MyBatis 源码分析 - 内置数据源
1.简介
本篇文章将向大家介绍 MyBatis 内置数据源的实现逻辑。搞懂这些数据源的实现,可使大家对数据源有更深入的认识。同时在配置这些数据源时,也会更清楚每种属性的意义和用途。因此,如果大家想知其然,也知其所以然。那么接下来就让我们一起去探索 MyBatis 内置数据源的源码吧。
MyBatis 支持三种数据源配置,分别为 UNPOOLED、POOLED 和 JNDI。并提供了两种数据源实现,分别是 UnpooledDataSource 和 PooledDataSource。在三种数据源配置中,UNPOOLED 和 POOLED 是我们最常用的两种配置。至于 JNDI,MyBatis 提供这种数据源的目的是为了让其能够运行在 EJB 或应用服务器等容器中,这一点官方文档中有所说明。由于 JNDI 数据源在日常开发中使用甚少,因此,本篇文章不打算分析 JNDI 数据源相关实现。大家若有兴趣,可自行分析。接下来,本文将重点分析 UNPOOLED 和 POOLED 两种数据源。其他的就不多说了,进入正题吧。
2.内置数据源初始化过程
在详细分析 UnpooledDataSource 和 PooledDataSource 两种数据源实现之前,我们先来了解一下数据源的配置与初始化过程。现在看数据源是如何配置的,如下:
<dataSource type="UNPOOLED|POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql..."/>
<property name="username" value="root"/>
<property name="password" value="1234"/>
</dataSource>
数据源的配置是内嵌在 <environment> 节点中的,MyBatis 在解析 <environment> 节点时,会一并解析数据源的配置。MyBatis 会根据具体的配置信息,为不同的数据源创建相应工厂类,通过工厂类即可创建数据源实例。关于数据源配置的解析以及数据源工厂类的创建过程,我在 MyBatis 配置文件解析过程 一文中分析过,这里就不赘述了。下面我们来看一下数据源工厂类的实现逻辑。
public class UnpooledDataSourceFactory implements DataSourceFactory {
private static final String DRIVER_PROPERTY_PREFIX = "driver.";
private static final int DRIVER_PROPERTY_PREFIX_LENGTH = DRIVER_PROPERTY_PREFIX.length();
protected DataSource dataSource;
public UnpooledDataSourceFactory() {
// 创建 UnpooledDataSource 对象
this.dataSource = new UnpooledDataSource();
}
@Override
public void setProperties(Properties properties) {
Properties driverProperties = new Properties();
// 为 dataSource 创建元信息对象
MetaObject metaDataSource = SystemMetaObject.forObject(dataSource);
// 遍历 properties 键列表,properties 由配置文件解析器传入
for (Object key : properties.keySet()) {
String propertyName = (String) key;
// 检测 propertyName 是否以 "driver." 开头
if (propertyName.startsWith(DRIVER_PROPERTY_PREFIX)) {
String value = properties.getProperty(propertyName);
// 存储配置信息到 driverProperties 中
driverProperties.setProperty(propertyName.substring(DRIVER_PROPERTY_PREFIX_LENGTH), value);
} else if (metaDataSource.hasSetter(propertyName)) {
String value = (String) properties.get(propertyName);
// 按需转换 value 类型
Object convertedValue = convertValue(metaDataSource, propertyName, value);
// 设置转换后的值到 UnpooledDataSourceFactory 指定属性中
metaDataSource.setValue(propertyName, convertedValue);
} else {
throw new DataSourceException("Unknown DataSource property: " + propertyName);
}
}
if (driverProperties.size() > 0) {
// 设置 driverProperties 到 UnpooledDataSourceFactory 的 driverProperties 属性中
metaDataSource.setValue("driverProperties", driverProperties);
}
}
private Object convertValue(MetaObject metaDataSource, String propertyName, String value) {
Object convertedValue = value;
// 获取属性对应的 setter 方法的参数类型
Class<?> targetType = metaDataSource.getSetterType(propertyName);
