DockOne微信分享(一八六):有货在Kubernetes容器环境的CD实践
【编者的话】业内各大云服务商以及公司逐渐选择Kubernetes与Docker作为微服务支撑的首选平台。为了更好满足DevOps,我们采用了开源框架Spinnaker作为持续交付平台,完成服务的快速部署,回滚,A/B测试,以及金丝雀等等的部署方式,同时我们在生产做了多区的容灾,更好的保障线上服务。
Spinnaker介绍
Spinnaker 是Netflix的开源项目,是一个持续交付平台,它定位于将产品快速且持续的部署到多种云平台上。Spinnaker有两个核心的功能集群管理和部署管理。Spinnaker通过将发布和各个云平台解耦,来将部署流程流水线化,从而降低平台迁移或多云平台部署应用的复杂度,它本身内部支持Google、AWS EC2、Microsoft Azure、Kubernetes和OpenStack等云平台,并且它可以无缝集成其他持续集成(CI)流程,如Git、Jenkins、Travis CI、Docker registry、cron调度器等。
应用管理
Spinnaker主要用于展示与管理你的云端资源。
先要了解一些关键的概念:Applications,Cluster,and Server Groups,
通过Load balancers and firewalls将服务展示给用户。官方给的结构如下:
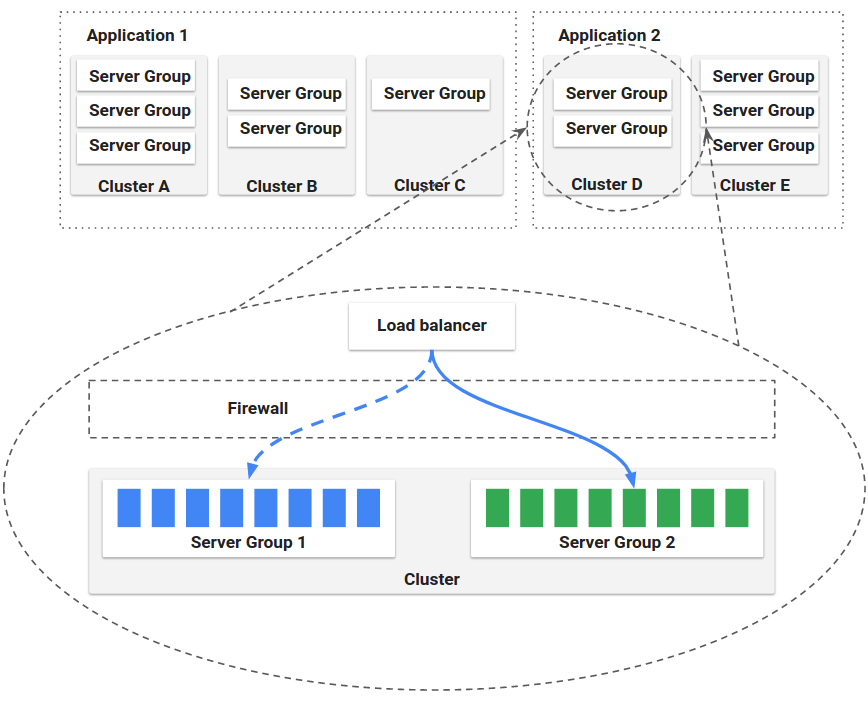
Application
定义了集群中一组的Cluster的集合,也包括了Firewalls与Load Balancers,存储了服务所有的部署相关的的信息。
Server Group
定义了一些基础的源比如(VM image、Docker image),以及一些基础的配置信息,一旦部署后,在容器中对应Kubernetes Pod的集合。
Cluster
Server Groups的有关联的集合。(Cluster中可以按照dev,prod的去创建不同的服务组),也可以理解为对于一个应用存在多个分支的情况。
Load Balancer
它在实例之间做负载均衡流量。您还可以为负载均衡器启用健康检查,灵活地定义健康标准并指定健康检查端点,有点类似于Kubernetes中Ingress。
Firewall
防火墙定义了网络流量访问,定义了一些访问的规则,如安全组等等。
页面预览
页面展示如下,还是比较精简的,可以在它的操作页面上看到项目以及应用的详细信息,还可以进行集群的伸缩、回滚、修改以及删除的操作。
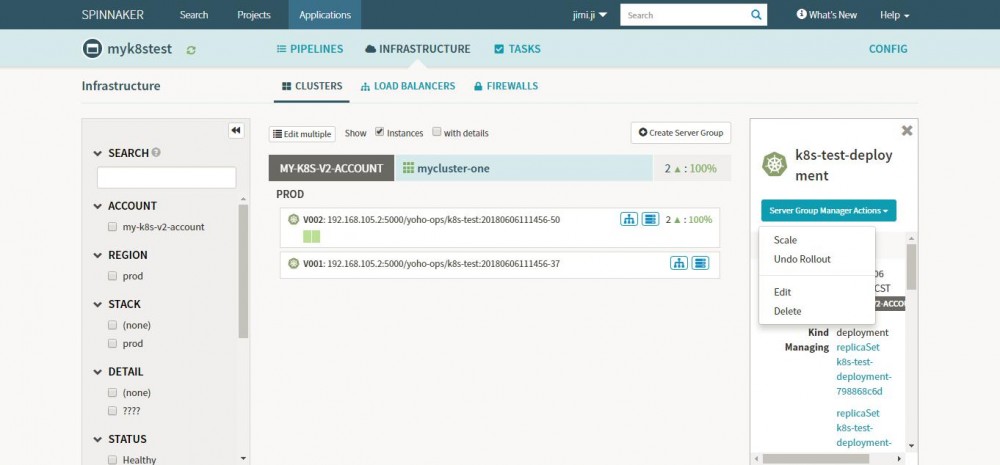
部署管理
