Java并发——阻塞队列集(下)
接着上集继续,SynchronousQueue是一个 不存储元素 的阻塞队列。 每一个put操作必须等待一个take操作,否则不能继续添加元素 ,所以其peek()方法始终返回null,没有数据缓存空间。SynchronousQueue支持公平与非公平访问,默认采用非公平性策略访问队列。
构造方法
public SynchronousQueue() {
this(false);
}
public SynchronousQueue(boolean fair) {
transferer = fair ? new TransferQueue() : new TransferStack();
}
复制代码
相对于ArrayBlockingQueue利用ReentrantLock实现公平与非公平,而SynchronousQueue利用TransferQueue、TransferStack实现公平与非公平,从命名上来看前者队列,后者栈,SynchronousQueue的入队、出队操作都是基于transfer来实现,ctrl+alt+h查看方法调用
TransferQueue
TransferQueue内部定义如下
// 头节点
transient volatile QNode head;
// 尾节点
transient volatile QNode tail;
// 指向一个可能还未出队被取消的节点,因为它在被取消时是最后一个插入节点
transient volatile QNode cleanMe;
// 默认构造函数,创建一个假节点
TransferQueue() {
QNode h = new QNode(null, false); // initialize to dummy node.
head = h;
tail = h;
}
static final class QNode {
// 后继节点
volatile QNode next;
// item数据
volatile Object item;
// 用来控制阻塞或唤醒
volatile Thread waiter; // to control park/unpark
// 是否是生产者
final boolean isData;
QNode(Object item, boolean isData) {
this.item = item;
this.isData = isData;
}
...
}
...
复制代码
公平策略
E transfer(E e, boolean timed, long nanos) {
QNode s = null; // constructed/reused as needed
// 判断是否是生产者,true为生产者,false为消费者
boolean isData = (e != null);
// 死循环
for (;;) {
// 获取尾节点
QNode t = tail;
// 获取头节点
QNode h = head;
// 若尾节点或尾节点为空则跳出本次循序
if (t == null || h == null) // saw uninitialized value
continue; // spin
// 若TransferQueue为空或当前节点与尾节点模式一样
if (h == t || t.isData == isData) { // empty or same-mode
QNode tn = t.next;
// 若t不是尾节点表明已有其他线程操作过,跳出本次循环重新来
if (t != tail) // inconsistent read
continue;
// 若之前获取的尾节点后继不为空表明已有其他线程添加过节点
if (tn != null) { // lagging tail
// CAS将tn置为尾节点
advanceTail(t, tn);
continue;
}
// 若采用了时限模式且超时,直接返回null
if (timed && nanos <= 0) // can't wait
return null;
// 若s为null,构建一个新节点
if (s == null)
s = new QNode(e, isData);
// CAS将新节点加入队列中,若失败重新来
if (!t.casNext(null, s)) // failed to link in
continue;
// CAS将新节点s置为尾节点
advanceTail(t, s); // swing tail and wait
// 自旋获取匹配item
Object x = awaitFulfill(s, e, timed, nanos);
// 若x==s表明线程获取匹配项时,超时或者被中断,清除节点s
if (x == s) { // wait was cancelled
clean(t, s);
return null;
}
// 判断节点s是否已经出队
if (!s.isOffList()) { // not already unlinked
// CAS将节点s置为head,移出队列
advanceHead(t, s); // unlink if head
if (x != null) // and forget fields
s.item = s;
s.waiter = null;
}
return (x != null) ? (E)x : e;
}
// else分支下述
}
}
复制代码
我们假定有线程A、B在put操作,线程C在take操作,当前TransferQueue初始化如下:

线程A添加元素A,head=tail走第一个分支,因为没有采用锁机制,所以可能会有其他线程抢先操作,其采用各种判断以及CAS来判断是否有其他线程操作过,添加完尾结点后,会调用awaitFulfill方法,其作用是自旋寻找匹配节点,若超过自旋次数此线程会阻塞,线程被中断或采用时限模式时获取超时此次操作会被取消。
Object awaitFulfill(QNode s, E e, boolean timed, long nanos) {
// 获取最后期限
final long deadline = timed ? System.nanoTime() + nanos : 0L;
// 获取当前线程
Thread w = Thread.currentThread();
// 获取自旋次数,若新节点s为头节点后继节点才能自旋
int spins = ((head.next == s) ?
