JAVA拾遗 — JMH与8个测试陷阱
JMH 是 Java Microbenchmark Harness(微基准测试)框架的缩写(2013年首次发布)。与其他众多测试框架相比,其特色优势在于它是由 Oracle 实现 JIT 的相同人员开发的。在此,我想特别提一下 Aleksey Shipilev (JMH 的作者兼布道者)和他优秀的博客文章。笔者花费了一个周末,将 Aleksey 大神的博客,特别是那些和 JMH 相关的文章通读了几遍,外加一部公开课视频 《”The Lesser of Two Evils” Story》 ,将自己的收获归纳在这篇文章中,文中不少图片都来自 Aleksey 公开课视频。
阅读本文前
本文没有花费专门的篇幅在文中介绍 JMH 的语法,如果你使用 JMH,那当然最好,但如果没听过它,也不需要担心(跟我一周前的状态一样)。我会从 Java Developer 角度来谈谈一些常见的代码测试陷阱,分析他们和操作系统底层以及 Java 底层的关联性,并借助 JMH 来帮助大家摆脱这些陷阱。
通读本文,需要一些操作系统相关以及部分 JIT 的基础知识,如果遇到陌生的知识点,可以留意章节中的维基百科链接,以及笔者推荐的博客。
笔者能力有限,未能完全理解 JMH 解决的全部问题,如有错误以及疏漏欢迎留言与我交流。
初识 JMH
测试精度

Aleksey 给出了 micro 测试的耗时数量级,这意味着 JMH 测试可以达到 微秒 级别的的精度。
这样几个级别的测试所面临的挑战也是不同的。
- 毫秒级别的测试并不是很困难
- 微秒级别的测试是具备挑战性的,但并非无法完成,JMH 就做到了
- 纳秒级别的测试,目前还没有办法精准测试
- 皮秒级别…Holy Shit
图解:
Linpack : Linpack benchmark 一类基础测试,度量系统的浮点计算能力
SPEC:Standard Performance Evaluation Corporation 工业界的测试标准组织
pipelining:系统总线通信的耗时
聊聊 Benchmark
测试在不同的维度可以分为很多类:集成测试,单元测试,API 测试,压力测试… 而 benchmark 通常译为基准测试(性能测试)。你可以在很多开源框架的包层级中发现 benchmark,用于阐释该框架的基准水平,从而量化其性能。
基准测试又可以细分为 :Micro benchmark,Kernels,Synthetic benchmark,Application benchmarks.etc.本文的主角便属于 Benchmark 的 Micro benchmark。基础测试分类详细介绍 here
为什么需要有 Benchmark?
If you cannot measure it, you cannot improve it. –Lord Kelvin
俗话说,没有实践就没有发言权,Benchmark 为应用提供了数据支持,是评价和比较方法好坏的基准,Benchmark 的准确性,多样性便显得尤为重要。
Benchmark 作为应用框架,产品的基准画像,存在统一的标准,避免了不同测评对象自说自话的尴尬,应用框架各自使用有利于自身场景的测评方式必然不可取,例如 Standard Performance Evaluation Corporation (SPEC) 即上文“测试精度”提到的词便是工业界的标准组织之一,JMH 的作者 Aleksey 也是其中的成员。
JMH 长这样
@Benchmark
public void measure() {
// this method was intentionally left blank.
}
使用起来和单元测试一样的简单
它的测评结果
Benchmark Mode Cnt Score Error Units JMHSample_HelloWorld.measure thrpt 5 3126699413.430 ± 179167212.838 ops/s
为什么需要 JMH 测试
你可能会想,我用下面的方式来测试有什么不好?
long start = System.currentTimeMillis(); measure(); System.out.println(System.currentTimeMillis()-start);
难道 JMH 不是这么测试的吗?