上图中,Infrastructure左侧为Pipeline的设计:主要讲两块内容:Pipeline的创建以及基础功能,与部署的策略。
Pipeline
- 较强的Pipeline的能力:它的Pipeline可以复杂到无以复加,它还有很强的表达式功能(后续的操作中前面的参数均通过表达式获取)。
- 触发的方式:定时任务、人工触发、Jenkins job、Docker images,或者其他的Pipeline的步骤。
- 通知方式:Email、SMS or HipChat。
- 将所有的操作都融合到Pipeline中,比如回滚、金丝雀分析、关联CI等等。
部署策略
由于我们用的是Kubernetes Provider V2(Manifest Based)方式:可修改yaml中:spec.strategy.type。
- Recreate,先将所有旧的Pod停止,然后再启动新的Pod对应其中的第一种方式。
- RollingUpdate,即滚动升级,对应下图中第二种方式。
- Canary下面会单独的介绍其中的使用。
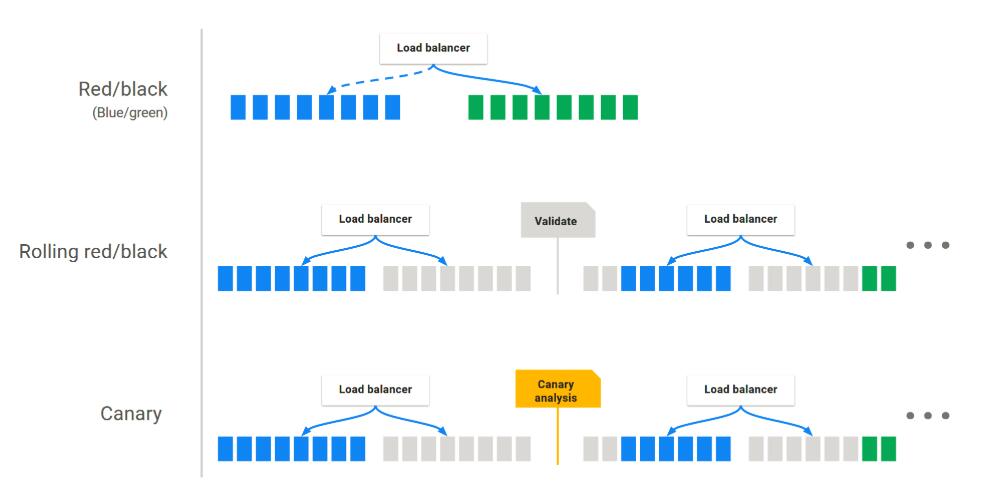
Spinnaker安装踩过的坑
很多人都是感觉这个很难安装,其实主要的原因还是墙的问题,只要把这个解决了就会方便很多,官方的文档写的很详细,而且Spinnaker的社区也非常的活跃,有问题均可以在上面进行提问。
安装提供的方式
- Halyard安装方式(官方推荐安装方式)
- Helm搭建Spinnaker平台
- Development版本安装
我采用 Halyard安装 方式,因为后期我们会集成很多其他的插件,类似于GitLab、LDAP、Kayenta,甚至多个Jenkins,Kubernetes服务等等,可配置性较强。Helm方式若是需要自定义一些个性化的内容会比较复杂,完全依赖于原始镜像,而Development需要对Spinnaker非常的熟悉,以及每个版本之间的对应关系均要了解。
Halyard方式安装注意点
Halyard代理的配置
vim /opt/halyard/bin/halyard DEFAULT_JVM_OPTS='-Dhttp.proxyHost=192.168.102.10 -Dhttps.proxyPort=3128'
部署机器选择
由于Spinnaker涉及的应用较多,下面会单独的介绍,需要消耗比较大的内存,官方推荐的配置如下:
18 GB of RAM A 4 core CPU Ubuntu 14.04, 16.04 or 18.04
Spinnaker安装步骤
- Halyard下载以及安装。
- 选择云提供者:我选择的是Kubernetes Provider V2(Manifest Based),需要在部署Spinnaker的机器上完成Kubernetes集群的认证,以及权限管理。
