性能对比:ReentrantLock vs Synchronized
最近遇到高并发引起的性能问题,最终定位到的问题是 LinkedBlockingQueue 的性能不行,最终通过创建了多个 Queue 来减少每个 Queue 的竞争压力。人生中第一次遇到 JDK 自带数据结构无法满足需求的情形,决心好好研究一下为什么。
压测在一个 40 个核的机器上,tomcat 默认 200 个线程,发送方以 500 并发约 1w QPS 发送请求,要求999 分位的响应在 50ms 左右。代码中有一个异步写入数据库的任务,实际测试时有超过 60% 的延时都在写入队列中(实际上是往 ThreadPool 提交任务)。于是开始调研 LinkedBlockingQueue 的实现。
LinkedBlockingQueue 相当于是普通 LinkedList 加上 ReentrantLock 在操作时加锁。而 ReentrantLock (以及其它 Java 中的锁)内部都是靠 CAS 来实现原子性。而 CAS 在高并发时因为线程会不停重试,所以理论上性能会比原生的锁更差。
实际上想对比 CAS 和原生锁是很困难的。Java 中没有原生的锁,而 synchronized 有 JDK 的各种优化,在一些低并发的情况下也用到了 CAS。对比过 synchronized 和 Unsafe.compareAndSwapInt 发现 CAS 被吊打。所以最后还是退而求其次对比 ReentrantLock 和 Synchronized 的性能。
一个线程竞争 ReentrantLock 失败时,会被放到等待对列中,不会参与后续的竞争,因此 ReentrantLock 不能代表 CAS 在高并发下的表现。不过一般我们也不会直接使用 CAS,所以测试结果也凑合着看了。
测试使用的是 JMH 框架,号称能测到毫秒级。运行的机器是 40 核的,因此至少能保证同时竞争的线程是 40 个(如果 CPU 核数不足,尽管线程数多,真正同时并发的量可能并不多)。JDK 1.8 下测试。
首先测试用 synchronized 与 ReentrantLock 同步自增操作,测试代码如下:
@Benchmark
@Group("lock")
@GroupThreads(4)
public void lockedOp() {
try {
lock.lock();
lockCounter ++;
} finally {
lock.unlock();
}
}
@Benchmark
@Group("synchronized")
@GroupThreads(4)
public void synchronizedOp() {
synchronized (this) {
rawCounter ++;
}
}
结果如下:

自增操作 CPU 时间太短,适当增加每个操作的时间,改为往 linkedList 插入一个数据。代码如下:
@Benchmark
@Group("lock")
@GroupThreads(2)
public void lockedOp() {
try {
lock.lock();
lockQueue.add("event");
if (lockQueue.size() >= CLEAR_COUNT) {
lockQueue.clear();
}
} finally {
lock.unlock();
}
}
@Benchmark
@Group("synchronized")
@GroupThreads(2)
public void synchronizedOp() {
synchronized (this) {
rawQueue.add("event");
if (rawQueue.size() >= CLEAR_COUNT) {
rawQueue.clear();
}
}
}
结果如下:
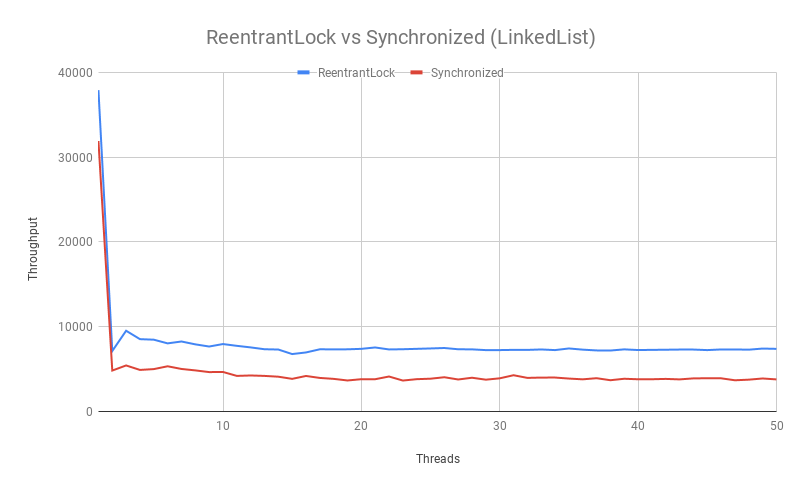
- 可以看到 ReentrantLock 的性能还是要高于 Synchronized 的。
- 在 2 个线程时吞吐量达到最低,而 3 个线程反而提高了,推测是因为两个线程竞争时一定会发生线程调度,而多个线程(不公平)竞争时有一些线程是可以直接从当前线程手中接过锁的。
- 随着线程数的增加,吞吐量只有少量的下降。首先推测因为同步代码最多只有一个线程在执行,所以线程数虽然增多,吞吐量是不会增加多少的。其次是大部分线程变成等待后就不太会被唤醒,因此不太会参与后续的竞争。
- (linkedlist 测试中)持有锁的时间增加后,ReentrantLock 与 Synchronized 的吞吐量差距减小了,应该是能佐证 CAS 线程重试的开销在增长的。
这个测试让我对 ReentrantLock 有了更多的信心,不过一般开发时还是建议用 synchronized, 毕竟大佬们还在不断优化中(看到有文章说 JDK 9 中的 Lock 和 synchronized 已经基本持平了)。
如果有人知道怎么更好地对比 CAS 和锁的性能,欢迎留言~
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