@Benchmark
public void measure() {
}
事实上,这是本文的核心问题,建议在阅读时时刻带着这样的疑问,为什么不使用第一种方式来测试。 在下面的章节中,我将列举诸多的测试陷阱,他们都会为这个问题提供论据,这些陷阱会启发那些对“测试”不感冒的 Java Developer。相信你观看过后,会积极地拥抱 JMH 。
预热
在初识 JMH 小节的最后,花少量的篇幅来给 JMH 实战开个头,介绍一个 Java 测试中比较老生常谈的话题 — 预热(warm up),它存在于下面所有的测试中。
«Warmup» = waiting for the transient responses to settle down
特别是在编写 Java 测试程序时,预热从来都是不可或缺的一环,它使得结果更加真实可信。
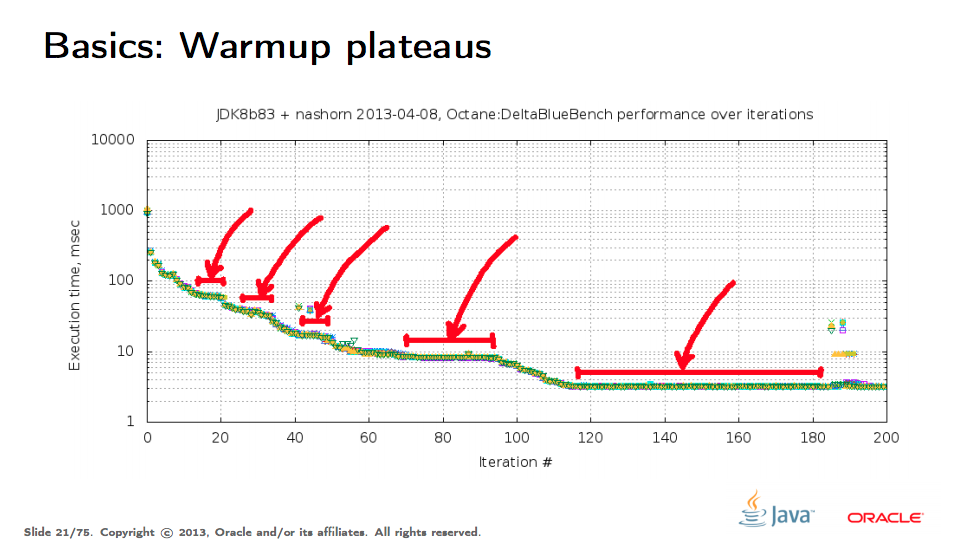
上图展示了一个样例测评程序随着迭代次数增多执行耗时变化的曲线,可以发现在 120 次迭代之后,性能才趋于最终稳定,这意味着:预热阶段需要有至少 120 次迭代,才能得到准确的基础测试报告。(JVM 初始化时的一些准备工作以及 JIT 优化是主要原因,但不是唯一原因)
使用 JMH 解决 12 个测试陷阱
陷阱1:死码消除

measureWrong 方法想要测试 Math.log 的性能,得到的结果和空方法 baseline 一致,而 measureRight 相比 measureWrong 多了一个 return,正确的得到了测试结果。
这是由于 JIT 擅长删除“无效”的代码,这给我们的测试带来了一些意外,当你意识到 DCE 现象后,应当有意识的去消费掉这些孤立的代码,例如 return。JMH 不会自动实施对冗余代码的消除。
死码消除 这个概念很多人其实并不陌生,注释的代码,不可达的代码块,可达但不被使用的代码等等,我这里补充一些 Aleksey 提到的概念,用以阐释为何一般测试方法难以避免引用对象发生死码消除现象:
- Fast object combinator.
- Need to escape object to limit thread-local optimizations.
- Publishing the object ⇒ reference heap write ⇒ store barrier.
