深入理解 RxJava2:从 observeOn 到作用域(4)
前言
欢迎来到深入理解 RxJava2 系列第四篇。前一篇中我们认识了线程操作符,并详细介绍了 subscribeOn 操作符,最后一个例子给大家介绍使用该操作符的注意事项,由于篇幅问题就戛然而止了。本文将继续介绍 observeOn,并用这两者做一些比较帮助大家深刻理解它们。
observeOn
前文我们提过 subscribeOn 是对上游起作用的,而 observeOn 恰恰相反是作用于下游的,因此从某种意义上说 observeOn 的功能更加强大与丰富。
方法描述
public final Flowable<T> observeOn(Scheduler scheduler, boolean delayError, int bufferSize)
scheduler
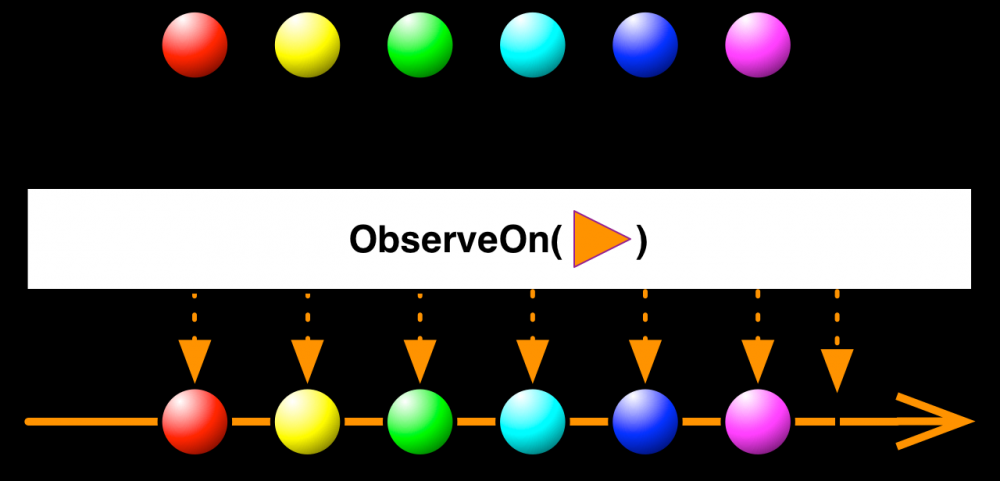
如上图所示, scheduler 在这里起的作用就是调度任务,下游消费者的 onNext / onComplete / onError 均会在传入目标 scheduler 中执行。
delayError
delayError 顾名思义,当出现错误时,是否会延迟 onError 的执行。
为什么会出现这样的情况,因为消费的方法均是在 Scheduler 中执行的,因此会有生产和消费速率不一致的情形。那么当出现错误时,可能队列里还有数据未传递给下游,因此 delayError 这个参数就是为了解决这个问题。
delayEror 默认为 false , 当出现错误时会直接越过未消费的队列中的数据,在下游处理完当前的数据后会立即执行 onError ,如下图所示:
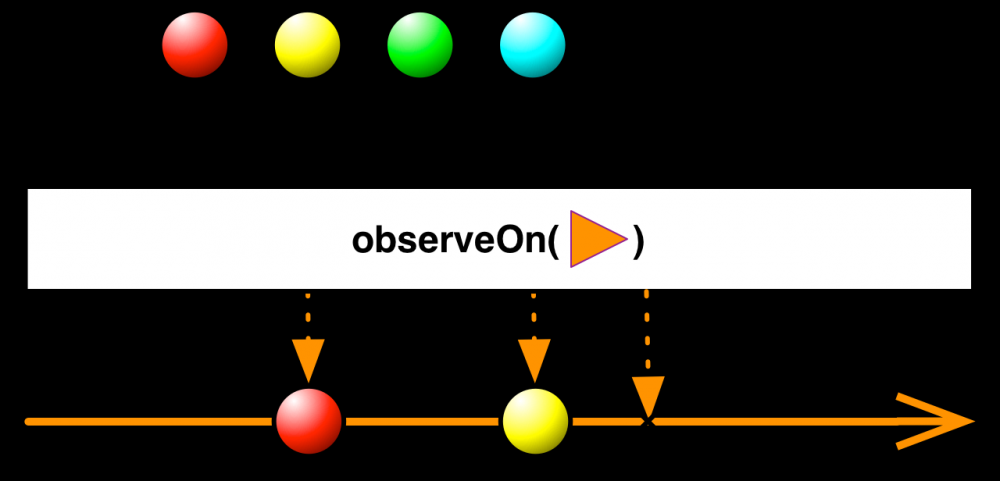
如果为 true 则会保持和上游一致的顺序向下游调度 onNext ,最后执行 onError 。
bufferSize
这里着重强调一下 bufferSize 这个参数,在 Flowable 与 Observable 的 observeOn 中都有这个参数,但是在两者中 bufferSize 的效果是完全不一样的,因为选择的数据结构不一样:
queue = new SpscArrayQueue<T>(bufferSize) queue = new SpscLinkedArrayQueue<T>(bufferSize)
SpscXXXQueue
上述的两种队列均是 RxJava 中提供的无锁的单生产者单消费者的队列,是 Fast Flow 和 BQueue 在 Java 中的实现,用以提升 RxJava 数据流的吞吐量。关于细节我们不再赘述,有兴趣的读者可以自己去搜寻。
但是在上面两个队列中, SpscArrayQueue 是一个固定长度缓存的队列,当队列满了时继续入队,Flowable 会抛出 MissingBackpressureException 。此外还有一个小细节,实际缓存的长度大于等于传入值的 2 的幂。例如传入 20 会变成 32,而传入 32 则还是 32,大家使用时请注意。
