原 荐 Uber 开源分布式追踪工具:JVM Profiler
- 《JVM Profiler: An Open Source Tool for Tracing Distributed JVM Applications at Scale 》
Apache Spark 计算框架已经被广泛用来构建大规模数据应用。对 Uber 而言, 数据是战略决策和产品开发的核心。为了更好地利用这些数据, Uber 需要管理遍布全球的 Spark 实例。 Spark 使得数据技术更易于访问, 如果要做到对 Spark 应用程序的进行合理的资源分配, 优化数据基础架构的操作效率, 就需要对这些系统有更细粒度的洞察力, 即识别其资源使用模式。为了在不改变用户代码的情况下也能达成上述目标, Uber Engineering 团队构建并开源了 JVM Profiler —— 一个分布式探查器,用于收集性能和资源使用率指标为进一步分析提供服务。尽管它是为 Spark 应用而构建的, 但它的通用实现使其适用于任何基于 Java 虚拟机 ( Java virtual machine ,JVM) 的服务或应用程序。
Profiling challenges
Uber Engineering 每天的常规工作是支持数以万计的应用程序、运行在成千上万的机器上。随着技术栈的增长, 我们很快意识到现有的性能分析和优化方案无法满足需要。特别是:
目标1:应用级指标监控
- Correlate metrics across a large number of processes at the application level
分布式环境中存在大量进程需要度量,包括在同一服务器上运行着多个 Spark 应用、多服务器上运行的 Spark 应用有大量的进程 (例如数以千计的执行者 executors ) , 如 图1 所示:
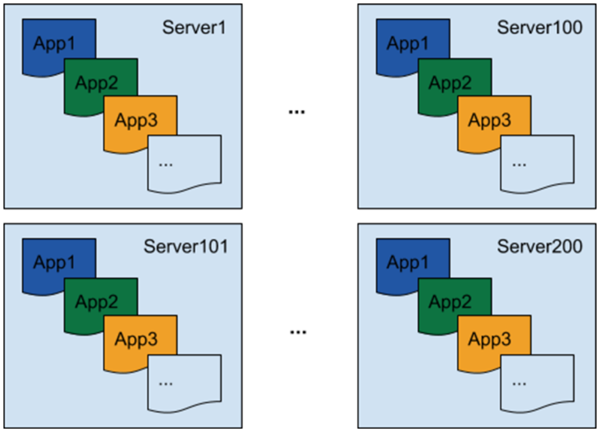
Uber 现有的工具只能做到服务器级别的度量(server-level metrics)并且不能针对单个应用做到精确测量。我们需要一个解决方案, 可以收集每个过程的度量值, 并将它们与每个应用程序的进程关联起来。此外, 我们不知道这些过程将在何时启动, 以及它们将运行多长时间。为了能够在这种环境中收集度量, 需要在每个进程中自动启动探查器。
目标2:不侵入用户代码
- Make metrics metrics collection non-intrusive for arbitrary user code
目前,Apache Spark 和 Apache Hadoop 库不支持导出性能指标; 但是在通常情况下, 我们需要在不更改用户或框架代码的情况下收集这些指标。例如, 如果在 Hadoop 文件系统 (Hadoop Distributed File System ,HDFS) NameNode 上遇到高时延的情况, 我们希望检查每个 Spark 应用中的延迟情况, 以确保这类问题不再重复出现。由于 NameNode 客户端代码嵌入到了 Spark 库中, 因此修改其源代码以添加特定度量是很麻烦的。为了跟上持续增长数据基础架构, 我们需要能够在任何时候对任何应用程序进行测量, 而不进行代码更改。此外, 实现一个非侵入性的度量值收集过程将使我们能够在加载中动态地向 Java 方法中注入代码。
JVM Profiler 简介
为了解决上述两个难题, Uber Engineering 团队构建并开源了 JVM Profiler 。现有的同类开源工具, 比如 Etsy 的 statsd-jvm-profiler , 可以在单个应用程序级别收集度量, 但是不提供动态代码注入收集度量的能力。在这些工具的启发下, 我们的探查器提供了新功能, 如任意 Java 方法/参数分析。
JVM Profiler 由三项主要功能组成, 它使收集性能和资源使用率指标变得更容易, 然后可以将这些指标 (如 Apache Kafka) 提供给其他系统进行进一步分析:
- 代理功能 ( java agent ) : 支持用户以分布式的方式收集各种指标 (例如如 CPU/内存利用率) ,用于 JVM 进程的堆栈跟踪。
- 高级分析功能(Advanced profiling capabilities): 支持跟踪任意 Java 方法和用户代码中的参数, 而不进行任何实际的代码更改。此功能可用于跟踪 Spark 应用的 HDFS NameNode RPC 调用延迟, 并标识慢速方法调用。它还可以跟踪每个 Spark 应用读取或写入的 HDFS 文件路径, 用以识别热文件后进一步优化。
- 数据分析报告( Data analytics reporting ): 使用 JVM Profile 可以将指标数据推送给 Kafka topics 和 Apache Hive tables , 提高数据分析的速度和灵活性。
JVM Profiler 典型用例
JVM Profiler 支持各种用例, 最典型的是能够检测任意 Java 代码。基于简单的配置, JVM Profiler 就可以附加到 Spark 应用中的每个执行者(executor)收集 Java 方法运行时度量。下面, 我们对其中的一些用例进行了讨论:
- Right-size executor : JVM Profiler 中的内存度量支持跟踪每个执行者的实际内存使用情况。借此 可以在 Spark 应用中 ”executor-memory" 设置最优参数。
- 监视 HDFS NameNode RPC 延迟: 例如在 Spark 应用中对类 org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB 的方法进行了分析并确定 NameNode 调用的延迟。Uber 每天都要监控5万多个 Spark 应用, 其中有数以亿计的这种 RPC 调用。
- 监视驱动程序丢弃的事件: 例如监视 org.apache.spark.scheduler.LiveListenerBus.onDropEvent, 跟踪 Spark 驱动程序事件队列太长、队列删除事件。
- 跟踪数据沿袭: 例如分析 Java 方法上的文件路径参数 ( org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.getBlockLocations , org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.addBlock ) , 可以跟踪哪些文件是由 Spark 应用读取和写入的。
JVM Profiler 实现
JVM Profiler 具有非常简单且可扩展的设计。可以很容易地添加其他 Profiler 收集更多的指标, 也能部署自定义 reporter 向不同的系统发送数据指标。
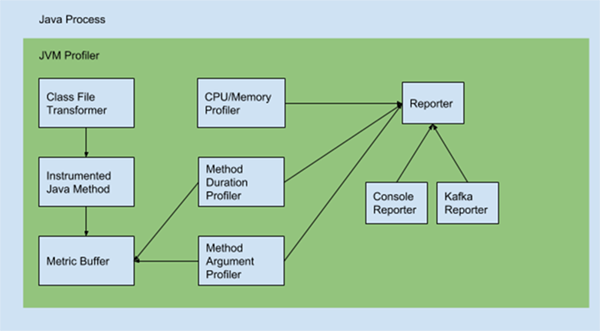
一旦启动 JVM Profiler 代码即通过代理参数加载到一个 Java 进程中。它由三个主要部分组成:
Class File Transformer类文件转换器介由进程内的 Java 方法字节码监视任意用户代码并在内部度量缓冲区中保存度量。
Metric Profilers
- CPU/Memory Profiler: 通过 JMX 收集 CPU/内存利用率并发送给 reporter
- Method Duration Profiler: 从度量缓冲区读取方法时延 (method duration) 并发送给 reporter
- Method Argument Profiler: 从度量缓冲区读取方法参数值(method argument )并发送给 reporter
Reporters
- Console Reporter: 控制台输出
- Kafka Reporter: 发送到 Kafka topics
JVM Profiler 扩展
通过 -javaagent 选项可以构建自己的 reporter , 例如:
java -javaagent:jvm-profiler-0.0.5.jar=reporter=com.uber.profiling.reporters.CustomReporter
数据基础设施整合
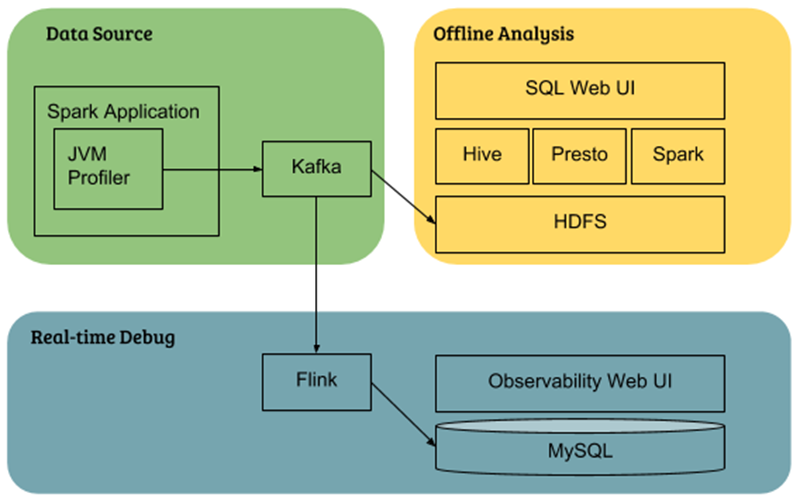
Uber 将 JVM Profiler 与自己的数据基础设施进行整合:
- Cluster-wide data analysis : 集群数据分析中指标数据首先推送到 Kafka 并存储于 HDFS, 用户最终通过 Hive/Presto/Spark 查询。
- Real-time Spark application debugging : Uber 使用 Flink 实现单个应用的实时数据聚合并写入到 MySQL 数据库,这样用户就可以通过基于 Web 的接口查询指标。
JVM Profiler 应用
示例:使用 JVM Profiler 跟踪一个简单的 Java 应用
首先,git clone 项目代码
git clone https://github.com/uber-common/jvm-profiler.git
然后,mvn package 构建 jvm-profiler jar
mvn clean package
最后,调用 JAR 运行 JVM Profiler (e.g.target/jvm-profiler-0.0.5.jar)
java -javaagent:target/jvm-profiler-0.0.5.jar=reporter=com.uber.profiling.reporters.ConsoleOutputReporter -cp target/jvm-profiler-0.0.5.jar com.uber.profiling.examples.HelloWorldApplication
上述命令行将运行一个简单的 Java 应用并通过控制台输出性能和资源使用情况。例如:
Nill
JVM Profiler 也能通过命令行将指标数据发送到 Kafka topic :
Nill
Use the profiler to profile the Spark application
示例:基于 JVM Profiler 跟踪 Spark 应用