很绝望,个人水平有限,我没能 get 到这些点,只能原封不动地贴给大家看了。
JMH 提供了专门的 API — Blockhole 来避免死码消除问题。
@Benchmark
public void measureRight(Blackhole bh) {
bh.consume(Math.log(PI));
}
陷阱2:常量折叠与常量传播
常量折叠 (Constant folding) 是一个在编译时期简化常数的一个过程,常数在表示式中仅仅代表一个简单的数值,就像是整数 2 ,若是一个变数从未被修改也可作为常数,或者直接将一个变数被明确地被标注为常数,例如下面的描述:
i = 320 * 200 * 32;
多数的现代编译器不会真的产生两个乘法的指令再将结果储存下来,取而代之的,他们会辨识出语句的结构,并在编译时期将数值计算出来(在这个例子,结果为 2,048,000)。
有些编译器,常数折叠会在初期就处理完,例如 Java 中的 final 关键字修饰的变量就会被特殊处理。而将常数折叠放在较后期的阶段的编译器,也相当常见。
private double x = Math.PI;
// 编译器会对 final 变量特殊处理
private final double wrongX = Math.PI;
@Benchmark
public double baseline() { // 2.220 ± 0.352 ns/op
return Math.PI;
}
@Benchmark
public double measureWrong_1() { // 2.220 ± 0.352 ns/op
// 错误,结果可以被预测,会发生常量折叠
return Math.log(Math.PI);
}
@Benchmark
public double measureWrong_2() { // 2.220 ± 0.352 ns/op
// 错误,结果可以被预测,会发生常量折叠
return Math.log(wrongX);
}
@Benchmark
public double measureRight() { // 22.590 ± 2.636 ns/op
return Math.log(x);
}
经过 JMH 可以验证这一点:只有最后的 measureRight 正确测试出了 Math.log 的性能,measureWrong_1,measureWrong_2 都受到了常量折叠的影响。
常数传播(Constant propagation ) 是一个替代表示式中已知常数的过程,也是在编译时期进行,包含前述所定义,内建函数也适用于常数,以下列描述为例:
int x = 14; int y = 7 - x / 2; return y * (28 / x + 2);
传播可以理解变量的替换,如果进行持续传播,上式会变成:
int x = 14; int y = 0; return 0;
陷阱3:永远不要在测试中写循环
这个陷阱对我们做日常测试时的影响也是巨大的,所以我直接将他作为了标题:永远不要在测试中写循环!
本节设计不少知识点, 循环展开 (loop unrolling),JIT & OSR 对循环的优化。对于前者循环展开的定义,建议读者直接查看 wiki 的定义,而对于后者 JIT & OSR 对循环的优化,推荐两篇 R 大的知乎回答:
循环长度的相同、循环体代码相同的两次for循环的执行时间相差了100倍?
OSR(On-Stack Replacement)是怎样的机制?
对于第一个回答,建议不要看问题,直接看答案;第二个回答,阐释了 OSR 都对循环做了哪些手脚。
测试一个耗时较短的方法,入门级程序员(不了解动态编译的同学)会这样写,通过循环放大,再求均值。
public class BadMicrobenchmark {
public static void main(String[] args) {
long startTime = System.nanoTime();
for (int i = 0; i < 10_000_000; i++) {
reps();
}
long endTime = System.nanoTime();
System.out.println("ns/ops (ns): " + ((endTime - startTime)/10_000_000));
}
}
实际上,这段代码的结果是不可预测的,太多影响因子会干扰结果。原理暂时不表,通过 JMH 来看看几个测试方法,下面的 Benchmark 尝试对 reps 方法迭代不同的次数,想从中获得 reps 真实的性能。(注意,在 JMH 中使用循环也是不可取的,除非你是 Benchmark 方面的专家,否则在任何时候,你都不应该写循环)
int x = 1;
int y = 2;
@Benchmark
public int measureRight() {
return (x + y);
}
private int reps(int reps) {
int s = 0;
for (int i = 0; i < reps; i++) {
s += (x + y);
}
return s;
}
@Benchmark
@OperationsPerInvocation(1)
public int measureWrong_1() {
return reps(1);
}
@Benchmark
@OperationsPerInvocation(10)
public int measureWrong_10() {
return reps(10);
}
@Benchmark
@OperationsPerInvocation(100)
public int measureWrong_100() {
return reps(100);
}
@Benchmark
@OperationsPerInvocation(1000)
public int measureWrong_1000() {
return reps(1000);
}
@Benchmark
@OperationsPerInvocation(10000)
public int measureWrong_10000() {
return reps(10000);
}
@Benchmark
@OperationsPerInvocation(100000)