SpscLinkedArrayQueue 与 SpscArrayQueue 相似,但当队列满后会自动扩容,因此永远也不会导致 MBE,但是可能会因为消费和生产的速度不一致导致 OOM。
这里也呼应了笔者在 《深入理解 RxJava2:前世今生(1)》 中提到过的 Flowable 与 Observable 的差别。
作用域
上面我们提过, observeOn 是对下游生效的,一个简单的例子:
Flowable.just(1).observeOn(Schedulers.io())
.subscribe(i -> {
System.out.println(Thread.currentThread().getName());
});
输出:
RxCachedThreadScheduler-1
但是当有多个操作符,且存在多次 observeOn 时,每个方法都是执行在什么线程呢?
Flowable.just(1).observeOn(Schedulers.io())
.map(i -> {
System.out.println(Thread.currentThread().getName());
return i;
})
.observeOn(Schedulers.computation())
.subscribe(i -> {
System.out.println(Thread.currentThread().getName());
});
输出:
RxCachedThreadScheduler-1
RxComputationThreadPool-1
这里就涉及到一些 RxJava 实现的细节,多数操作符是基于上游调用 onNext / onComplete / onError 的进一步封装,在不涉及包含 Scheduler 的操作符的情况下,在上游调用了 observeOn 后,后续操作符的方法都是执行在上游调度的线程。因此每个操作符所执行的线程都是由上游最近的一个 observeOn 的 Scheduler 决定。
因此笔者称之为 最近生效原则 ,但是请注意, observeOn 是影响下游的,因此操作符所执行的线程受的是最近 上游 的 observeOn 影响,切莫记反了。
示例
因此在实际使用中灵活的使用 observeOn ,使得代码的效率最大化。这里笔者再举个例子:
Flowable.just(new File("input.txt"))
.map(f -> new BufferedReader(new InputStreamReader(new FileInputStream(f))))
.observeOn(Schedulers.io())
.flatMap(r -> Flowable.<String, BufferedReader>generate(() -> r, (br, e) -> {
String s = br.readLine();
if (s != null) {
e.onNext(s);
} else {
System.out.println(Thread.currentThread().getName());
e.onComplete();
}
}, BufferedReader::close))