(timed ? maxTimedSpins : maxUntimedSpins) : 0);
for (;;) {
// 判断当前线程是否被中断
if (w.isInterrupted())
// 取消当前节点,cas将item置为this
s.tryCancel(e);
// 获取节点s的item
Object x = s.item;
// 若线程中断,节点s的item与x会不相等,直接返回x
if (x != e)
return x;
// 若采用了时限模式
if (timed) {
// 计算剩余时间
nanos = deadline - System.nanoTime();
// 若超时,取消节点
if (nanos <= 0L) {
s.tryCancel(e);
continue;
}
}
// 若还有自旋次数,自旋-1
if (spins > 0)
--spins;
// 若等待线程为null,将节点s的等待线程置为当前线程
else if (s.waiter == null)
s.waiter = w;
// 若没有采用时限模式则调用LockSupport.park()直接阻塞线程
else if (!timed)
LockSupport.park(this);
// 若剩余时间超过自旋时间阈值则指定时间阻塞
else if (nanos > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanos);
}
}
void tryCancel(Object cmp) {
UNSAFE.compareAndSwapObject(this, itemOffset, cmp, this);
}
复制代码
从源码中可以看到 只有头节点后继才能自旋 ,线程A自旋一段时间匹配节点,若自旋次数用光会一直阻塞,所以 每一个线程只有匹配到节点后或者因超时、中断被取消才能继续添加元素
线程A自旋,线程B接着put
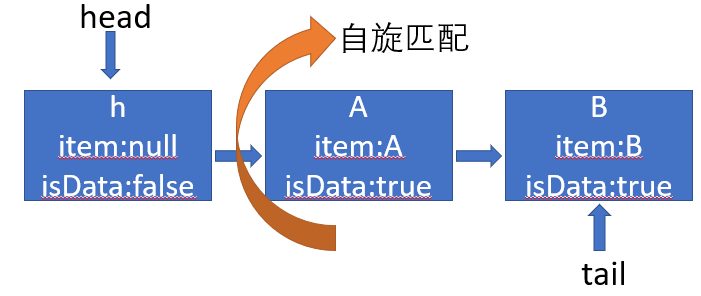
那么什么时候才匹配到呢?在开头我们提到 每一个put操作必须等待一个take操作 ,这时其他线程take(),e为null,isData为false,与尾节点的isData属性不同,走进else分支,先获取头节点的后继节点数据,若没有其他线程抢先操作,且put操作未被取消,m.casItem(x, e)数据替换,将节点m的item属性置为null,若CAS替换成功表明 匹配成功 ,在put自旋时会用item与e比较,take()将item置为null,不相等返回null
else { // complementary-mode
// 获取头节点后继
QNode m = h.next; // node to fulfill
// 若t不是尾节点或者m为null或者h不是头节点,即已有其他线程抢先操作过
if (t != tail || m == null || h != head)
continue; // inconsistent read
Object x = m.item;
if (isData == (x != null) || // 节点已被操作过
x == m || // 节点被取消
!m.casItem(x, e)) { // lost CAS
// CAS将m置为头节点,重来
advanceHead(h, m); // dequeue and retry
continue;
}
// 若走这里,表明匹配成功
advanceHead(h, m); // successfully fulfilled
// 唤醒m的等待线程
LockSupport.unpark(m.waiter);
return (x != null) ? (E)x : e;
}
复制代码
TransferStack
TransferStack内部定义如下
// 未执行的消费者
static final int REQUEST = 0;
// 未执行的生产者
static final int DATA = 1;
// 线程正在匹配节点
static final int FULFILLING = 2;
volatile SNode head;
static final class SNode {
volatile SNode next; // next node in stack
volatile SNode match; // the node matched to this
volatile Thread waiter; // to control park/unpark
Object item; // data; or null for REQUESTs
int mode;
...
}
...