- 部署的时候选择安装环境:我选择的是Debian包的方式。
- 选择存储:官方推荐使用Minio,我选择的是Minio的方式。
- 选择安装的版本:我当时最新的是V1.8.0。
- 接下来进行部署工作,初次部署时间较长,会连接代理下载对应的包。
- 全部下载与完成后,查看对应的日志,即可使用localhost:9000访问即可。
完成以上的步骤则可以在Kubernetes上面部署对应的应用了。
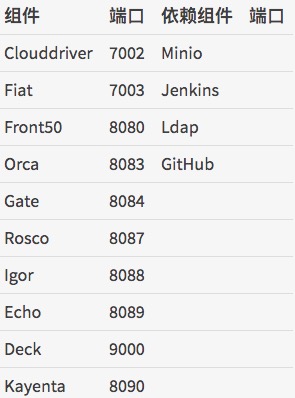
涉及的组件
下图是Spinnaker的各个组件之间的关系。
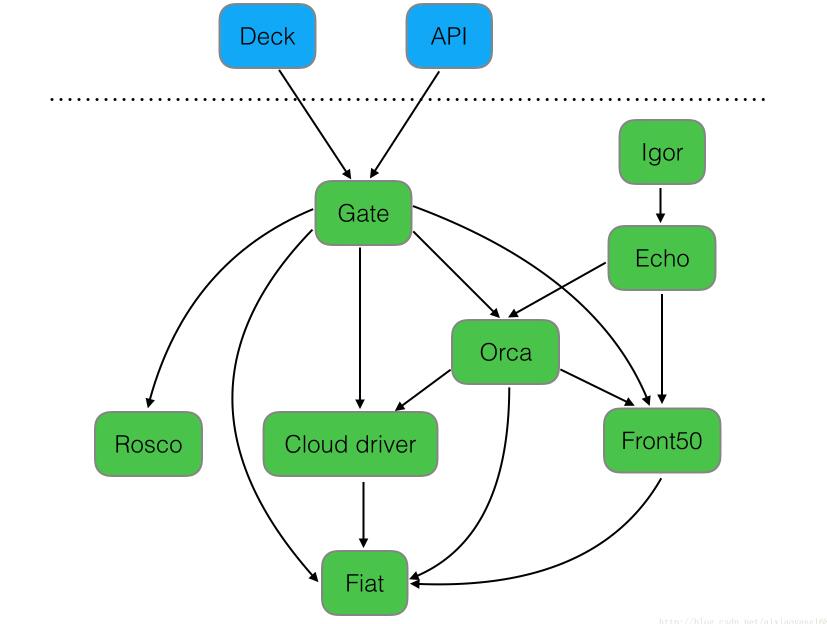
- Deck:面向用户UI界面组件,提供直观简介的操作界面,可视化操作发布部署流程。
- API:面向调用API组件,我们可以不使用提供的UI,直接调用API操作,由它后台帮我们执行发布等任务。
- Gate:是API的网关组件,可以理解为代理,所有请求由其代理转发。
- Rosco:是构建beta镜像的组件,需要配置Packer组件使用。
- Orca:是核心流程引擎组件,用来管理流程。
- Igor:是用来集成其他CI系统组件,如Jenkins等一个组件。
- Echo:是通知系统组件,发送邮件等信息。
- Front50:是存储管理组件,需要配置Redis、Cassandra等组件使用。
- Cloud driver:是用来适配不同的云平台的组件,比如Kubernetes、Google、AWS EC2、Microsoft Azure等。
- Fiat:是鉴权的组件,配置权限管理,支持OAuth、SAML、LDAP、GitHub teams、Azure groups、 Google Groups等。
Spinnaker在Kubernetes的持续部署
Pipeline部署示例
如下Pipeline设计就是开发将版本合到某一个分支后,通过Jenkins镜像构建,发布测试环境,进而自动化以及人工验证,在由人工判断是否需要发布到线上以及回滚,若是选择发布到线上则发布到prod环境,从而进行prod自动化的CI。若是选择回滚则回滚到上个版本,从而进行dev自动化的CI。

Stage-configuration
设置触发的方式,定义全局变量,执行报告的通知方式,是Pipeline的起点
Automated Triggers,其中支持多种触发的方式:定时任务Corn,Git,Jenkins,Docker Registry,Travis,Pipeline,Webhook等触发方式,从而能够满足我们自动回调的功能。
