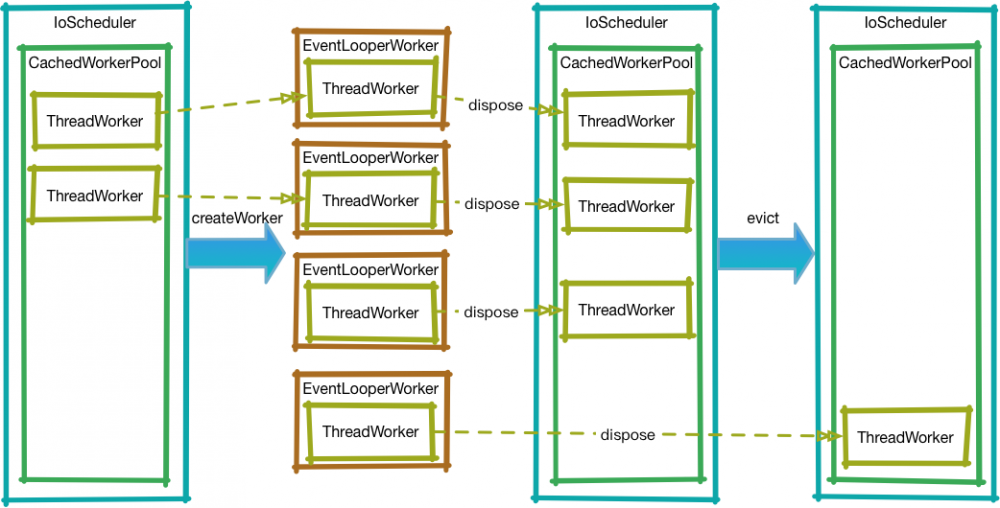
CachedWorkerPool
CachedWorkerPool 是一个变长并定期清理的 ThreadWorker 的缓存池,内部通过一个 ConcurrentLinkedQueue 维护。和 PoolWorker 类似, ThreadWorker 也是继承自 NewThreadWorker :
static final class ThreadWorker extends NewThreadWorker {
private long expirationTime;
ThreadWorker(ThreadFactory threadFactory) {
super(threadFactory);
this.expirationTime = 0L;
}
public long getExpirationTime() {
return expirationTime;
}
public void setExpirationTime(long expirationTime) {
this.expirationTime = expirationTime;
}
}
仅仅是增加了一个 expirationTime 字段,用来标识这个 ThreadWorker 的超时时间。
于此同时,在 CachedWorkerPool 初始化时会传入 Worker 的超时时间,目前是写死的 60 秒。这个超时时间表示 ThreadWorker 闲置后最大存活时间(实际中不保证 60 秒时被回收)。
EventLoopWorker
IoScheduler 中也存在一个 EventLoopWorker 类,它和 ComputationScheduler 中的作用也是类似的:
ThreadWorker
Worker 的管理
- 创建:在闲置队列中查找
ThreadWorker,如果存在则取出,否则new``一个新的ThreadWorker,最后在外面包一层EventLoopWorker```并返回。 - 回收:当
EventLoopWorkerdispose 后,会更新内部的ThreadWorker超时时间,并促使CachedWorkerPool将ThreadWorker加入闲置队列 - 清理:
CachedWorkerPool在初始化时启动定时任务,每隔 60 秒清理队列中超时的ThreadWorker
这里说个细节,因为 CachedWorkerPool 是每隔 60 秒清理一次队列的,因此 ThreadWorker 的存活时间取决于入队的时机,如果一直没有被再次取出,其被实际清理的延迟在 60 - 120 秒之间,有兴趣的读者可以想一想为什么。
示意图
对比
熟悉线程的读者朋友们会发现, ComputationScheduler 与 IoScheduler 很像某些参数下的 ThreadPoolExecutor 。
| ThreadPoolExecutor 参数 | ComputationScheduler(n) | IoScheduler |
|---|---|---|
| corePoolSize | n | 0 |
| maximumPoolSize | n | Integer.MAX_VALUE |
| keepAliveTime | 0 | 60 |
| unit | - | TimeUnit.SECONDS |
| workQueue | LinkedBlockingQueue | SynchronousQueue |
他们对线程的控制外在的表现很相似。
但是实际的线程执行对象不一样:
- ThreadPoolExecutor:Thread
- Scheduler:支持立即、延迟、定时调度任务的对象,通常为 ScheduledThreadPoolExecutor(coreSize = 1)
这两者的对比有助于我们更加深刻地理解 Scheduler 设计的内在逻辑。
结语
Scheduler 是 RxJava 线程的核心概念,RxJava 基于此屏蔽了 Thread 相关的概念,只与 Scheduler / Worker / Runnable 打交道。
本来在笔者计划中还希望继续基于 Scheduler 和大家一起探讨一下 subscribeOn 与 observeOn ,考虑到篇幅问题,这些留待下篇分享。
感觉大家的阅读,欢迎关注笔者公众号,可以第一时间获取更新,同时欢迎留言沟通。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