public int measureWrong_100000() {
return reps(100000);
}
结果如下:
Benchmark Mode Cnt Score Error Units JMHSample_11_Loops.measureRight avgt 5 2.343 ± 0.199 ns/op JMHSample_11_Loops.measureWrong_1 avgt 5 2.358 ± 0.166 ns/op JMHSample_11_Loops.measureWrong_10 avgt 5 0.326 ± 0.354 ns/op JMHSample_11_Loops.measureWrong_100 avgt 5 0.032 ± 0.011 ns/op JMHSample_11_Loops.measureWrong_1000 avgt 5 0.025 ± 0.002 ns/op JMHSample_11_Loops.measureWrong_10000 avgt 5 0.022 ± 0.005 ns/op JMHSample_11_Loops.measureWrong_100000 avgt 5 0.019 ± 0.001 ns/op
如果不看事先给出的错误和正确的提示,上述的结果,你会选择相信哪一个?实际上跑分耗时从 2.358 随着迭代次数变大,降为了 0.019。手动测试循环的代码 BadMicrobenchmark 也存在同样的问题,实际上它没有做预热,效果只会比 JMH 测试循环更加不可信。
Aleksey 在视频中给出结论:假设单词迭代的耗时是 ns. 在 JIT,OSR,循环展开等因素的多重作用下,多次迭代的耗时理论值为 ns, 其中 ∈ [0; +∞)。
正确的测试循环的姿势可以看这里: here
陷阱4:使用 Fork 做对比测试
相信我,这个陷阱中涉及到的例子绝对是 JMH sample 中最诡异的,并且我还没有找到科学的解释(说实话视频中这一段我尝试听了好几遍,没听懂,原谅我的听力)
首先定义一个 Counter 接口,并实现了两份代码完全相同的实现类:Counter1,Counter2
public interface Counter {
int inc();
}
public class Counter1 implements Counter {
private int x;
@Override
public int inc() {
return x++;
}
}
public class Counter2 implements Counter {
private int x;
@Override
public int inc() {
return x++;
}
}
接着让他们在 同一个 VM 中按照先手顺序进行评测:
public int measure(Counter c) {
int s = 0;
for (int i = 0; i < 10; i++) {
s += c.inc();
}
return s;
}
/*
* These are two counters.
*/
Counter c1 = new Counter1();
Counter c2 = new Counter2();
/*
* We first measure the Counter1 alone...
* Fork(0) helps to run in the same JVM.
*/
@Benchmark
@Fork(0)
public int measure_1_c1() {
return measure(c1);
}
/*
* Then Counter2...
*/
@Benchmark
@Fork(0)
public int measure_2_c2() {
return measure(c1);
}
/*
* Then Counter1 again...
*/
@Benchmark
@Fork(0)
public int measure_3_c1_again() {
return measure(c1);
}
这一个例子中多了一个 Fork 注解,让我来简单介绍下它。Fork 这个关键字顾名思义,是用来将运行环境复制一份的意思,在我们之前的多个测试中,实际上每次测评都是默认使用了 相互隔离的,完全一致 的测评环境,这得益于 JMH。每个试验运行在单独的 JVM 进程中。也可以指定(额外的) JVM 参数,例如这里为了演示运行在同一个 JVM 中的弊端,特地做了反面的教材:Fork(0)。试想一下 c1,c2,c1 again 的耗时结果会如何?
Benchmark Mode Cnt Score Error Units JMHSample_12_Forking.measure_1_c1 avgt 5 2.518 ± 0.622 ns/op JMHSample_12_Forking.measure_2_c2 avgt 5 14.080 ± 0.283 ns/op JMHSample_12_Forking.measure_3_c1_again avgt 5 13.462 ± 0.164 ns/op JMHSample_12_Forking.measure_4_forked_c1 avgt 5 3.861 ± 0.712 ns/op JMHSample_12_Forking.measure_5_forked_c2 avgt 5 3.574 ± 0.220 ns/op
你会不会感到惊讶,第一次运行的 c1 竟然耗时最低,在我的认知中,JIT 起码会启动预热的作用,无论如何都不可能先运行的方法比之后的方法快这么多!但这个结果也和 Aleksey 视频中介绍的相符。
JMH samples 中的这个示例主要还是想要表达同一个 JVM 中运行的测评代码会互相影响,从结果也可以发现:c1,c2,c1_again 的实现相同,跑分却不同,因为运行在同一个 JVM 中;而 forked_c1 和 forked_c2 则表现出了一致的性能。所以没有特殊原因,Fork 的值一般都需要设置为 >0。
陷阱5:方法内联