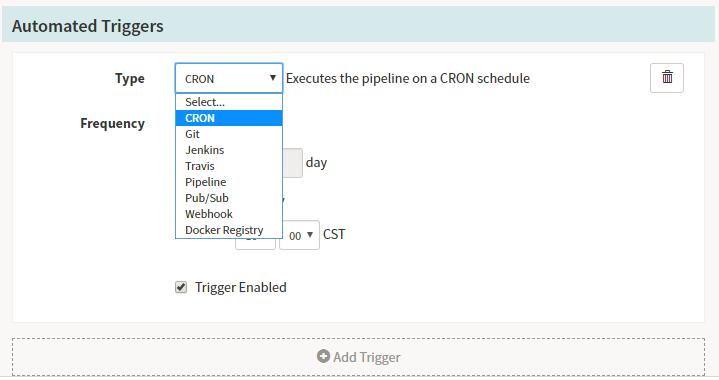
Parameters,此处定义的全局变量会在整个Pipeline中使用${ parameters['branch']}得到,这样大大的简化了我们设计Pipeline的通用性。
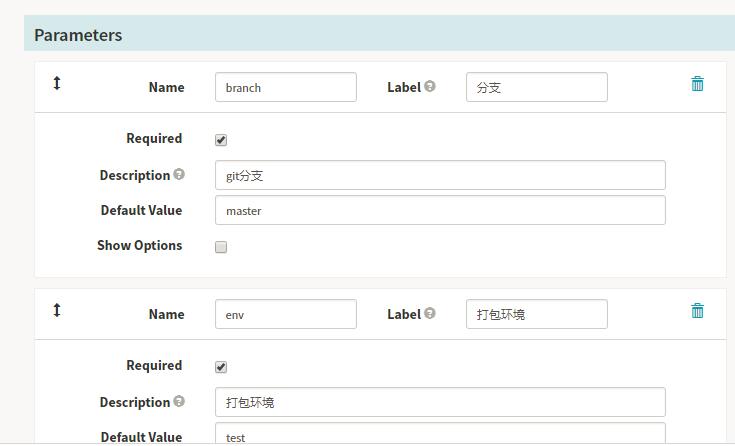
Notifications,这里通知支持:SMS,Email,HipChat等等的方式。
我们使用了邮件通知的功能:需要在echo的配置文件中加入发件邮箱的基本信息。
Stage-jenkins
调用Jenkins来执行相关的任务,其中Jenkins的服务信息存在放hal的配置文件中(如下展示),Spinnaker可自动以同步Jenkins的Job以及参数等等的信息,运行后能够看到对应的Job ID以及状态:
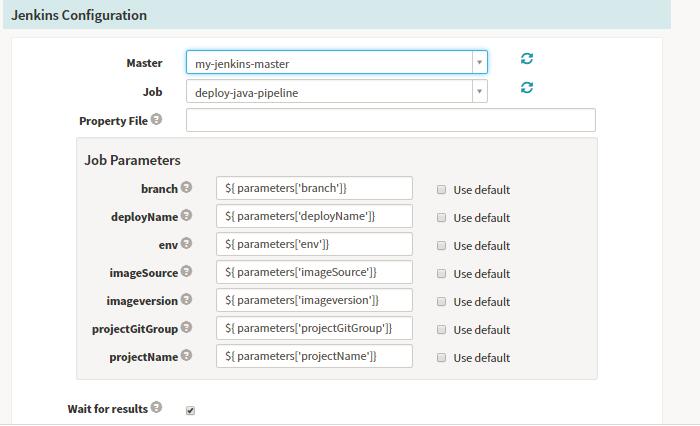
运行完成后展示如下,我们可以查看相关的build的信息,以及此stage执行的相关信息,点击build可以跳到对应的Jenkins的Job查看相关的任务信息。
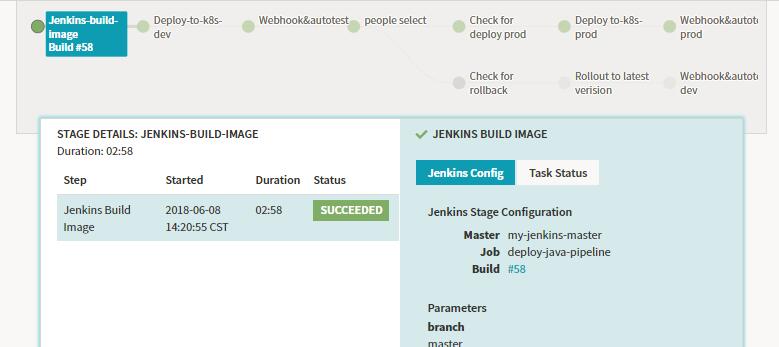
Stage-deploy
由于我们配置Spinnaker的时候采用的是Kubernetes Provider V2方式,我们的发布均采用yaml的方式来实现,可以将文件存放在GitHub中或者直接在页面上进行配置,同时yaml中文件支持了很多的参数化,这样大大的方便了我们日常的使用。
Halyard关联Kubernetes的配置信息:由于我们采用的云服务是Kubernetes,配置的时候需要将部署Spinnaker的机器对Kubernetes集群做认证。
Spinnaker发布信息展示:此处Manifest Source支持参数化形式,类似于我们写入的yaml部署文件,但是这里支持参数化的方式。
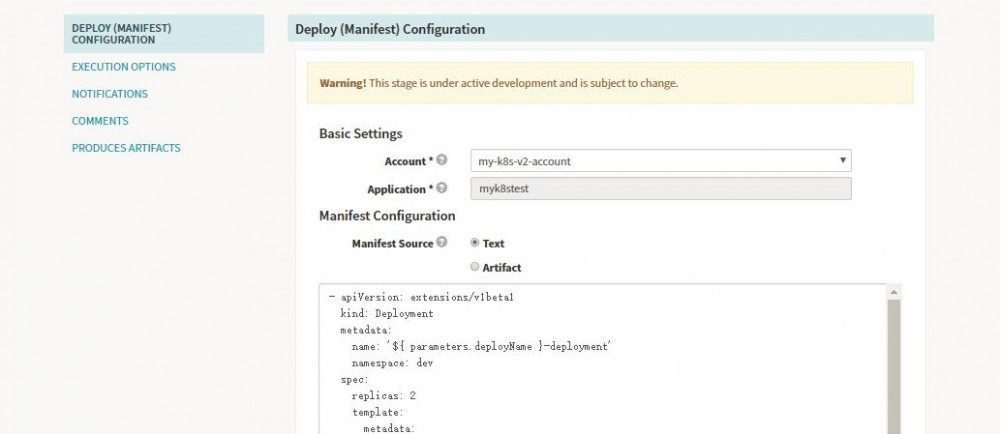
具体的配置项如下:
- apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: '${ parameters.deployName }-deployment'
namespace: dev
spec:
replicas: 2
template:
metadata:
labels:
name: '${ parameters.deployName }-deployment'
spec:
containers:
- image: >-
192.168.105.2:5000/${ parameters.imageSource }/${