// 按照 setter 方法的参数类型进行类型转换
if (targetType == Integer.class || targetType == int.class) {
convertedValue = Integer.valueOf(value);
} else if (targetType == Long.class || targetType == long.class) {
convertedValue = Long.valueOf(value);
} else if (targetType == Boolean.class || targetType == boolean.class) {
convertedValue = Boolean.valueOf(value);
}
return convertedValue;
}
@Override
public DataSource getDataSource() {
return dataSource;
}
}
以上是 UnpooledDataSourceFactory 的源码分析,除了 setProperties 方法稍复杂一点,其他的都比较简单,就不多说了。下面看看 PooledDataSourceFactory 的源码。
public class PooledDataSourceFactory extends UnpooledDataSourceFactory {
public PooledDataSourceFactory() {
// 创建 PooledDataSource
this.dataSource = new PooledDataSource();
}
}
以上就是 PooledDataSource 类的所有源码,PooledDataSourceFactory 继承自 UnpooledDataSourceFactory,复用了父类的逻辑,因此它的实现很简单。
关于两种数据源的创建过程就先分析到这,接下来,我们去探究一下两种数据源是怎样实现的。
3.UnpooledDataSource
UnpooledDataSource,从名称上即可知道,该种数据源不具有池化特性。该种数据源每次会返回一个新的数据库连接,而非复用旧的连接。由于 UnpooledDataSource 无需提供连接池功能,因此它的实现非常简单。核心的方法有三个,分别如下:
- initializeDriver - 初始化数据库驱动
- doGetConnection - 获取数据连接
- configureConnection - 配置数据库连接
下面我将按照顺序分节对相关方法进行分析,由于 configureConnection 方法比较简单,因此我把它和 doGetConnection 放在一节中进行分析。下面先来分析 initializeDriver 方法。
3.1 初始化数据库驱动
回顾我们一开始学习使用 JDBC 访问数据库时的情景,在执行 SQL 之前,通常都是先获取数据库连接。一般步骤都是加载数据库驱动,然后通过 DriverManager 获取数据库连接。UnpooledDataSource 也是使用 JDBC 访问数据库的,因此它获取数据库连接的过程也大致如此,只不过会稍有不同。下面我们一起来看一下。
// -☆- UnpooledDataSource
private synchronized void initializeDriver() throws SQLException {
// 检测缓存中是否包含了与 driver 对应的驱动实例
if (!registeredDrivers.containsKey(driver)) {
Class<?> driverType;
try {
// 加载驱动类型
if (driverClassLoader != null) {
// 使用 driverClassLoader 加载驱动
driverType = Class.forName(driver, true, driverClassLoader);
} else {
// 通过其他 ClassLoader 加载驱动
driverType = Resources.classForName(driver);
}
// 通过反射创建驱动实例
Driver driverInstance = (Driver) driverType.newInstance();
/*
* 注册驱动,注意这里是将 Driver 代理类 DriverProxy 对象注册到 DriverManager 中的,
* 而非 Driver 对象本身。DriverProxy 中并没什么特别的逻辑,就不分析。
*/
DriverManager.registerDriver(new DriverProxy(driverInstance));
// 缓存驱动类名和实例
registeredDrivers.put(driver, driverInstance);
} catch (Exception e) {
throw new SQLException("Error setting driver on UnpooledDataSource. Cause: " + e);
}
}
}
如上,initializeDriver 方法主要包含三步操作,分别如下:
- 加载驱动
- 通过反射创建驱动实例
- 注册驱动实例
这三步都是都是常规操作,比较容易理解。上面代码中出现了缓存相关的逻辑,这个是用于避免重复注册驱动。因为 initializeDriver 放阿飞并不是在 UnpooledDataSource 初始化时被调用的,而是在获取数据库连接时被调用的。因此这里需要做个检测,避免每次获取数据库连接时都重新注册驱动。这个是一个比较小的点,大家看代码时注意一下即可。下面看一下获取数据库连接的逻辑。
3.2 获取数据库连接
在使用 JDBC 时,我们都是通过 DriverManager 的接口方法获取数据库连接。本节所要分析的源码也不例外,一起看一下吧。
// -☆- UnpooledDataSource
public Connection getConnection() throws SQLException {
return doGetConnection(username, password);
}
