Android Native Crash 收集
本篇核心讲解了自己实现一个 Android Native Crash 收集的方案步骤,重点问题解决办法。
对本文有任何问题,可加我的个人微信:kymjs123
在 Android 平台上,Native Crash 一直是比较麻烦的问题,因为捕获麻烦,获取到了内容又不全,内容全了信息又不对,信息对了又不好处理。比 Java Crash 不知道麻烦多少倍。
今天跟大家讲一下,我最近掉了几百根头发写出来的一个 Native Crash 收集的功能(脱发已经越来越严重了)。
一个 Native Crash 的 log 信息如下图:
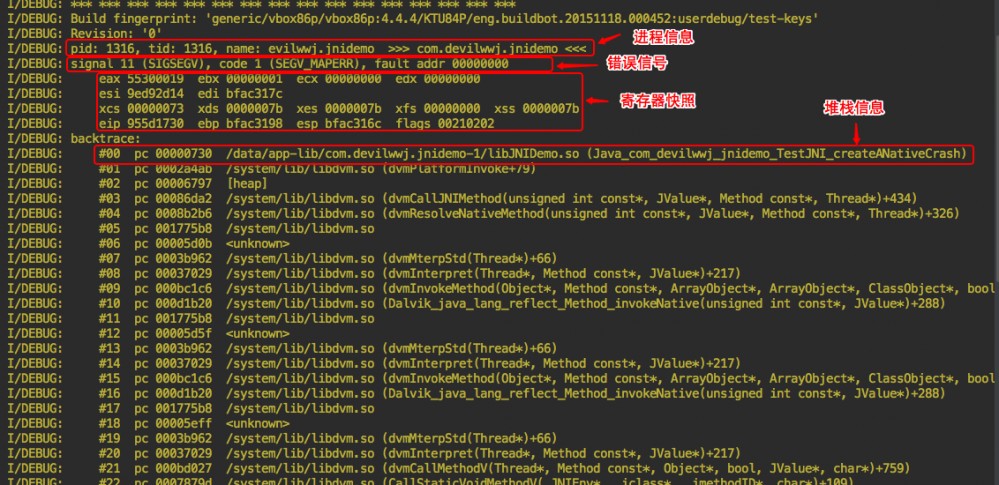
这张图是我在网上找的(由于没有写 demo,项目中的截图不方便直接拿出来,就偷了个懒)。
在上图里,堆栈信息中 pc 后面跟的内存地址,就是当前函数的栈地址,我们可以通过命令行 arm-linux-androideabi-addr2line -e 内存地址 得出出错的代码行数了。
要实现 Native Crash 的收集,主要有四个重点:知道 Crash 的发生;捕获到 Crash 的位置;获取 Crash 发生位置的函数调用栈;数据能回传到服务器。
知道 Crash 的发生
与 Java 平台不同,C/C++ 没有一个通用的异常处理接口,在 C 层,CPU 通过异常中断的方式,触发异常处理流程。不同的处理器,有不同的异常中断类型和中断处理方式,linux 把这些中断处理,统一为信号量,每一种异常都有一个对应的信号,可以注册回调函数进行处理需要关注的信号量。
所有的信号量都定义在<signal.h>文件中,这里我将几乎全部的信号量以及所代表的含义都标注出来了:
#define SIGHUP 1 // 终端连接结束时发出(不管正常或非正常) #define SIGINT 2 // 程序终止(例如Ctrl-C) #define SIGQUIT 3 // 程序退出(Ctrl-/) #define SIGILL 4 // 执行了非法指令,或者试图执行数据段,堆栈溢出 #define SIGTRAP 5 // 断点时产生,由debugger使用 #define SIGABRT 6 // 调用abort函数生成的信号,表示程序异常 #define SIGIOT 6 // 同上,更全,IO异常也会发出 #define SIGBUS 7 // 非法地址,包括内存地址对齐出错,比如访问一个4字节的整数, 但其地址不是4的倍数 #define SIGFPE 8 // 计算错误,比如除0、溢出 #define SIGKILL 9 // 强制结束程序,具有最高优先级,本信号不能被阻塞、处理和忽略 #define SIGUSR1 10 // 未使用,保留 #define SIGSEGV 11 // 非法内存操作,与SIGBUS不同,他是对合法地址的非法访问,比如访问没有读权限的内存,向没有写权限的地址写数据 #define SIGUSR2 12 // 未使用,保留 #define SIGPIPE 13 // 管道破裂,通常在进程间通信产生 #define SIGALRM 14 // 定时信号, #define SIGTERM 15 // 结束程序,类似温和的SIGKILL,可被阻塞和处理。通常程序如果终止不了,才会尝试SIGKILL #define SIGSTKFLT 16 // 协处理器堆栈错误 #define SIGCHLD 17 // 子进程结束时, 父进程会收到这个信号。 #define SIGCONT 18 // 让一个停止的进程继续执行 #define SIGSTOP 19 // 停止进程,本信号不能被阻塞,处理或忽略 #define SIGTSTP 20 // 停止进程,但该信号可以被处理和忽略 #define SIGTTIN 21 // 当后台作业要从用户终端读数据时, 该作业中的所有进程会收到SIGTTIN信号 #define SIGTTOU 22 // 类似于SIGTTIN, 但在写终端时收到 #define SIGURG 23 // 有紧急数据或out-of-band数据到达socket时产生 #define SIGXCPU 24 // 超过CPU时间资源限制时发出 #define SIGXFSZ 25 // 当进程企图扩大文件以至于超过文件大小资源限制 #define SIGVTALRM 26 // 虚拟时钟信号. 