parameters.deployName }:${ parameters.imageversion }
name: '${ parameters.deployName }-deployment'
ports:
- containerPort: 8080
imagePullSecrets:
- name: registrypullsecret
- apiVersion: v1
kind: Service
metadata:
name: '${ parameters.deployName }-service'
namespace: dev
spec:
ports:
- port: 8080
targetPort: 8080
selector:
name: '${ parameters.deployName }-deployment'
- apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: '${ parameters.deployName }-ingress'
namespace: dev
spec:
rules:
- host: '${ parameters.deployName }-dev.ingress.dev.yohocorp.com'
http:
paths:
- backend:
serviceName: '${ parameters.deployName }-service'
servicePort: 8080
path: /
运行结果的示例:
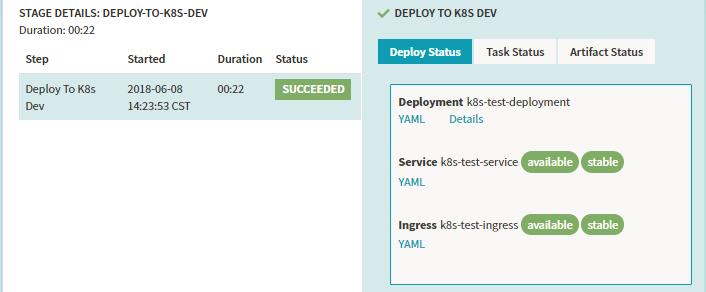
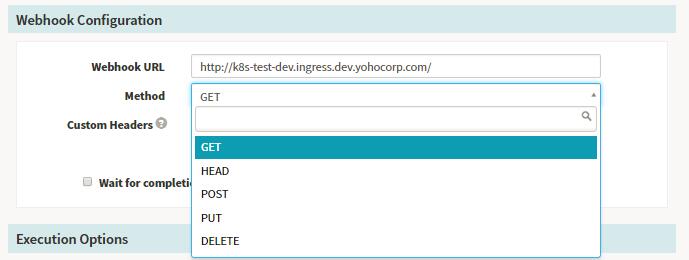
Stage-Webhook
Webhook我们可以做一些简单的环境验证以及去调用其他的服务的功能,它自身也提供了一些结果的验证功能,支持多种请求的方式。
运行结果的示例:
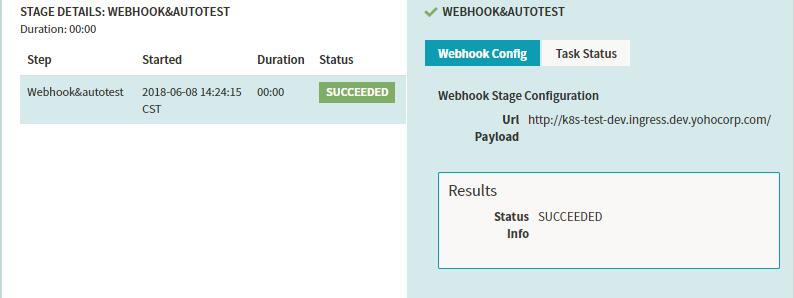
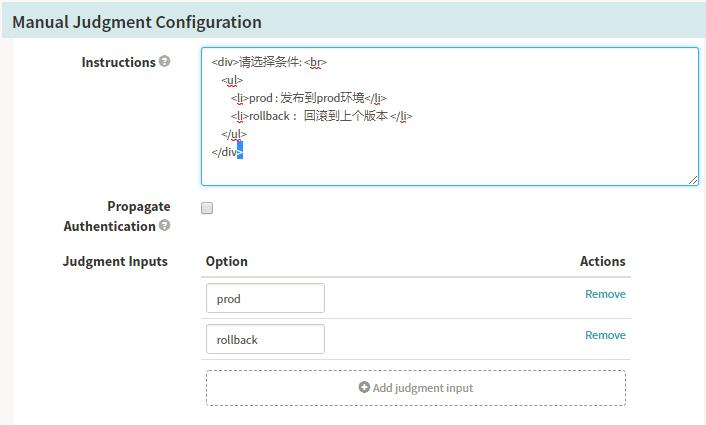
Stage-Manual Judgment
Spinnaker配置信息,用于人工的逻辑判断,增加Pipeline的控制性(比如发布到线上需要测试人员认证以及领导审批),内容支持多种语法表达的方式。
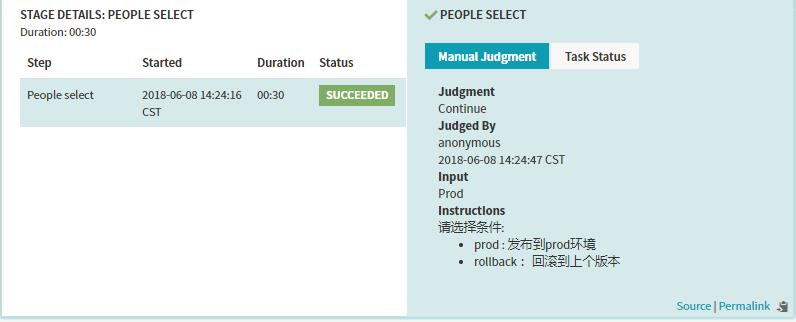
运行结果的示例:
Stage-Check Preconditions