private Connection doGetConnection(String username, String password) throws SQLException {
Properties props = new Properties();
if (driverProperties != null) {
props.putAll(driverProperties);
}
if (username != null) {
// 存储 user 配置
props.setProperty("user", username);
}
if (password != null) {
// 存储 password 配置
props.setProperty("password", password);
}
// 调用重载方法
return doGetConnection(props);
}
private Connection doGetConnection(Properties properties) throws SQLException {
// 初始化驱动
initializeDriver();
// 获取连接
Connection connection = DriverManager.getConnection(url, properties);
// 配置连接,包括自动提交以及事务等级
configureConnection(connection);
return connection;
}
private void configureConnection(Connection conn) throws SQLException {
if (autoCommit != null && autoCommit != conn.getAutoCommit()) {
// 设置自动提交
conn.setAutoCommit(autoCommit);
}
if (defaultTransactionIsolationLevel != null) {
// 设置事务隔离级别
conn.setTransactionIsolation(defaultTransactionIsolationLevel);
}
}
如上,上面方法将一些配置信息放入到 Properties 对象中,然后将数据库连接和 Properties 对象传给 DriverManager 的 getConnection 方法即可获取到数据库连接。
好了,关于 UnpooledDataSource 就先说到这。下面分析一下 PooledDataSource,它的实现要复杂一些。
4.PooledDataSource
PooledDataSource 内部实现了连接池功能,用于复用数据库连接。因此,从效率上来说,PooledDataSource 要高于 UnpooledDataSource。PooledDataSource 需要借助一些辅助类帮助它完成连接池的功能,所以接下来,我们先来认识一下相关的辅助类。
4.1 辅助类介绍
PooledDataSource 需要借助两个辅助类帮其完成功能,这两个辅助类分别是 PoolState 和 PooledConnection。PoolState 用于记录连接池运行时的状态,比如连接获取次数,无效连接数量等。同时 PoolState 内部定义了两个 PooledConnection 集合,用于存储空闲连接和活跃连接。PooledConnection 内部定义了一个 Connection 类型的变量,用于指向真实的数据库连接。以及一个 Connection 的代理类,用于对部分方法调用进行拦截。至于为什么要拦截,随后将进行分析。除此之外,PooledConnection 内部也定义了一些字段,用于记录数据库连接的一些运行时状态。接下来,我们来看一下 PooledConnection 的定义。
class PooledConnection implements InvocationHandler {
private static final String CLOSE = "close";
private static final Class<?>[] IFACES = new Class<?>[]{Connection.class};
private final int hashCode;
private final PooledDataSource dataSource;
// 真实的数据库连接
private final Connection realConnection;
// 数据库连接代理
private final Connection proxyConnection;
// 从连接池中取出连接时的时间戳
private long checkoutTimestamp;
// 数据库连接创建时间
private long createdTimestamp;
// 数据库连接最后使用时间
private long lastUsedTimestamp;
// connectionTypeCode = (url + username + password).hashCode()
private int connectionTypeCode;
// 表示连接是否有效
private boolean valid;
public PooledConnection(Connection connection, PooledDataSource dataSource) {
this.hashCode = connection.hashCode();
this.realConnection = connection;
this.dataSource = dataSource;
this.createdTimestamp = System.currentTimeMillis();
this.lastUsedTimestamp = System.currentTimeMillis();
this.valid = true;
// 创建 Connection 的代理类对象
this.proxyConnection = (Connection) Proxy.newProxyInstance(Connection.class.getClassLoader(), IFACES, this);