熟悉 C/C++ 的朋友不会对方法内联感到陌生,方法内联就是把目标方法的代码“复制”到发起调用的方法之中,避免发生真实的方法调用(减少了操作指令周期)。在 Java 中,无法手动编写内联方法,但 JVM 会自动识别热点方法,并对它们使用方法内联优化。一段代码需要执行多少次才会触发 JIT 优化通常这个值由 -XX:CompileThreshold 参数进行设置:
- 1、使用 client 编译器时,默认为1500;
- 2、使用 server 编译器时,默认为10000;
但是一个方法就算被 JVM 标注成为热点方法,JVM 仍然不一定会对它做方法内联优化。其中有个比较常见的原因就是这个方法体太大了,分为两种情况。
-XX:MaxFreqInlineSize=N -XX:MaxInlineSize=N
我们可以通过增加这个大小,以便更多的方法可以进行内联;但是除非能够显著提升性能,否则不推荐修改这个参数。因为更大的方法体会导致代码内存占用更多,更少的热点方法会被缓存,最终的效果不一定好。
如果想要知道方法被内联的情况,可以使用下面的JVM参数来配置
-XX:+PrintCompilation //在控制台打印编译过程信息 -XX:+UnlockDiagnosticVMOptions //解锁对JVM进行诊断的选项参数。默认是关闭的,开启后支持一些特定参数对JVM进行诊断 -XX:+PrintInlining //将内联方法打印出来
方法内联的其他隐含条件
final、private、static
方法内联也可能对 Benchmark 产生影响;或者说有时候我们为了优化代码,而故意触发内联,也可以通过 JMH 来和非内联方法进行性能对比:
public void target_blank() {
// this method was intentionally left blank
}
@CompilerControl(CompilerControl.Mode.DONT_INLINE)
public void target_dontInline() {
// this method was intentionally left blank
}
@CompilerControl(CompilerControl.Mode.INLINE)
public void target_inline() {
// this method was intentionally left blank
}
Benchmark Mode Cnt Score Error Units JMHSample_16_CompilerControl.blank avgt 3 0.323 ± 0.544 ns/op JMHSample_16_CompilerControl.dontinline avgt 3 2.099 ± 7.515 ns/op JMHSample_16_CompilerControl.inline avgt 3 0.308 ± 0.264 ns/op
可以发现,内联与不内联的性能差距是巨大的,有一些空间换时间的味道,在 JMH 中使用 CompilerControl.Mode 来控制内联是否开启。
陷阱6:伪共享与缓存行
又遇到了我们的老朋友:CPU Cache 和缓存行填充。这个并发性能杀手,我在之前的文章中专门介绍过,如果你没有看过,可以戳这里: JAVA 拾遗 — CPU Cache 与缓存行 。在 Benchmark 中,有时也不能忽视缓存行对测评的影响。
受限于篇幅,在此不展开有关伪共享的陷阱,完整的测评可以戳这里: JMHSample_22_FalseSharing
JMH 为解决伪共享问题,提供了 @State 注解,但并不能在单一对象内部对个别的字段增加,如果有必要,可以使用并发包中的 @Contended 注解来处理。
Aleksey 曾为 Java 并发包提供过优化,其中就包括 @Contended 注解。
陷阱7:分支预测
分支预测(Branch Prediction)是这篇文章中介绍的最后一个 Benchmark 中的“捣蛋鬼”。还是从一个具体的 Benchmark 中观察结果。下面的代码尝试遍历了两个长度相等的数组,一个有序,一个无序,并在迭代时加入了一个判断语句,这是分支预测的关键:if(v > 0)
private static final int COUNT = 1024 * 1024;
private byte[] sorted;
private byte[] unsorted;
@Setup
public void setup() {
sorted = new byte[COUNT];
unsorted = new byte[COUNT];
Random random = new Random(1234);
random.nextBytes(sorted);
random.nextBytes(unsorted);
Arrays.sort(sorted);
}
@Benchmark
@OperationsPerInvocation(COUNT)
public void sorted(Blackhole bh1, Blackhole bh2) {
for (byte v : sorted) {
if (v > 0) { //关键
bh1.consume(v);
} else {
bh2.consume(v);
}
}
}
@Benchmark
@OperationsPerInvocation(COUNT)
public void unsorted(Blackhole bh1, Blackhole bh2) {
for (byte v : unsorted) {
if (v > 0) { //关键
bh1.consume(v);
} else {
bh2.consume(v);
}
}
}
Benchmark Mode Cnt Score Error Units JMHSample_36_BranchPrediction.sorted avgt 25 2.752 ± 0.154 ns/op JMHSample_36_BranchPrediction.unsorted avgt 25 8.175 ± 0.883 ns/op
从结果看,有序数组的遍历比无序数组的遍历快了 2-3 倍。关于这点的介绍,最佳的解释来自于 Stack Overflow 一个 2w 多赞的答案: Why is it faster to process a sorted array than an unsorted array?