复制代码
TransferStack相对于TransferQueue中的节点,其数据项item与模式mode不需要用volatile修饰,因为它们总是 写在前读在后 。
非公平模式
E transfer(E e, boolean timed, long nanos) {
SNode s = null; // constructed/reused as needed
// REQUEST:消费者;DATA:生产者
int mode = (e == null) ? REQUEST : DATA;
for (;;) {
SNode h = head;
// 若栈为空或者新增元素模式与首元素模式相同
if (h == null || h.mode == mode) { // empty or same-mode
// 超时
if (timed && nanos <= 0) { // can't wait
// 若节点被取消,将取消节点出队,重新来
if (h != null && h.isCancelled())
casHead(h, h.next); // pop cancelled node
else
return null;
//若不采用限时或者未超时,创建节点CAS将其置为头节点,s→h
} else if (casHead(h, s = snode(s, e, h, mode))) {
// 自旋匹配
SNode m = awaitFulfill(s, timed, nanos);
// 若m==s表明节点被取消
if (m == s) { // wait was cancelled
clean(s);
return null;
}
if ((h = head) != null && h.next == s)
casHead(h, s.next); // help s's fulfiller
return (E) ((mode == REQUEST) ? m.item : s.item);
}
// 其余分支下述
}
}
复制代码
依然模拟场景,假定现在线程A、B在put,线程C、D在take。
线程A进行put新增元素A,CAS头插元素A,调用awaitFulfill()自旋匹配,注意只有 头节点、空栈或者协助节点才能自旋 ,每次自旋都会进行条件判断,为了
SNode awaitFulfill(SNode s, boolean timed, long nanos) {
// 最后期限
final long deadline = timed ? System.nanoTime() + nanos : 0L;
Thread w = Thread.currentThread();
// 自旋次数
// 若栈为空、节点为首结点或者该节点模式为FULFILLING才能自旋
int spins = (shouldSpin(s) ?
(timed ? maxTimedSpins : maxUntimedSpins) : 0);
for (;;) {
// 若线程中断,取消该节点
if (w.isInterrupted())
s.tryCancel();
// 匹配节点
SNode m = s.match;
if (m != null)
return m;
if (timed) {
nanos = deadline - System.nanoTime();
// 超时,取消节点
if (nanos <= 0L) {
s.tryCancel();
continue;
}
}
// 每次自旋需先判断是否满足自旋条件,满足次数-1
if (spins > 0)
spins = shouldSpin(s) ? (spins-1) : 0;
else if (s.waiter == null)
s.waiter = w; // establish waiter so can park next iter
// 若没有采用时限模式则调用LockSupport.park()直接阻塞线程
else if (!timed)
LockSupport.park(this);
// 若剩余时间超过自旋时间阈值则指定时间阻塞
else if (nanos > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanos);
}
}
复制代码
线程B接着put元素B,头节点A的模式与put操作的模式一致,CAS头插成功后,也调用awaitFulfill()自旋,由于头节点变为线程B所以只有线程B才能自旋匹配, 这也是不公平的体现
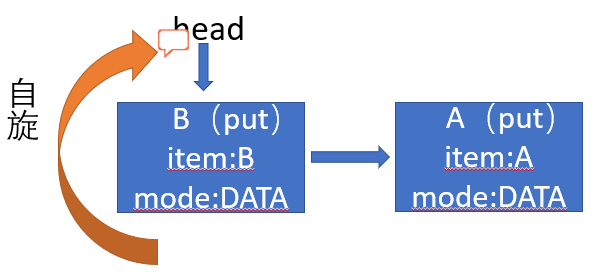
节点的取消与公平模式的差不多都是将属性置为其本身
void tryCancel() {
UNSAFE.compareAndSwapObject(this, matchOffset, null, this);
}
复制代码
这时线程C进行take操作,take的模式(REQUEST)明显与当前头节点B(DATA)不一致且头节点模式也不为FULFILLING,所以transfer走入else if分支。
// 若头节点的模式不为 FULFILLING
} else if (!isFulfilling(h.mode)) { // try to fulfill
// 若头节点被取消,将头节点出队重新来
if (h.isCancelled()) // already cancelled
casHead(h, h.next); // pop and retry