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {...}
// 省略部分代码
}
下面再来看看 PoolState 的定义。
public class PoolState {
protected PooledDataSource dataSource;
// 空闲连接列表
protected final List<PooledConnection> idleConnections = new ArrayList<PooledConnection>();
// 活跃连接列表
protected final List<PooledConnection> activeConnections = new ArrayList<PooledConnection>();
// 从连接池中获取连接的次数
protected long requestCount = 0;
// 请求连接总耗时(单位:毫秒)
protected long accumulatedRequestTime = 0;
// 连接执行时间总耗时
protected long accumulatedCheckoutTime = 0;
// 执行时间超时的连接数
protected long claimedOverdueConnectionCount = 0;
// 超时时间累加值
protected long accumulatedCheckoutTimeOfOverdueConnections = 0;
// 等待时间累加值
protected long accumulatedWaitTime = 0;
// 等待次数
protected long hadToWaitCount = 0;
// 无效连接数
protected long badConnectionCount = 0;
}
上面对 PooledConnection 和 PoolState 的定义进行了一些注释,这两个类中有很多字段用来记录运行时状态。但在这些字段并非核心,因此大家知道每个字段的用途就行了。关于这两个辅助类的介绍就先到这
4.2 获取连接
前面已经说过,PooledDataSource 会将用过的连接进行回收,以便可以复用连接。因此从 PooledDataSource 获取连接时,如果空闲链接列表里有连接时,可直接取用。那如果没有空闲连接怎么办呢?此时有两种解决办法,要么创建新连接,要么等待其他连接完成任务。具体怎么做,需视情况而定。下面我们深入到源码中一探究竟。
public Connection getConnection() throws SQLException {
// 返回 Connection 的代理对象
return popConnection(dataSource.getUsername(), dataSource.getPassword()).getProxyConnection();
}
private PooledConnection popConnection(String username, String password) throws SQLException {
boolean countedWait = false;
PooledConnection conn = null;
long t = System.currentTimeMillis();
int localBadConnectionCount = 0;
while (conn == null) {
synchronized (state) {
// 检测空闲连接集合(idleConnections)是否为空
if (!state.idleConnections.isEmpty()) {
// idleConnections 不为空,表示有空闲连接可以使用
conn = state.idleConnections.remove(0);
} else {
/*
* 暂无空闲连接可用,但如果活跃连接数还未超出限制
*(poolMaximumActiveConnections),则可创建新的连接
*/
if (state.activeConnections.size() < poolMaximumActiveConnections) {
// 创建新连接
conn = new PooledConnection(dataSource.getConnection(), this);
} else { // 连接池已满,不能创建新连接
// 取出运行时间最长的连接
PooledConnection oldestActiveConnection = state.activeConnections.get(0);
// 获取运行时长
long longestCheckoutTime = oldestActiveConnection.getCheckoutTime();
// 检测运行时长是否超出限制,即超时
if (longestCheckoutTime > poolMaximumCheckoutTime) {
// 累加超时相关的统计字段
state.claimedOverdueConnectionCount++;
state.accumulatedCheckoutTimeOfOverdueConnections += longestCheckoutTime;
state.accumulatedCheckoutTime += longestCheckoutTime;
// 从活跃连接集合中移除超时连接
state.activeConnections.remove(oldestActiveConnection);
// 若连接未设置自动提交,此处进行回滚操作
if (!oldestActiveConnection.getRealConnection().getAutoCommit()) {
try {
oldestActiveConnection.getRealConnection().rollback();
} catch (SQLException e) {...}
}
/*
* 创建一个新的 PooledConnection,注意,
* 此处复用 oldestActiveConnection 的 realConnection 变量
*/