上边Manual Judgment Stage配置了两个Judgment Inputs判断项,接下来我们建两个Check Preconditions Stage来分别对这两种判断项做条件检测,条件检测成功,则执行对应的后续Stage流程。比如上面的操作,若是选择发布到prod,则执行发布到线上的分支,若是选择执行回滚的操作则进行回滚相关的分支。
Spinnaker配置信息:
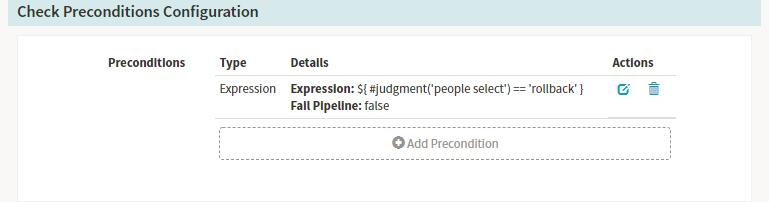
运行结果的示例:如上图中我选择了rollback。
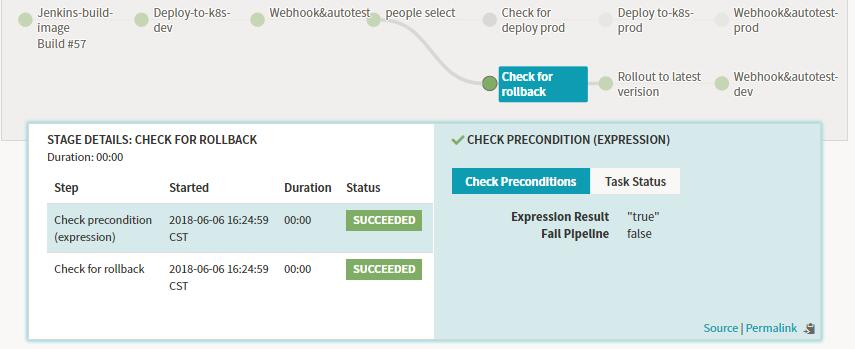
则prod分支判断为失败,会阻塞后面的stage运行。
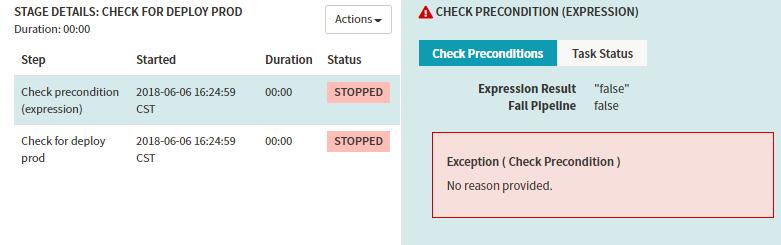
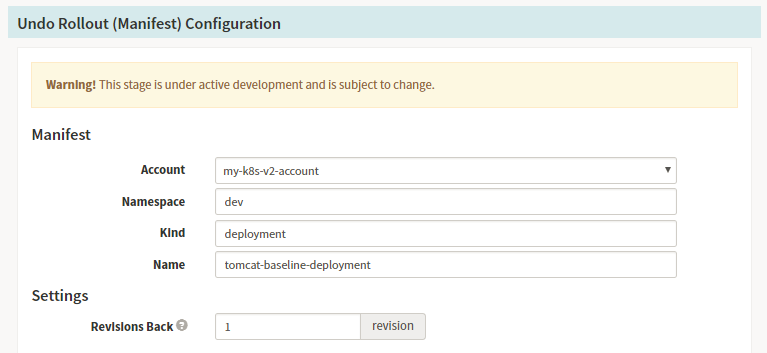
Stage-Undo Rollout(Manifest)
若是我们发布发现出现问题,也可以设计回滚的stage,Spinnaker的回滚极其的方便,在我们的日常部署中,每个版本都会存在对应的部署记录,如下所示:
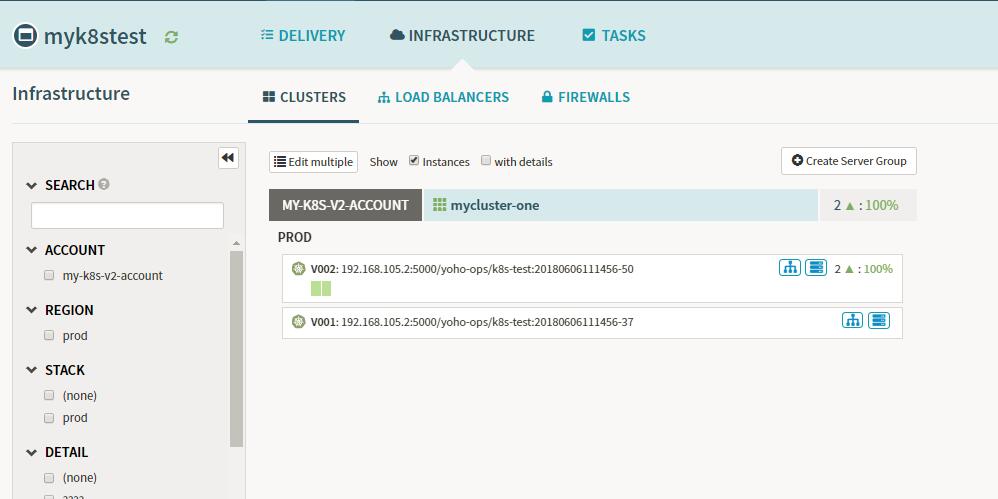
Spinnaker Pipeline配置信息:回滚的Pipeline描述中我们需要选择对应的deployment的回滚信息,以及回滚的版本数量。
运行结果的示例:
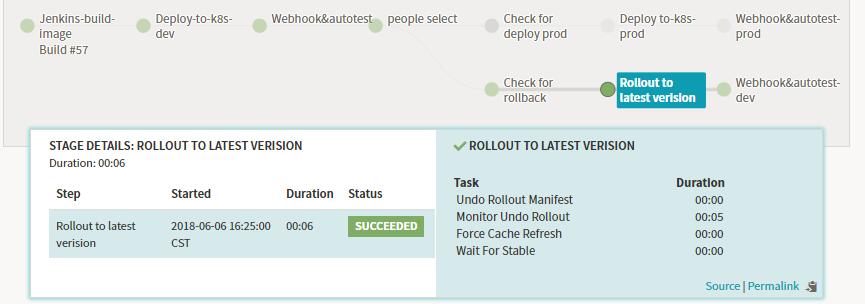
Stage-Canary Analysis
金丝雀部署方式:在我们发布新版本时引入部分流量到Canary的服务中,Kayenta会读取Spinnaker中配置的Prometheus中收集的指标,比如内存,CPU,接口超时时间,失败率等等通过Kayenta中Netflix ACA Judge来进行分析与判断,将分析的结果存于S3中,最终会给出这段时间的最终结果。
Canary分析主要经过如下四个步骤:
- 验证数据
- 清理数据
- 比对指标
- 分数计算
设计的模型如下:
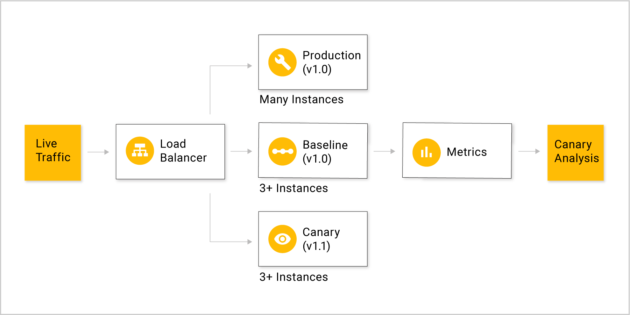
运行结果的设计与展示:
- 我们需要对应用开启Canary的配置。
- 创建出Baseline与Canary的deployment由同一个Service指向这两个deployment。
- 我们这里采用读取Prometheus的指标,需要在hal中增加Prometheus配置。Metric可以直接匹配Prometheus的指标。
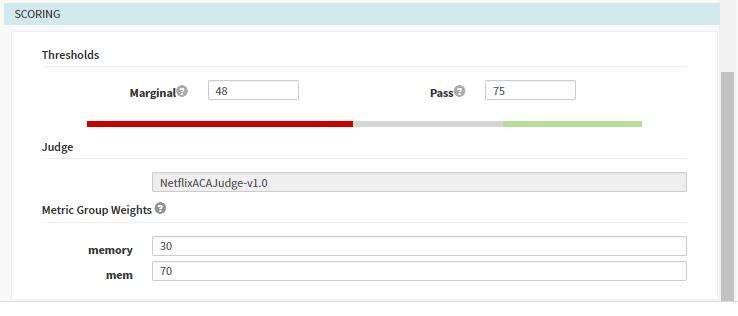
需要配置收集指标以及指标的权重: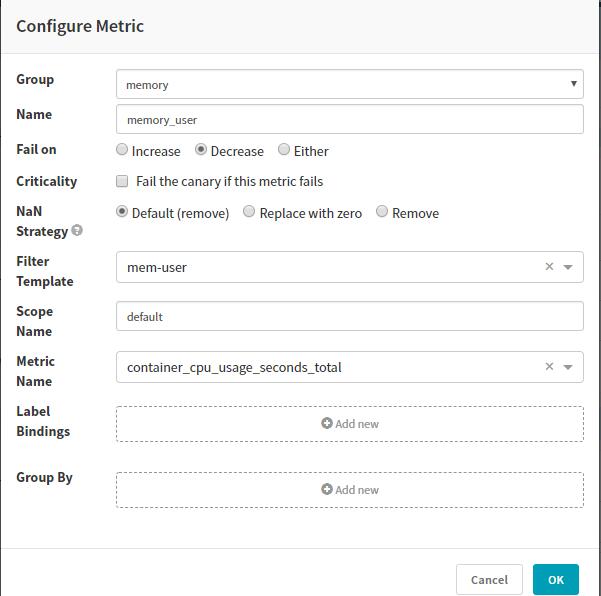