假设我们是在 19 世纪,而你负责为火车选择一个方向,那时连电话和手机还没有普及,当火车开来时,你不知道火车往哪个方向开。于是你的做法(算法)是:叫停火车,此时火车停下来,你去问司机,然后你确定了火车往哪个方向开,并把铁轨扳到了对应的轨道。
还有一个需要注意的地方是,火车的惯性是非常大的,所以司机必须在很远的地方就开始减速。当你把铁轨扳正确方向后,火车从启动到加速又要经过很长的时间。
那么是否有更好的方式可以减少火车的等待时间呢?
有一个非常简单的方式,你提前把轨道扳到某一个方向。那么到底要扳到哪个方向呢,你使用的手段是——“瞎蒙”:
- 如果蒙对了,火车直接通过,耗时为 0。
- 如果蒙错了,火车停止,然后倒回去,你将铁轨扳至反方向,火车重新启动,加速,行驶。
如果你很幸运,每次都蒙对了,火车将从不停车,一直前行!如果不幸你蒙错了,那么将浪费很长的时间。
虽然不严谨,但你可以用同样的道理去揣测 CPU 的分支预测,有序数组使得这样的预测大部分情况下是正确的,所以带有判断条件时,有序数组的遍历要比无序数组要快。
这同时也启发我们:在大规模循环逻辑中要尽量避免大量判断(是不是可以抽取到循环外呢?)。
陷阱8:多线程测试
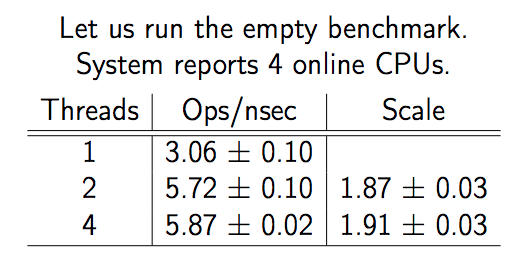
在 4 核的系统之上运行一个测试方法,得到如上的测试结果, Ops/nsec 代表了单位时间内的运行次数,Scale 代表 2,4 线程相比 1 线程的运行次数倍率。
这个图可供我们提出两个问题:
- 为什么 2 线程 -> 4 线程几乎没有变化?
-
为什么 2 线程相比 1 线程只有 1.87 倍的变化,而不是 2 倍?
1 电源管理
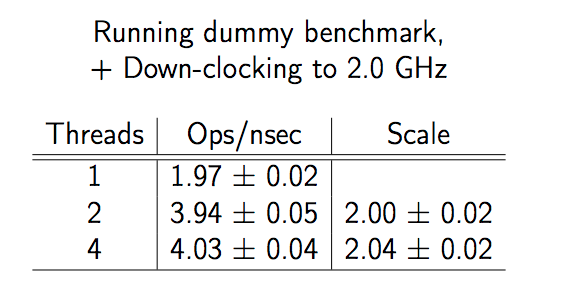
第一个影响因素便是多线程测试会受到操作系统电源管理(Power Management)的影响,许多系统存在能耗和性能的优化管理。 (Ex: cpufreq, SpeedStep, Cool&Quiet, TurboBoost)
当我们主动对机器进行降频之后,整体性能发生下降,但是 Scale 在线程数 1 -> 2 的过程中变成了严谨的 2 倍。
这样的问题并非无法规避,补救方法便是禁用电源管理, 保证 CPU 的时钟频率 。
JMH 通过长时间运行,保证线程不出现 park(time waiting) 状态,来保证测试的精准性。
2 操作系统调度和分时调用模型
造成多线程测试陷阱的第二个问题,需要从线程调度模型出发来理解:分时调度模型和抢占式调度模型。
分时调度模型是指让所有的线程轮流获得 CPU 的使用权,并且平均分配每个线程占用的 CPU 的时间片,这个也比较好理解;抢占式调度模型,是指优先让可运行池中优先级高的线程占用 CPU,如果可运行池中的线程优先级相同,那么就随机选择一个线程,使其占用 CPU。处于运行状态的线程会一直运行,直至它不得不放弃 CPU。一个线程会因为以下原因而放弃 CPU。
需要注意的是,线程的调度不是跨平台的,它不仅仅取决于 Java 虚拟机,还依赖于操作系统。在某些操作系统中,只要运行中的线程没有遇到阻塞,就不会放弃 CPU;在某些操作系统中,即使线程没有遇到阻塞,也会运行一段时间后放弃 CPU,给其它线程运行的机会。
无论是那种模型,线程上下文的切换都会造成损耗。到这儿为止,还是只回答了第一个问题:为什么 2 线程相比 1 线程只有 1.87 倍的变化,而不是 2 倍?