conn = new PooledConnection(oldestActiveConnection.getRealConnection(), this);
/*
* 复用 oldestActiveConnection 的一些信息,注意 PooledConnection 中的
* createdTimestamp 用于记录 Connection 的创建时间,而非 PooledConnection
* 的创建时间。所以这里要复用原连接的时间信息。
*/
conn.setCreatedTimestamp(oldestActiveConnection.getCreatedTimestamp());
conn.setLastUsedTimestamp(oldestActiveConnection.getLastUsedTimestamp());
// 设置连接为无效状态
oldestActiveConnection.invalidate();
} else { // 运行时间最长的连接并未超时
try {
if (!countedWait) {
state.hadToWaitCount++;
countedWait = true;
}
long wt = System.currentTimeMillis();
// 当前线程进入等待状态
state.wait(poolTimeToWait);
state.accumulatedWaitTime += System.currentTimeMillis() - wt;
} catch (InterruptedException e) {
break;
}
}
}
}
if (conn != null) {
/*
* 检测连接是否有效,isValid 方法除了会检测 valid 是否为 true,
* 还会通过 PooledConnection 的 pingConnection 方法执行 SQL 语句,
* 检测连接是否可用。pingConnection 方法的逻辑不复杂,大家可以自行分析。
* 另外,官方文档在介绍 POOLED 类型数据源时,也介绍了连接有效性检测方面的
* 属性,有三个:poolPingQuery,poolPingEnabled 和
* poolPingConnectionsNotUsedFor。关于这三个属性,大家可以查阅官方文档
*/
if (conn.isValid()) {
if (!conn.getRealConnection().getAutoCommit()) {
// 进行回滚操作
conn.getRealConnection().rollback();
}
conn.setConnectionTypeCode(assembleConnectionTypeCode(dataSource.getUrl(), username, password));
// 设置统计字段
conn.setCheckoutTimestamp(System.currentTimeMillis());
conn.setLastUsedTimestamp(System.currentTimeMillis());
state.activeConnections.add(conn);
state.requestCount++;
state.accumulatedRequestTime += System.currentTimeMillis() - t;
} else {
// 连接无效,此时累加无效连接相关的统计字段
state.badConnectionCount++;
localBadConnectionCount++;
conn = null;
if (localBadConnectionCount > (poolMaximumIdleConnections
+ poolMaximumLocalBadConnectionTolerance)) {
throw new SQLException(...);
}
}
}
}
}
if (conn == null) {
throw new SQLException(...);
}
return conn;
}
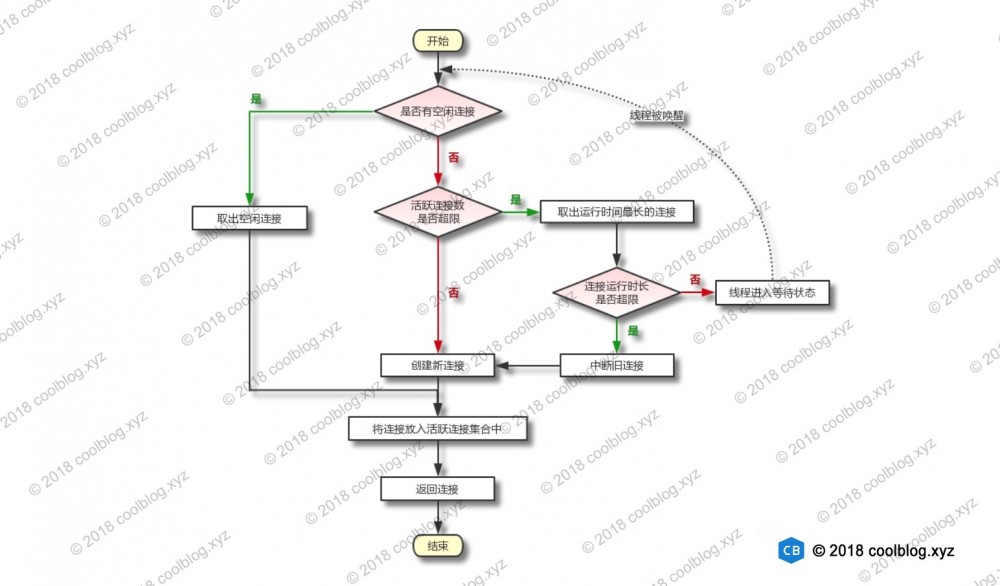
上面代码冗长,过程比较复杂,下面把代码逻辑梳理一下。从连接池中获取连接首先会遇到两种情况:
- 连接池中有空闲连接
- 连接池中无空闲连接
对于第一种情况,处理措施就很简单了,把连接取出返回即可。对于第二种情况,则要进行细分,会有如下的情况。
- 活跃连接数没有超出最大活跃连接数
- 活跃连接数超出最大活跃连接数
对于上面两种情况,第一种情况比较好处理,直接创建新的连接即可。至于第二种情况,需要再次进行细分。
- 活跃连接的运行时间超出限制,即超时了
- 活跃连接未超时
对于第一种情况,我们直接将超时连接强行中断,并进行回滚,然后复用部分字段重新创建 PooledConnection 即可。对于第二种情况,目前没有更好的处理方式了,只能等待了。下面用一段伪代码演示各种情况及相应的处理措施,如下:
if (连接池中有空闲连接) {
1. 将连接从空闲连接集合中移除
} else {
if (活跃连接数未超出限制) {
1. 创建新连接
} else {
1. 从活跃连接集合中取出第一个元素
2. 获取连接运行时长
if (连接超时) {
1. 将连接从活跃集合中移除
2. 复用原连接的成员变量,并创建新的 PooledConnection 对象
} else {
1. 线程进入等待状态
2. 线程被唤醒后,重新执行以上逻辑
}
}
}
1. 将连接添加到活跃连接集合中
2. 返回连接
最后用一个流程图大致描绘 popConnection 的逻辑,如下:
4.3 回收连接
相比于获取连接,回收连接的逻辑要简单的多。回收连接成功与否只取决于空闲连接集合的状态,所需处理情况很少,因此比较简单。下面看一下相关的逻辑。
protected void pushConnection(PooledConnection conn) throws SQLException {
synchronized (state) {
// 从活跃连接池中移除连接
state.activeConnections.remove(conn);
if (conn.isValid()) {
// 空闲连接集合未满