类似于SIGALRM, 但是计算的是该进程占用的CPU时间. #define SIGPROF 27 // 类似于SIGALRM/SIGVTALRM, 但包括该进程用的CPU时间以及系统调用的时间 #define SIGWINCH 28 // 窗口大小改变时发出 #define SIGIO 29 // 文件描述符准备就绪, 可以开始进行输入/输出操作 #define SIGPOLL SIGIO // 同上,别称 #define SIGPWR 30 // 电源异常 #define SIGSYS 31 // 非法的系统调用
通常我们在做 crash 收集的时候,主要关注这几个信号量:
const int signal_array[] = {SIGILL, SIGABRT, SIGBUS, SIGFPE, SIGSEGV, SIGSTKFLT, SIGSYS};
对应的含义可以参考上文,
extern int sigaction(int, const struct sigaction*, struct sigaction*);
第一个参数 int 类型,表示需要关注的信号量
第二个参数 sigaction 结构体指针,用于声明当某个特定信号发生的时候,应该如何处理。
第三个参数也是 sigaction 结构体指针,他表示的是默认处理方式,当我们自定义了信号量处理的时候,用他存储之前默认的处理方式。
这也是指针与引用的区别,指针操作操作的都是变量本身,所以给新指针赋值了以后,需要另一个指针来记录封装了默认处理方式的变量在内存中的位置。
所以,要订阅异常发生的信号,最简单的做法就是直接用一个循环遍历所有要订阅的信号,对每个信号调用 sigaction()
void init() {
struct sigaction handler;
struct sigaction old_signal_handlers[SIGNALS_LEN];
for (int i = 0; i < SIGNALS_LEN; ++i) {
sigaction(signal_array[i], &handler, & old_signal_handlers[i]);
}
}
捕获到 Crash 的位置
sigaction 结构体有一个 sa_sigaction 变量,他是个函数指针,原型为: void (*)(int siginfo_t *, void *)
因此,我们可以声明一个函数,直接将函数的地址赋值给 sa_sigaction
void signal_handle(int code, siginfo_t *si, void *context) {
}
void init() {
struct sigaction old_signal_handlers[SIGNALS_LEN];
struct sigaction handler;
handler.sa_sigaction = signal_handle;
handler.sa_flags = SA_SIGINFO;
for (int i = 0; i < SIGNALS_LEN; ++i) {
sigaction(signal_array[i], &handler, & old_signal_handlers[i]);
}
}
这样当发生 Crash 的时候就会回调我们传入的 signal_handle() 函数了。在 signal_handle() 函数中,我们得要想办法拿到当前执行的代码信息。
设置紧急栈空间
如果当前函数发生了无限递归造成堆栈溢出,在统计的时候需要考虑到这种情况而新开堆栈否则本来就满了的堆栈又在当前堆栈处理溢出信号,处理肯定是会失败的。所以我们需要设置一个用于紧急处理的新栈,可以使用 sigaltstack() 在任意线程注册一个可选的栈,保留一下在紧急情况下使用的空间。(系统会在危险情况下把栈指针指向这个地方,使得可以在一个新的栈上运行信号处理函数)
void signal_handle(int sig) {
write(2, "stack overflow/n", 15);
_exit(1);
}
unsigned infinite_recursion(unsigned x) {
return infinite_recursion(x)+1;