else if (casHead(h, s=snode(s, e, h, FULFILLING|mode))) {
for (;;) { // loop until matched or waiters disappear
SNode m = s.next; // m is s's match
if (m == null) { // all waiters are gone
// 将节点s出队
casHead(s, null); // pop fulfill node
s = null; // use new node next time
break; // restart main loop
}
// 获取节点m的后继节点
SNode mn = m.next;
// 尝试匹配
if (m.tryMatch(s)) {
// 匹配成功,将节点s、m出队
casHead(s, mn); // pop both s and m
return (E) ((mode == REQUEST) ? m.item : s.item);
} else // lost match
// 若匹配失败,将m出队
s.casNext(m, mn); // help unlink
}
}
复制代码
创建一个FULFILLING模式的节点并CAS将其置为头节点,与其后继匹配,匹配方法如下
boolean tryMatch(SNode s) {
if (match == null &&
UNSAFE.compareAndSwapObject(this, matchOffset, null, s)) {
Thread w = waiter;
if (w != null) { // waiters need at most one unpark
waiter = null;
LockSupport.unpark(w);
}
return true;
}
return match == s;
}
复制代码
若节点没有被取消,其match为null,被取消则为其自身。成功匹配后将一对put、take操作的节点出队。我们假定另一种场景,若线程C的take节点入队后,未进行匹配线程D中途take
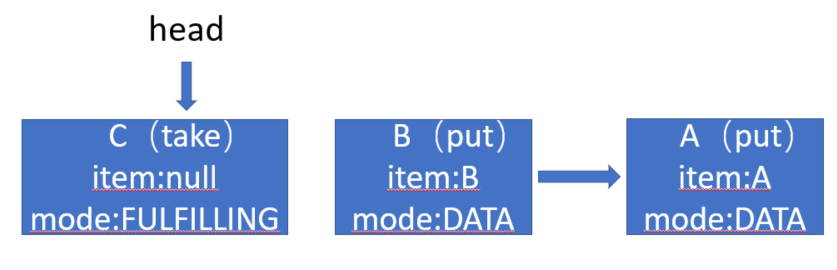
后,再第二次循环继续执行自己操作
// 头节点模式为 FULFILLING
} else { // help a fulfiller
SNode m = h.next; // m is h's match
if (m == null) // waiter is gone
casHead(h, null); // pop fulfilling node
else {
SNode mn = m.next;
if (m.tryMatch(h)) // help match
casHead(h, mn); // pop both h and m
else // lost match
h.casNext(m, mn); // help unlink
}
}
复制代码
LinkedTransferQueue
LinkedTransferQueue是由链表结构组成的无界阻塞FIFO队列
主要字段
// 判断是否多核处理器
private static final boolean MP =
Runtime.getRuntime().availableProcessors() > 1;
// 自旋次数
private static final int FRONT_SPINS = 1 << 7;
// 前驱节点正在操作,当前节点自旋的次数
private static final int CHAINED_SPINS = FRONT_SPINS >>> 1;
static final int SWEEP_THRESHOLD = 32;
// 头节点
transient volatile Node head;
// 尾节点
private transient volatile Node tail;
// 删除节点失败的次数
private transient volatile int sweepVotes;
/**
* xfer()方法中使用
*/
private static final int NOW = 0; // for untimed poll, tryTransfer
private static final int ASYNC = 1; // for offer, put, add
private static final int SYNC = 2; // for transfer, take
private static final int TIMED = 3; // for timed poll, tryTransfer
复制代码
Node内部类
static final class Node {
final boolean isData; // false if this is a request node
volatile Object item; // initially non-null if isData; CASed to match
volatile Node next;
volatile Thread waiter;
Node(Object item, boolean isData) {
UNSAFE.putObject(this, itemOffset, item); // relaxed write
this.isData = isData;
}
...