if (state.idleConnections.size() < poolMaximumIdleConnections
&& conn.getConnectionTypeCode() == expectedConnectionTypeCode) {
state.accumulatedCheckoutTime += conn.getCheckoutTime();
// 回滚未提交的事务
if (!conn.getRealConnection().getAutoCommit()) {
conn.getRealConnection().rollback();
}
// 创建新的 PooledConnection
PooledConnection newConn = new PooledConnection(conn.getRealConnection(), this);
state.idleConnections.add(newConn);
// 复用时间信息
newConn.setCreatedTimestamp(conn.getCreatedTimestamp());
newConn.setLastUsedTimestamp(conn.getLastUsedTimestamp());
// 将原连接置为无效状态
conn.invalidate();
// 通知等待的线程
state.notifyAll();
} else { // 空闲连接集合已满
state.accumulatedCheckoutTime += conn.getCheckoutTime();
// 回滚未提交的事务
if (!conn.getRealConnection().getAutoCommit()) {
conn.getRealConnection().rollback();
}
// 关闭数据库连接
conn.getRealConnection().close();
conn.invalidate();
}
} else {
state.badConnectionCount++;
}
}
}
上面代码首先将连接从活跃连接集合中移除,然后再根据空闲集合是否有空闲空间进行后续处理。如果空闲集合未满,此时复用原连接的字段信息创建新的连接,并将其放入空闲集合中即可。若空闲集合已满,此时无需回收连接,直接关闭即可。pushConnection 方法的逻辑并不复杂,就不多说了。
我们知道获取连接的方法 popConnection 是由 getConnection 方法调用的,那回收连接的方法 pushConnection 是由谁调用的呢?答案是 PooledConnection 中的代理逻辑。相关代码如下:
// -☆- PooledConnection
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
String methodName = method.getName();
// 检测 close 方法是否被调用,若被调用则拦截之
if (CLOSE.hashCode() == methodName.hashCode() && CLOSE.equals(methodName)) {
// 将回收连接中,而不是直接将连接关闭
dataSource.pushConnection(this);
return null;
} else {
try {
if (!Object.class.equals(method.getDeclaringClass())) {
checkConnection();
}
// 调用真实连接的目标方法
return method.invoke(realConnection, args);
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
}
在上一节中,getConnection 方法返回的是 Connection 代理对象,不知道大家有没有注意到。代理对象中的方法被调用时,会被上面的代理逻辑所拦截。如果代理对象的 close 方法被调用,MyBatis 并不会直接调用真实连接的 close 方法关闭连接,而是调用 pushConnection 方法回收连接。同时会唤醒处于睡眠中的线程,使其恢复运行。整个过程并不复杂,就不多说了。
4.4 小节
本章分析了 PooledDataSource 的部分源码及一些辅助类的源码,除此之外,PooledDataSource 中还有部分源码没有分析,大家若有兴趣,可自行分析。好了,关于 PooledDataSource 的分析就先到这。
5.总结
本篇文章对 MyBatis 两种内置数据源进行了较为详细的分析,总的来说,这两种数据源的源码都不是很难理解。大家在阅读源码的过程中,首先应搞懂源码的主要逻辑,然后再去分析一些边边角角的逻辑。不要一开始就陷入各种细节中,容易迷失方向。
好了,到此本文就结束了。若文章有错误不妥之处,希望大家指明。最后,感谢大家阅读我的文章。
附录:MyBatis 源码分析系列文章列表
| 更新时间 | 标题 |
|---|---|
| 2018-07-16 | MyBatis 源码分析系列文章导读 |
| 2018-07-20 | MyBatis 源码分析 - 配置文件解析过程 |
| 2018-07-30 | MyBatis 源码分析 - 映射文件解析过程 |
| 2018-08-17 | MyBatis 源码分析 - SQL 的执行过程 |
| 2018-08-19 | MyBatis 源码分析 - 内置数据源 |
正文到此结束
- 本文标签: 希望 Proxy root tar 数据 解析 开发 http IO newProxyInstance mysql UI CTO 参数 统计 Action JDBC https 配置 空间 mybatis src 连接池 db sql 注释 list 详细分析 Property synchronized tab 标题 时间 value Connection autocommit equals 源码 cat 代码 key dataSource 文章 ArrayList ssl 线程 NSA 实例 总结 ACE id 缓存 服务器 数据库 IDE 遍历 final Word
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