}
int main() {
static char stack[SIGSTKSZ];
stack_t ss = {
.ss_size = SIGSTKSZ,
.ss_sp = stack,
};
struct sigaction sa = {
.sa_handler = signal_handle,
.sa_flags = SA_ONSTACK
};
sigaltstack(&ss, 0);
sigfillset(&sa.sa_mask);
sigaction(SIGSEGV, &sa, 0);
infinite_recursion(0);
}
捕获出问题的代码
signal_handle() 函数中的第三个参数 context 是 uc_mcontext 的结构体指针,它封装了 cpu 相关的上下文,包括当前线程的寄存器信息和奔溃时的 pc 值,能够知道崩溃时的pc,就能知道崩溃时执行的是那条指令,同样的,在本文顶部的那张图中寄存器快照就可以用如下代码获得。
char *head_cpu = nullptr;
asprintf(&head_cpu, "r0 %08lx r1 %08lx r2 %08lx r3 %08lx/n"
"r4 %08lx r5 %08lx r6 %08lx r7 %08lx/n"
"r8 %08lx r9 %08lx sl %08lx fp %08lx/n"
"ip %08lx sp %08lx lr %08lx pc %08lx cpsr %08lx/n",
t->uc_mcontext.arm_r0, t->uc_mcontext.arm_r1, t->uc_mcontext.arm_r2,
t->uc_mcontext.arm_r3, t->uc_mcontext.arm_r4, t->uc_mcontext.arm_r5,
t->uc_mcontext.arm_r6, t->uc_mcontext.arm_r7, t->uc_mcontext.arm_r8,
t->uc_mcontext.arm_r9, t->uc_mcontext.arm_r10, t->uc_mcontext.arm_fp,
t->uc_mcontext.arm_ip, t->uc_mcontext.arm_sp, t->uc_mcontext.arm_lr,
t->uc_mcontext.arm_pc, t->uc_mcontext.arm_cpsr);
不过 uc_mcontext 结构体的定义是平台相关的,比如我们熟知的 arm 、 x86 这种都不是同一个结构体定义,上面的代码只列出了 arm 架构的寄存器信息,要兼容其他架构的 cpu 在处理的时候,就得要寄出宏编译大法,不同的架构使用不同的定义。
uintptr_t pc_from_ucontext(const ucontext_t *uc) {
#if (defined(__arm__))
return uc->uc_mcontext.arm_pc;
#elif defined(__aarch64__)
return uc->uc_mcontext.pc;
#elif (defined(__x86_64__))
return uc->uc_mcontext.gregs[REG_RIP];
#elif (defined(__i386))
return uc->uc_mcontext.gregs[REG_EIP];
#elif (defined (__ppc__)) || (defined (__powerpc__))
return uc->uc_mcontext.regs->nip;
#elif (defined(__hppa__))
return uc->uc_mcontext.sc_iaoq[0] & ~0x3UL;
#elif (defined(__sparc__) && defined (__arch64__))
return uc->uc_mcontext.mc_gregs[MC_PC];
#elif (defined(__sparc__) && !defined (__arch64__))
return uc->uc_mcontext.gregs[REG_PC];
#else
#error "Architecture is unknown, please report me!"