.observeOn(Schedulers.computation())
.map(Integer::parseInt)
.reduce(0, (total, item) -> {
System.out.println(item);
return total + item;
})
.subscribe(s -> {
System.out.println("total: " + s);
System.out.println(Thread.currentThread().getName());
});
输出:
RxCachedThreadScheduler-1
1
2
3
4
5
total: 15
RxComputationThreadPool-1
如上代码所示,我们从 input.txt 读出每行的字符串,然后转成一个 int, 最后求和。这里我们灵活地使用了两次 observeOn ,在读文件时,调度至 IoScheduler ,随后做计算工作时调度至 ComputationScheduler ,从控制台的输出可以见线程的的确确是我们所期望的。当然这里求和只是一个示例,读者们可以举一反三。
事实上上面的代码还不是最优的:
Flowable.just(new File("input.txt"))
.map(f -> new BufferedReader(new InputStreamReader(new FileInputStream(f))))
.observeOn(Schedulers.io())
.flatMap(r -> Flowable.<String, BufferedReader>generate(() -> r, (br, e) -> {
String s = br.readLine();
if (s != null) {
e.onNext(s);
} else {
System.out.println(Thread.currentThread().getName());
e.onComplete();
}
}, BufferedReader::close))
.parallel()
.runOn(Schedulers.computation())
.map(Integer::parseInt)
.reduce((i, j) -> {
System.out.println(Thread.currentThread().getName());
return i + j;
})
.subscribe(s -> {
System.out.println("total: " + s);
System.out.println(Thread.currentThread().getName());
});
输出:
RxCachedThreadScheduler-1
RxComputationThreadPool-1
RxComputationThreadPool-2
RxComputationThreadPool-4
RxComputationThreadPool-4
total: 15
RxComputationThreadPool-4