假定我们已经有一个 HDFS 集群,将 JVM Profiler JAR 上传到 HDFS
hdfs dfs -put target/jvm-profiler-0.0.5.jar hdfs://hdfs_url/lib/jvm-profiler-0.0.5.jar
使用 spark-submit 命令行启动 Spark 应用
spark-submit --deploy-mode cluster --master yarn --conf spark.jars=hdfs://hdfs_url/lib/jvm-profiler-0.0.5.jar --conf spark.driver.extraJavaOptions=-javaagent:jvm-profiler-0.0.5.jar --conf spark.executor.extraJavaOptions=-javaagent:jvm-profiler-0.0.5.jar --class com.company.SparkJob spark_job.jar
指标查询
Uber 将指标数据发送到 Kafka topic 和后台数据管线并自动存储于 Hive tables 。用户可以设置类似的管线并使用 SQL 查询指标数据。用户也可以编写自己的 reporter , 将指标发送到 SQL 数据库(如 MySQL)。Hive table 查询示例,包含每个进程的内存和 CPU 指标:

Next
Uber 将 JVM Profiler 应用到自己最大 Spark 应用 (1000 多个 executor ), 在该过程中将每个 executor 分配的内存减少了 2GB (从 7GB 降低到 5GB )。对于整个 Spark 应用来说合计节省 2TB 内存。
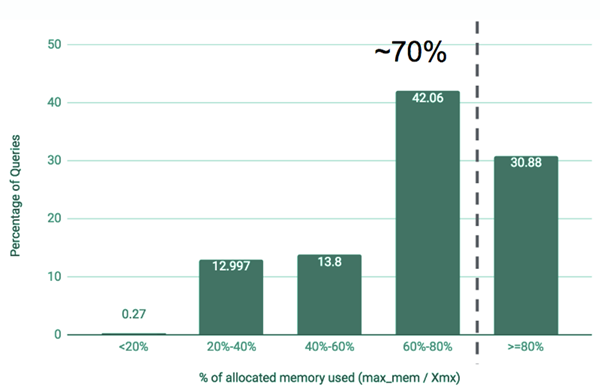
Uber 还将 JVM Profiler 应用到了所有 Hive on Spark 应用, 并发现了一些提高内存使用效率的机会。下面的图3显示了 Uber 发现的一个结果: 大约70% 的应用程序的实际内存利用率不到已分配内存的 80% 。研究结果表明, 大多数应用程序可以分配较少的内存并将内存利用率提高 20% 。
Tips
$ mvn package [INFO] Scanning for projects... [INFO] [INFO] -----------------------< com.uber:jvm-profiler >------------------------ [INFO] Building uber-jvm-profiler 0.0.7 [INFO] --------------------------------[ jar ]--------------------------------- [INFO] Including org.apache.kafka:kafka-clients:jar:0.11.0.2 in the shaded jar. [INFO] Including net.jpountz.lz4:lz4:jar:1.3.0 in the shaded jar. [INFO] Including org.xerial.snappy:snappy-java:jar:1.1.2.6 in the shaded jar. [INFO] Including org.slf4j:slf4j-api:jar:1.7.25 in the shaded jar. [INFO] Including org.apache.commons:commons-lang3:jar:3.5 in the shaded jar. [INFO] Including com.fasterxml.jackson.core:jackson-core:jar:2.8.9 in the shaded jar. [INFO] Including com.fasterxml.jackson.core:jackson-databind:jar:2.8.9 in the shaded jar. [INFO] Including com.fasterxml.jackson.core:jackson-annotations:jar:2.8.0 in the shaded jar. [INFO] Including org.javassist:javassist:jar:3.21.0-GA in the shaded jar. [INFO] Including org.yaml:snakeyaml:jar:1.18 in the shaded jar. [INFO] Including org.apache.httpcomponents:httpclient:jar:4.3.6 in the shaded jar. [INFO] Including org.apache.httpcomponents:httpcore:jar:4.3.3 in the shaded jar. [INFO] Including commons-logging:commons-logging:jar:1.1.3 