}
复制代码
是不是感觉与SynchronousQueue中TransferQueue的QNode节点类定义很类似
xfer
LinkedTransferQueue的大多方法都是基于xfer()方法
/**
* @param e 入队数据
* @param haveData true:入队;flase:出队
* @param how NOW, ASYNC, SYNC, or TIMED
* @param nanos 期限仅TIMED限时模式使用
*/
private E xfer(E e, boolean haveData, int how, long nanos) {
// 若是入队操作,但无数据抛异常
if (haveData && (e == null))
throw new NullPointerException();
Node s = null; // the node to append, if needed
retry:
for (;;) { // restart on append race
// 从头节点遍历
for (Node h = head, p = h; p != null;) { // find & match first node
// 获取模式isData
boolean isData = p.isData;
// 获取数据项
Object item = p.item;
// 找到未匹配的节点
if (item != p && (item != null) == isData) { // unmatched
// 若操作模式一样,不匹配
if (isData == haveData) // can't match
break;
// 若匹配,CAS将替换item
if (p.casItem(item, e)) { // match
for (Node q = p; q != h;) {
Node n = q.next; // update by 2 unless singleton
// 更新 head
if (head == h && casHead(h, n == null ? q : n)) {
h.forgetNext();
break;
} // advance and retry
if ((h = head) == null ||
(q = h.next) == null || !q.isMatched())
break; // unless slack < 2
}
// 唤醒线程
LockSupport.unpark(p.waiter);
return LinkedTransferQueue.cast(item);
}
}
// 后继
Node n = p.next;
// 若p的后继是其自身,表明p已经有其他线程操作过,从头节点重写开始
p = (p != n) ? n : (h = head); // Use head if p offlist
}
// 若没有找到匹配节点,
// NOW为untimed poll, tryTransfer,不会入队
if (how != NOW) { // No matches available
if (s == null)
// 创建节点
s = new Node(e, haveData);
// 尾插入队
Node pred = tryAppend(s, haveData);
if (pred == null)
continue retry; // lost race vs opposite mode
// 若不是异步操作
if (how != ASYNC)
// 阻塞等待匹配值
return awaitMatch(s, pred, e, (how == TIMED), nanos);
}
return e; // not waiting
}
}
复制代码
以put()方法为例,假定队列为空此时有线程put(其内部xfer(e, true, ASYNC, 0)),因为不等于now,调用tryAppend()方法尾插入队
private Node tryAppend(Node s, boolean haveData) {
// 从尾节点开始
for (Node t = tail, p = t;;) { // move p to last node and append
Node n, u; // temps for reads of next & tail
// 若队列为空CAS将S置为头节点
if (p == null && (p = head) == null) {
if (casHead(null, s))
return s; // initialize
}
else if (p.cannotPrecede(haveData))
return null; // lost race vs opposite mode
// 若不是最后节点
else if ((n = p.next) != null) // not last; keep traversing
p = p != t && t != (u = tail) ? (t = u) : // stale tail
(p != n) ? n : null; // restart if off list
// CAS设置将s置为p的后继
else if (!p.casNext(null, s))
// 若设置失败重新来
p = p.next; // re-read on CAS failure
else {
if (p != t) { // update if slack now >= 2
while ((tail != t || !casTail(t, s)) &&
(t = tail) != null &&
(s = t.next) != null && // advance and retry
(s = s.next) != null && s != t);
}
return p;
}
}
}
复制代码
从源码中可以得知,当第一次tryAppend()队列为空时只设置了头节点, 第二次tryAppend()才会设置尾结点 ,入队后,若不是ASYNC还会调用awaitMatch()方法阻塞匹配
private E awaitMatch(Node s, Node pred, E e, boolean timed, long nanos) {
// 若限时获取最后期限
final long deadline = timed ? System.nanoTime() + nanos : 0L;
Thread w = Thread.currentThread();
int spins = -1; // initialized after first item and cancel checks
ThreadLocalRandom randomYields = null; // bound if needed
for (;;) {
Object item = s.item;
// 不相等表明已经匹配过,有其他线程已操作过