如上代码所示我们可以充分利用多核的性能,通过 parallel 来并行运算,当然这里用在求和就有点杀鸡用牛刀的意思了,笔者这里只是一个举例。更多 parallel 相关的内容,留待后续分享。
subscribeOn
回到正题,事实上 subscribeOn 同样遵循 最近生效原则 ,但是与 observeOn 恰恰相反。操作符会被最近的下游的 subscribeOn 调度,因为 subscribeOn 影响的是上游。
但是和 observeOn 又有一些微妙的差别在于,我们通常调用 subscribeOn 更加关注最上游的数据源的线程。因此通常不会在中间过程中调用多次,任意的调用一次 subscribeOn 均会影响上游所有操作符的 subscribe 所在的线程,且不受 observeOn 的影响。这是由于这两者机制的不同, subscribeOn 是将整个上游的 subscribe 方法都调度到目标线程了。
多数据源
但是在一些特别的情况下 subscribeOn 多次的使用也是有意义的,尤其是上游有多个数据源时。多数据源也就是存在超过一个 Publisher 的操作符,如: zipWith / takeUntil / amb ,如果此类操作符如果在 subscribeOn 作用域内,则对应的多个数据源均会受到影响,望大家注意。
交叉对比
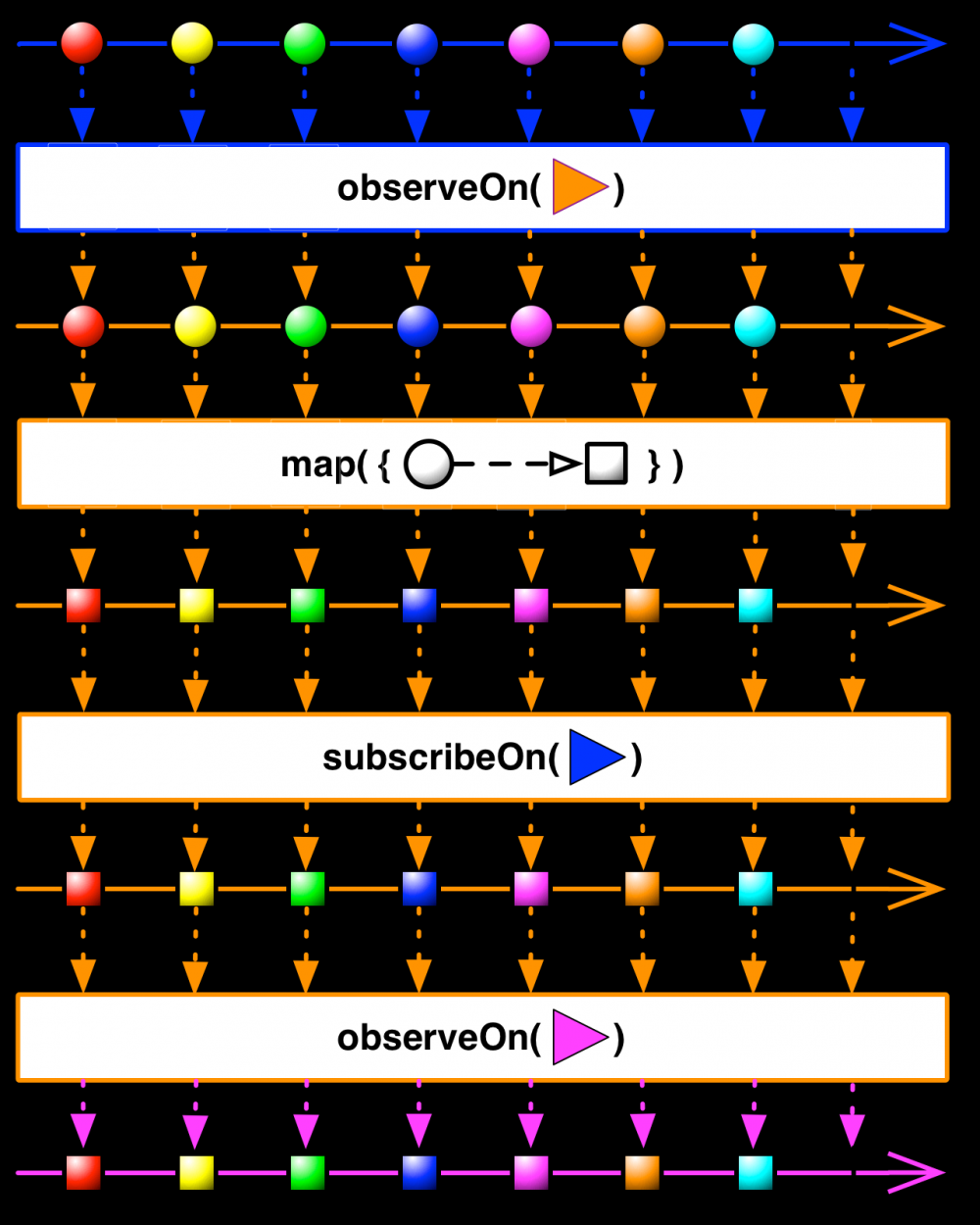
最后我们再用一个例子,将 observeOn 与 subscribeOn 混合使用,验证我们上面的结论:
Flowable.<Integer>create(t -> {
System.out.println(Thread.currentThread().getName());
t.onNext(1);
t.onComplete();
}, BackpressureStrategy.BUFFER)
.observeOn(Schedulers.io())
.map(i -> {
System.out.println(Thread.currentThread().getName());
return i;
})
.subscribeOn(Schedulers.newThread())
.observeOn(Schedulers.computation())
.subscribe(i -> {
System.out.println(Thread.currentThread().getName());
});
输出:
RxNewThreadScheduler-1
RxCachedThreadScheduler-1
RxComputationThreadPool-1
数据流的线程如下图所示:
结语
observeOn 作为 RxJava2 的核心实现自然不只是笔者上面说的那些内容。笔者有意的避开了源码,不希望同时将过多的概念灌输给大家。事实上 observeOn 的源码中深度实现了所谓的 Fusion 这个隐晦的概念,这些深层次的源码分析留到这个系列的后期,笔者也会一一分享。
感觉大家的阅读,欢迎关注笔者公众号,可以第一时间获取更新,同时欢迎留言沟通。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