由于上述的两个图我都是从 Aleksey 的视频中抠出来的,并不清楚他的实际测试用例,对于 2 -> 4 线程性能差距并不大只能理解为系统过载,按道理说 4 核的机器,运行 4 个线程应该不至于只比 2 个线程快这么一点。
对于线程分时调用以及线程调度带来的不稳定性,JMH 引入了 bogus iterations 的概念,它保障了在多线程测试过程中,只在线程处于忙碌状态的过程中进行测量。
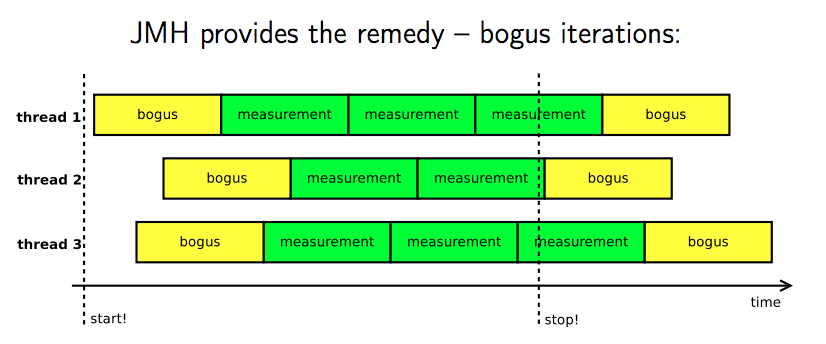
bogus iterations 这个值得一提,我理解为“伪迭代”,并且也只在 JVM 的注释以及 Aleksey 的几个博客中有介绍,可以理解为 JMH 的内部原理的专用词。
总结
本文花了大量的篇幅介绍了 JMH 存在的意义,以及 JMH sample 中提到的诸多陷阱,这些陷阱会非常容易地被那些不规范的测评程序所触发。我觉得作为 Java 语言的使用者,起码有必要了解这些现象的存在,毕竟 JMH 已经帮你解决了诸多问题了,你不用担心预热问题,不用自己写比较 low 的循环去评测,规避这些测试陷阱也变得相对容易。
实际上,本文设计的知识点,仅仅是 Aleksey 博客中的内容、 JMH 的 38 个 sample 的冰山一角,有兴趣的朋友可以戳这里查看所有的 JMH sample
陷阱内心 os:像我这么diao的陷阱,还有 30 个!
例如 Kafka 这样优秀的开源框架,提供了专门的 module 来做 JMH 的基础测试。尝试使用 JMH 作为你的 Benchmark 工具吧。
欢迎关注我的微信公众号:「Kirito的技术分享」,关于文章的任何疑问都会得到回复,带来更多 Java 相关的技术分享。

正文到此结束
- 本文标签: 编译 线程 数据 空间 开发 core ORM JVM java 教材 UI 注释 操作系统 src constant 回答 Oracle 配置 时间 参数 client 微信公众号 Lua tar 标题 代码 组织 Developer 文章 模型 cat 多线程 DOM 开源 ACE id https 产品 API 遍历 总结 博客 IO 并发 ip 压力 管理 程序员 final 删除 图片 单元测试 测试 进程 IDE App 锁 http cache 缓存
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