#endif
}
pc值转内存地址
pc值是程序加载到内存中的绝对地址,绝对地址不能直接使用,因为每次程序运行创建的内存肯定都不是固定区域的内存,所以绝对地址肯定每次运行都不一致。我们需要拿到崩溃代码相对于当前库的相对偏移地址,这样才能使用 addr2line 分析出是哪一行代码。通过 dladdr() 可以获得共享库加载到内存的起始地址,和 pc 值相减就可以获得相对偏移地址,并且可以获得共享库的名字。
Dl_info info;
if (dladdr(addr, &info) && info.dli_fname) {
void * const nearest = info.dli_saddr;
uintptr_t addr_relative = addr - info.dli_fbase;
}
获取 Crash 发生时的函数调用栈
获取函数调用栈是最麻烦的,至今没有一个好用的,全都要做一些大改动。常见的做法有四种:
- 第一种:直接使用系统的
<unwind.h>库,可以获取到出错文件与函数名。只不过需要自己解析函数符号,同时经常会捕获到系统错误,需要手动过滤。 - 第二种:在
4.1.1以上,5.0以下,使用系统自带的libcorkscrew.so,5.0开始,系统中没有了libcorkscrew.so,可以自己编译系统源码中的libunwind。libunwind是一个开源库,事实上高版本的安卓源码中就使用了他的优化版替换libcorkscrew。 - 第三种:使用开源库
coffeecatch,但是这种方案也不能百分之百兼容所有机型。 - 第四种:使用 Google 的
breakpad,这是所有 C/C++堆栈获取的权威方案,基本上业界都是基于这个库来做的。只不过这个库是全平台的 android、iOS、Windows、Linux、MacOS 全都有,所以非常大,在使用的时候得把无关的平台剥离掉减小体积。
下面以第一种为例讲一下实现:
核心方法是使用 <unwind.h> 库提供的一个方法 _Unwind_Backtrace() 这个函数可以传入一个函数指针作为回调,指针指向的函数有一个重要的参数是 _Unwind_Context 类型的结构体指针。
可以使用 _Unwind_GetIP() 函数将当前函数调用栈中每个函数的绝对内存地址(也就是上文中提到的 pc 值),写入到 _Unwind_Context 结构体中,最终返回的是当前调用栈的全部函数地址了, _Unwind_Word 实际上就是一个 unsigned int 。
而 capture_backtrace() 返回的就是当前我们获取到调用栈中内容的数量。
/**
* callback used when using <unwind.h> to get the trace for the current context
*/
_Unwind_Reason_Code unwind_callback(struct _Unwind_Context *context, void *arg) {
backtrace_state_t *state = (backtrace_state_t *) arg;
_Unwind_Word pc = _Unwind_GetIP(context);
if (pc) {
if (state->current == state->end) {
return _URC_END_OF_STACK;
} else {
*state->current++ = (void *) pc;
}
}
return _URC_NO_REASON;
}
/**
* uses built in <unwind.h> to get the trace for the current context
*/
size_t capture_backtrace(void **buffer, size_t max) {
backtrace_state_t state = {buffer, buffer + max};
_Unwind_Backtrace(unwind_callback, &state);
return state.current - buffer;
}
当所有的函数的绝对内存地址(pc 值)都获取到了,就可以用上文讲的办法将 pc 值转换为相对偏移量,获取到真正的函数信息和相对内存地址了。
void *buffer[max_line];
int frames_size = capture_backtrace(buffer, max_line);
for (int i = 0; i < frames_size; i++) {
Dl_info info;
const void *addr = buffer[i];
if (dladdr(addr, &info) && info.dli_fname) {
void * const nearest = info.dli_saddr;
uintptr_t addr_relative = addr - info.dli_fbase;
}
Dl_info 是一个结构体,内部封装了函数所在文件、函数名、当前库的基地址等信息
typedef struct {
const char *dli_fname; /* Pathname of shared object that
contains address */
void *dli_fbase; /* Address at which shared object
is loaded */
const char *dli_sname; /* Name of nearest symbol with address
lower than addr */
void *dli_saddr; /* Exact address of symbol named
in dli_sname */
} Dl_info;
有了这个对象,我们就能获取到全部想要的信息了。虽然获取到全部想要的信息,但 <unwind.h> 有个麻烦的就是不想要的信息也给你了,所以需要手动过滤掉各种系统错误,最终得到的数据,就可以上报到自己的服务器了。
数据回传到服务器
数据回传有两种方式,一种是直接将信息写入文件,下次启动的时候直接由 Java 上报;另一种就是回调 Java 代码,让 Java 去处理。用 Java 处理的好处是 Java 层可以继续在当前上下文上加上 Java 层的各种状态信息,写入到同一个文件中,使得开发在解决 bug 的时候能更方便。
这里就简单将数据写入文件了。
void save(const char *name, char *content) {
FILE *file = fopen(name, "w+");
fputs(content, file);
fflush(file);
fclose(file);
//可以在写入文件以后,再通知 Java 层,直接将文件名传给 Java 层更简单。
report();
}
如果你按照本文讲的,应该是可以创建一个可以工作的 Native Crash 收集库了,但是还有很多细节上的问题,比如数据的丢失问题,写文件的时候使用 w+ 可能造成上次存储的文件丢失;如果当前函数发生了无限递归造成堆栈溢出,在统计的时候需要考虑到这种情况而新开堆栈否则本来就满了的堆栈又在当前堆栈处理溢出信号,处理肯定是会失败的;再比方说多进程多线程在 C 上的各种问题,真的是很复杂。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