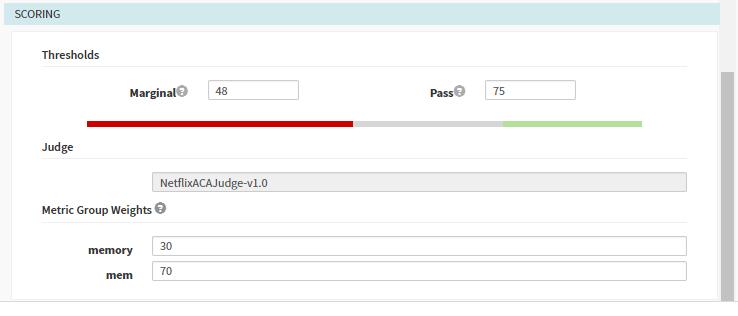
- 在Pipeline中指定收集分析的频率以及需要指定的源,同时可以配置scoring从而覆盖模板中的配置。
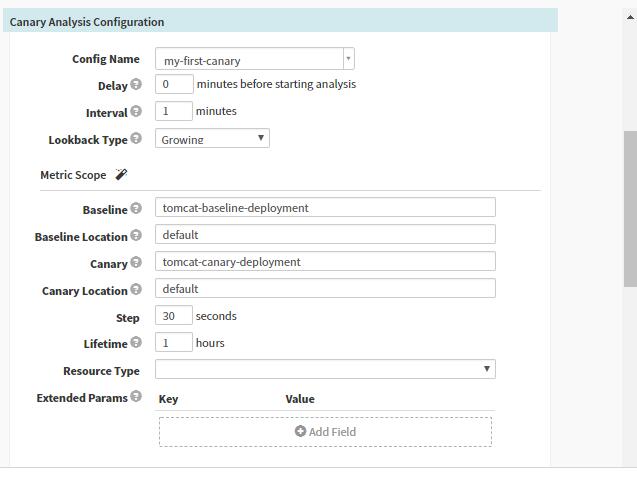
- 每次分析的执行记录:
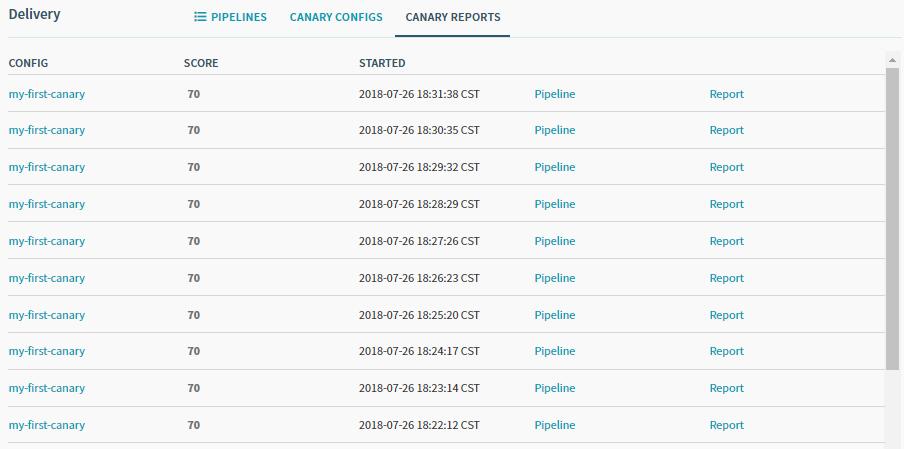
- 结果展示如下,由于我们设置的目标是75,所以pipeline的结果判定为失败。
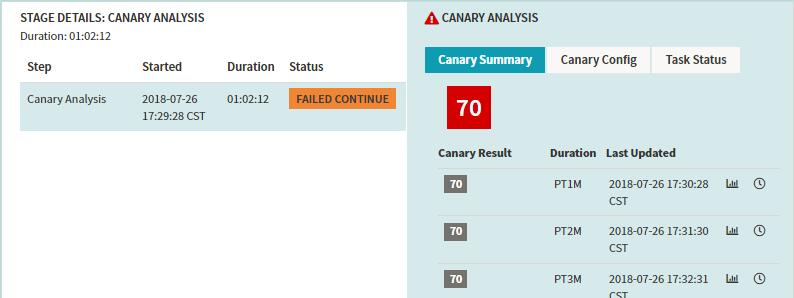
线上容器服务的选择与多区容灾
我们是腾讯云的客户,采用腾讯云容器服务主要看重以下几个方面:
- Kubernetes在自搭建的集群中,要实现Overlay网络,在腾讯云的环境里,它本身就是软件定义网络VPC,所以它在网络上的实现可以做到在容器环境里和原生的VM网络一样的快,没有任何的性能牺牲。
- 应用型负载均衡器和Kubernetes里的Ingress相关联,对于需要外部访问的服务能够快速的创建。
- 腾讯云的云储存可以被Kubernetes管理,便于持久化的操作。
- 腾讯云的部署以及告警也对外提供了服务与接口,可以更好的查看与监控相关的Node与Pod的情况。
- 腾讯云日志服务很好的与容器进行融合,能够方便的收集与检索日志。
下图是我们在线上以及灰度环境的发布示意图。
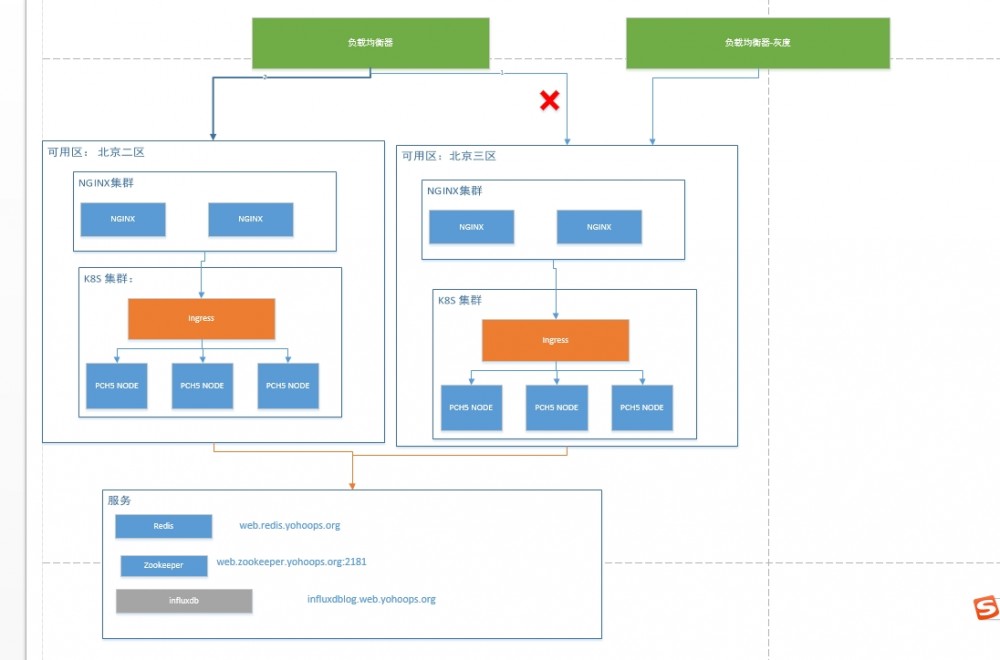
为了容灾我们使用了北京二区与北京三区两个集群,若是需要灰度验证时,则将线上北京三区的权重修改为0,这样通过灰度负载均衡器即可到达新版本应用。日常使用中二区与三区均同时提供挂服务。
Q&A
Q:为什么没有和CI结合在一起?使用这个比较重的Spannaker有什么优势?
A:可以和CI进行结合,比如Webhook的方式,或者采用Jenkins调度的方式。优势在于可以和很多云平台进行结合,而且他的Pipeline比较的完美,参数化程度很高。
Q:目前IaaS只支持OpenStack和国外的公有云厂商,国内的云服务商如果要支持的话,底层需要怎么做呢(管理云主机而不是容器)?自己实现的话容易吗?怎么入手?
A:目前我们主要使用Spinnaker用来管理容器这部分的内容,对于国内的云厂商Spinnaker支持都不是非常的好,像LB,安全策略这些都不可在Spinnaker上面控制。若是需要研究可以查看Cloud driver这个组件的功能。
Q:Spinnaker能不能在Pipeline里通过http API获取一个deployment yaml进行deploy,这个yaml可能是动态生成的?