if (item != e) { // matched
// assert item != s;
// 取消节点
s.forgetContents(); // avoid garbage
return LinkedTransferQueue.cast(item);
}
// 若线程中断或超时则取消节点
if ((w.isInterrupted() || (timed && nanos <= 0)) &&
s.casItem(e, s)) { // cancel
unsplice(pred, s);
return e;
}
// 初始化自旋次数
if (spins < 0) { // establish spins at/near front
if ((spins = spinsFor(pred, s.isData)) > 0)
randomYields = ThreadLocalRandom.current();
}
// 自旋
else if (spins > 0) { // spin
--spins;
if (randomYields.nextInt(CHAINED_SPINS) == 0)
Thread.yield(); // occasionally yield
}
else if (s.waiter == null) {
s.waiter = w; // request unpark then recheck
}
// 若采用限时则限时阻塞
else if (timed) {
nanos = deadline - System.nanoTime();
if (nanos > 0L)
LockSupport.parkNanos(this, nanos);
}
// 直接阻塞
else {
LockSupport.park(this);
}
}
}
复制代码
其整个队列只存在一个操作(入队或出队),若不同操作会替换item唤醒相应另个线程,若相同操作则根据形参how判断判断
NOW:直接返回操作节点不入队
ASYNC:操作节点尾插入队,但不会阻塞等待直接返回,同一个线程随即可以接着操作
SYNC:操作节点尾插入队且会自旋匹配一段时间,自旋次数用完进入阻塞状态,像SynchronousQueue一样 同一个线程操作完必须匹配到或被取消后才能继续操作
TIMED:限时模式,在指定时间内若没匹配到操作会被取消
相对于SynchronousQueue,LinkedTransferQueue可以存储元素且可支持不阻塞形式的操作,而相对于LinkedBlockingQueue维护了入队锁和出队锁,LinkedTransferQueue通过CAS保证线程安全更提高了效率
LinkedBlockingDeque
LinkedBlockingDeque是一个由链表结构组成的 双向 阻塞队列,双向队列就意味着可以从对头、对尾两端插入和移除元素。LinkedBlockingDeque默认构造容量Integer.MAX_VALUE,也可以指定容量
主要属性
// 头节点
transient Node first;
// 尾节点
transient Node last;
// 元素个数
private transient int count;
// 容量
private final int capacity;
final ReentrantLock lock = new ReentrantLock();
private final Condition notEmpty = lock.newCondition();
private final Condition notFull = lock.newCondition();
复制代码
Node内部类
static final class Node {
// 数据项
E item;
// 前驱节点
Node prev;
// 后继节点
Node next;
Node(E x) {
item = x;
}
}
复制代码
入队
public void putFirst(E e) throws InterruptedException {
// 判空
if (e == null) throw new NullPointerException();
// 创建节点
Node node = new Node(e);
final ReentrantLock lock = this.lock;
// 获取锁
lock.lock();
try {
while (!linkFirst(node))
notFull.await();
} finally {
lock.unlock();
}
}
复制代码
判空处理然后获取锁,调用linkFirst()入队
private boolean linkFirst(Node node) {
// assert lock.isHeldByCurrentThread();
// 若当前元素个数超过指定容量,返回false
if (count >= capacity)
return false;
// 获取首节点
Node f = first;
// 新节点后继指向首节点
node.next = f;
// 新节点置为首节点
first = node;
// 若队列为空则新节点置为尾节点
if (last == null)
last = node;
// 若不为空,新节点置为首节点的前驱节点
else
f.prev = node;
// 元素个数+1
++count;
// 唤醒出队(消费者)等待队列中线程
notEmpty.signal();
return true;
}
复制代码
public void putLast(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
Node node = new Node(e);
final ReentrantLock lock = this.lock;
lock.lock();
try {
while (!linkLast(node))
notFull.await();
} finally {
lock.unlock();
}
}
复制代码
判空处理然后获取锁,调用linkLast()入队
private boolean linkLast(Node node) {
// assert lock.isHeldByCurrentThread();
// 若当前元素个数超过指定容量,返回false
if (count >= capacity)
return false;
// 获取尾节点
Node l = last;
// 将新节点的前驱节点置为原尾节点
node.prev = l;
// 新节点置为尾节点
last = node;
// 若队列为空,首结点置为头节点
if (first == null)
first = node;
// 否则将新节点置为原未节点的后继节点
else
l.next = node;
// 元素个数+1
++count;
// 唤醒出队(消费者)等待队列中线程