in the shaded jar. [INFO] Including commons-codec:commons-codec:jar:1.6 in the shaded jar. [INFO] Including redis.clients:jedis:jar:2.9.0 in the shaded jar. [INFO] Including org.apache.commons:commons-pool2:jar:2.4.2 in the shaded jar. [INFO] Replacing original artifact with shaded artifact. [INFO] Replacing /Users/yanrui/project-third/jvm-profiler/target/jvm-profiler-0.0.7.jar with /Users/yanrui/project-third/jvm-profiler/target/jvm-profiler-0.0.7-shaded.jar [INFO] Dependency-reduced POM written at: /Users/yanrui/project-third/jvm-profiler/dependency-reduced-pom.xml [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 03:38 min [INFO] Finished at: 2018-08-07T09:50:26+08:00 [INFO] ------------------------------------------------------------------------ bash-3.2$
## MVN $ wget http://mirrors.hust.edu.cn/apache/maven/maven-3/3.5.4/binaries/apache-maven-3.5.4-bin.tar.gz $ tar -xvf apache-maven-3.5.4-bin.tar.gz $ echo 'export M2_HOME="/usr/local/apache-maven-3.5.4" ' >> ~/.bash_profile $ echo 'export PATH=$M2_HOME/bin:$PATH' >> ~/.bash_profile $ . ~/.bash_profile $ mvn -v Apache Maven 3.5.4
扩展阅读:电子书《Linux Perf Master》
- https://riboseyim.gitbook.io/perf
- https://www.gitbook.com/book/riboseyim/linux-perf-master/details

扩展阅读
- Linux 性能诊断:负载评估
- Linux 性能诊断:快速检查单
- 操作系统原理 | How Linux Works(一):启动
- 操作系统原理 | How Linux Works(二):空间管理
- 操作系统原理 | How Linux Works(三):内存管理
- 操作系统原理 | How Linux Works(三):网络管理
扩展阅读:动态追踪技术
- 动态追踪技术(一):DTrace 导论
- 动态追踪技术(二):strace+gdb 溯源 Nginx 内存溢出异常
- 动态追踪技术(三):Tracing Your Kernel Function!
- 动态追踪技术(四):基于 Linux bcc/BPF 实现 Go 程序动态追踪
- 动态追踪技术(五):Welcome DTrace for Linux
更多精彩内容请“ 阅读原文 ”或扫码关注公众号 读者交流 QQ 群:338272982 [并不承诺解答任何问题] 互联网古典用户欢迎 RSS RiboseYim's Blog: https://riboseyim.github.io

正文到此结束
- 本文标签: HDFS 管理 实例 开源 core executor 分布式 并发 java tab https 集群 IDE App 开发 src ORM id Agent mysql Hadoop git cat redis Apache Hadoop 操作系统 lib Logging Master 字节码 linux ldap ip 产品 数据 空间 参数 dist Job 希望 JVM 服务器 互联网 UI 时间 REST client ACE 文件系统 bus Nginx pom 进程 配置 代码 list build strace AOP javaagent web maven 数据库 sql GitHub key example 删除 Collection bug apache db tar Namenode API XML Uber http IO Presto wget node
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