A:部署服务有两种方式:1. 在Spinnaker的UI中直接填入Manifest Source,其实就是对应的deployment YAML,只不过这里可以写入Pipeline的参数;2. 可以从GitHub中拉取对应的文件,来部署。
Q:Spannaker的安全性方面怎么控制?
A:Spinnaker中Fiat是鉴权的组件,配置权限管理,Auth、SAML、LDAP、GitHub teams、Azure Groups、 Google Groups,我们就采用LDAP,登陆后会在上面显示对应的登陆人员。
Q: deploy和test以及rollback可以跟helm chart集成吗?
A:我觉得是可以,很笨的方法最终都是可以借助于Jenkins来实现,但是Spinnaker的回滚与部署技术很强大,在页面上点击就可以进行快速的版本回滚与部署。
Q: Spannaker之前的截图看到也有对部分用户开发的功能,用Spannaker之后还需要Istio吗?
A:这两个有不同的功能,【对部分用户开发的功能】这个是依靠创建不同的service以及Ingress来实现的,他的路由能力肯定没有Istio强悍,而且也不具备熔断等等的技术,我们线下这么创建主要为了方便开发人员进行快速的部署与调试。
以上内容根据2018年8月21日晚微信群分享内容整理。分享人 季邦华,有货质量保障工程师。2016年加入有货主导质量体系平台的构建以及线下线上容器环境的部署与监控,目前专注于微服务与容器技术的DevOps在项目组的落地 。DockOne每周都会组织定向的技术分享,欢迎感兴趣的同学加微信:liyingjiesd,进群参与,您有想听的话题或者想分享的话题都可以给我们留言。
正文到此结束
- 本文标签: struct 集群 IDE IaaS Docker 同步 删除 IO JVM 测试 cat redis GitHub 实例 provider http NIO 提问 ldap ip 产品 数据 OpenStack Select 开源 主机 Service Netflix web mail tar 调试 Google Cassandra 开发 core 调度器 工程师 update 质量 UI API Kubernetes 参数 src trigger 专注 tag Ubuntu jenkins 负载均衡 配置 管理 App 软件 build Job 模型 微服务 云 自动化 https 安装 领导 CTO 插件 线下 下载 id 测试环境 node git 安全 开源项目 时间 组织 Uber ACE MQ Proxy 认证
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