notEmpty.signal();
return true;
}
复制代码
出队
public E takeFirst() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lock();
try {
E x;
while ( (x = unlinkFirst()) == null)
notEmpty.await();
return x;
} finally {
lock.unlock();
}
}
复制代码
unlinkFirst()方法
private E unlinkFirst() {
// assert lock.isHeldByCurrentThread();
// 获取头节点
Node f = first;
// 若first为null即队列为空,返回null
if (f == null)
return null;
// 获取头节点的后继节点
Node n = f.next;
E item = f.item;
// 删除头节点
f.item = null;
f.next = f; // help GC
// 将原头节点的后继节点置为头节点
first = n;
// 若原队列仅一个节点,则尾节点置空
if (n == null)
last = null;
// 否则原头节点的后继节点的前驱置为null
else
n.prev = null;
// 元素个数-1
--count;
// 唤醒入队(生产者)等待队列中线程
notFull.signal();
return item;
}
复制代码
public E takeLast() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lock();
try {
E x;
while ( (x = unlinkLast()) == null)
notEmpty.await();
return x;
} finally {
lock.unlock();
}
}
复制代码
unlinkLast
private E unlinkLast() {
// assert lock.isHeldByCurrentThread();
// 获取尾节点
Node l = last;
// 尾节点为null即队列为空,返回null
if (l == null)
return null;
// 获取原尾节点的前驱节点
Node p = l.prev;
E item = l.item;
// 删除尾节点
l.item = null;
l.prev = l; // help GC
// 将原尾节点的前驱节点置为尾节点
last = p;
// 若原队列仅一个节点,则头节点置空
if (p == null)
first = null;
// 否则原尾节点的前驱节点的后继置为null
else
p.next = null;
// 元素个数-1
--count;
notFull.signal();
return item;
}
复制代码
逻辑就不多说了,看过LinkedList源码的应该不会陌生,除了多了唤醒阻塞获取锁操作,基本逻辑类似
总结
数组实现的有界FIFO阻塞队列,初始化时 必须 指定容量。内部通过ReentrantLock(一把锁)保证出入队线程安全、支持公平与非公平,因为公平性通常会降低吞吐量所以默认非公平策略;putIndex、takeIndex属性维护入队、出队位置;notEmpty、notFull两个Condition队列,利用Condition的等待唤醒机制实现可阻塞式的入队和出队
链表实现的有界FIFO阻塞队列,默认容量Integer.MAX_VALUE。内部通过takeLock、putLock两把ReentrantLock锁保证出入队线程安全, 两个锁降低线程由于线程无法获取单个lock而进入WAITING状态的可能性提高了线程并发执行的效率 ,也因此其count属性用原子操作类(可能两个线程一个出队一个入队同时操作count需要原子操作)。notEmpty、notFull两个Condition队列,利用Condition的等待唤醒机制实现可阻塞式的入队和出队
支持优先级的无界阻塞队列(就像无限流量一样内部还是定义了最大容量Integer.MAX_VALUE - 8),默认情况元素采取自然顺序升序排序,但不能保证同优先级元素的顺序。因为无界其插入始终成功,所以内部只维护了一个notEmpty(出队)Condition队列。通过ReentrantLock以及CAS一同维护线程安全且尽可能地缩小了锁的范围以此减少锁竞争提高性能,底层结构采用基于数组的堆实现
支持优先级、延时获取元素的无界阻塞队列,队列使用PriorityQueue来实现。队列中的元素必须实现Delayed接口,只有在延迟期满时才能从队列中提取元素。虽然PriorityQueue线程不安全,但在调用同时需要获取ReentrantLock锁,也是利用Condition的等待唤醒机制实现可阻塞式的入队和出队。属性leader不为null时,表明有线程占用其作用在于减少不必要的竞争
不存储元素的阻塞队列没有数据缓存空间,每个线程的put操作必须等待一个take操作,否则不能继续添加元素。两个内部类TransferQueue队列、TransferStack栈实现公平与非公平策略,其大多方法基于transfer()方法实现
链表结构组成的无界阻塞FIFO队列,核心方法xfer()。是SynchronousQueue和LinkedBlockingQueues的合体,相对于SynchronousQueue,LinkedTransferQueue可以存储元素且可支持不阻塞形式的操作,而相对于LinkedBlockingQueue维护了入队锁和出队锁,LinkedTransferQueue通过CAS保证线程安全更提高了效率
LinkedBlockingDeque是一个由链表结构组成的双向阻塞队列,双向队列就意味着可以从对头、对尾两端插入和移除元素。默认构造容量Integer.MAX_VALUE,出队入队和LinkedList有点类似,LinkedBlockingDeque多了ReentrantLock锁机制实现线程安全以及notEmpty、notFull两个Condition队列,利用Condition的等待唤醒机制实现可阻塞式的入队和出队
正文到此结束
热门推荐









相关文章

近期评论
-
https://www.newcmy.com/register?aff=HBVX
建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。 -
出现OpenClaw "device signature expired"。the Gateway rejects if Math.abs(Date.now() - signedAt) > 10 * 60 * 1000 (10 minutes)
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

