《Java8实战》-第五章读书笔记(使用流Stream-01)
在上一篇的读书笔记中,我们已经看到了流让你从外部迭代转向内部迭代。这样,你就用不着写下面这样的代码来显式地管理数据集合的迭代(外部迭代)了:
/**
* 菜单
*/
public static final List<Dish> MENU =
Arrays.asList(new Dish("pork", false, 800, Dish.Type.MEAT),
new Dish("beef", false, 700, Dish.Type.MEAT),
new Dish("chicken", false, 400, Dish.Type.MEAT),
new Dish("french fries", true, 530, Dish.Type.OTHER),
new Dish("rice", true, 350, Dish.Type.OTHER),
new Dish("season fruit", true, 120, Dish.Type.OTHER),
new Dish("pizza", true, 550, Dish.Type.OTHER),
new Dish("prawns", false, 400, Dish.Type.FISH),
new Dish("salmon", false, 450, Dish.Type.FISH));
复制代码
List<Dish> menu = Dish.MENU;
List<Dish> vegetarianDishes = new ArrayList<>();
for(Dish d: menu){
if(d.isVegetarian()){
vegetarianDishes.add(d);
}
}
复制代码
我们可以使用支持 filter 和 collect 操作的Stream API(内部迭代)管理对集合数据的迭代。 你只需要将筛选行为作为参数传递给 filter 方法就行了。
List<Dish> vegetarianDishes =
menu.stream()
.filter(Dish::isVegetarian)
.collect(toList());
复制代码
这种处理数据的方式很有用,因为你让StreamAPI管理如何处理数据。这样StreamAPI就可以在背后进行多种优化。此外,使用内部迭代的话,StreamAPI可以决定并行运行你的代码。这要是用外部迭代的话就办不到了,因为你只能用单一线程挨个迭代。接下来,你将会看到StreamAPI支持的许多操作。这些操作能让你快速完成复杂的数据查询,如筛选、切片、映射、查找、匹配和归约。
切片和筛选
我们来看看如何选择流中的元素:用谓词筛选,筛选出各不相同的元素,忽略流中的头几个元素,或将流截短至指定长度。
用谓词筛选
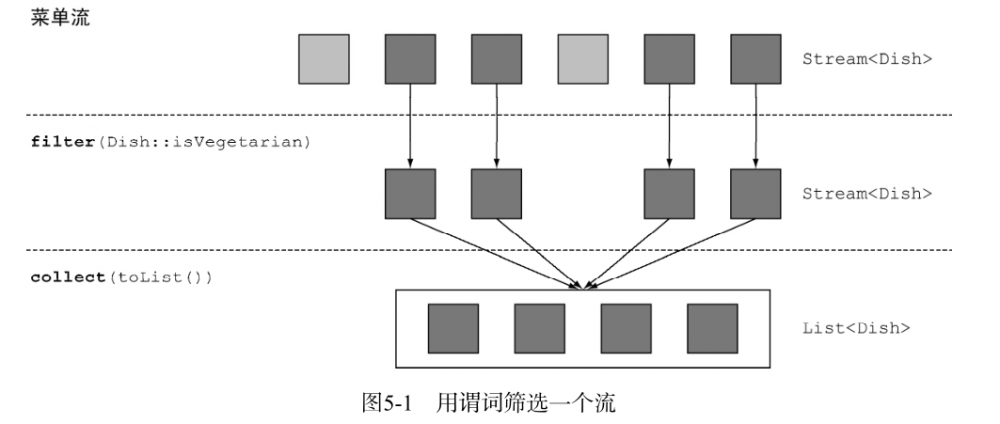
Streams 接口支持 filter方法(你现在应该很熟悉了)。该操作会接受一个谓词(一个返回boolean 的函数)作为参数,并返回一个包括所有符合谓词的元素的流。
List<Dish> vegetarianDishes =
menu.stream()
// 方法引用检查菜肴是否适合素食者
.filter(Dish::isVegetarian)
.collect(toList());
复制代码
筛选各异的元素
流还支持一个叫作 distinct 的方法,它会返回一个元素各异(根据流所生成元素的hashCode 和 equals 方法实现)的流。例如,以下代码会筛选出列表中所有的偶数,并确保没有重复。
List<Integer> numbers = Arrays.asList(1, 2, 1, 3, 3, 2, 4);
numbers.stream()
.filter(i -> i % 2 == 0)
.distinct()
.forEach(System.out::println);
复制代码
首先是筛选出偶数,然后检查是否有重复,最后打印。
截短流
流支持 limit(n) 方法,该方法会返回一个不超过给定长度的流。所需的长度作为参数传递 给 limit 。如果流是有序的,则最多会返回前 n 个元素。比如,你可以建立一个 List ,选出热量超过300卡路里的头三道菜:
List<Dish> dishes = menu.stream()
.filter(d -> d.getCalories() > 300)
.limit(3)
.collect(toList());
// pork beef chicken
dishes.forEach(dish -> System.out.println(dish.getName()));
复制代码
上面的代码展示了filter和limit的组合。我们可以看到,该方法之筛选出来了符合谓词的头三个元素,然后就立即返回了结果。请注意limit也可以放在无序流上比如源是一个 Set 。这种情况下, limit 的结果不会以任何顺序排列。
跳过元素
流还支持 skip(n) 方法,返回一个扔掉了前n个元素的流。如果流中元素不足n个,则返回一个空流。请注意,limit(n)和skip(n)是互补的!例如,下面的代码将跳过超过300卡路里的头两道菜,并返回剩下的。
List<Dish> dishes = menu.stream()
.filter(d -> d.getCalories() > 300)
// 跳过前两个
.skip(2)
.collect(toList());
// chicken french fries rice pizza prawns salmon
dishes.forEach(dish -> System.out.println(dish.getName()));
复制代码
映射
一个非常常见的数据处理套路就是从某些对象中选择信息。比如在SQL里,你可以从表中选择一列。Stream API也通过 map 和 flatMap 方法提供了类似的工具。
对流中每一个元素应用函数
流支持 map 方法,它会接受一个函数作为参数。这个函数会被应用到每个元素上,并将其映 射成一个新的元素(使用映射一词,是因为它和转换类似,但其中的细微差别在于它是“创建一 个新版本”而不是去“修改”)。例如,下面的代码把方法引用 Dish::getName 传给了 map 方法,来提取流中菜肴的名称:
List<String> dishNames = menu.stream()
.map(Dish::getName)
.collect(toList());
// [pork, beef, chicken, french fries, rice, season fruit, pizza, prawns, salmon]
System.out.println(dishNames);
复制代码
getName方法返回的是一个String,所以map方法输出的流类型就是Stream。当然,我们也可以获取通过map获取其他的属性。比如:我需要知道这个菜单的名字有多长,那么我们可以这样做:
List<Integer> len = menu.stream()
.map(dish -> dish.getName().length())
.collect(toList());
// [4, 4, 7, 12, 4, 12, 5, 6, 6]
System.out.println(len);
复制代码
是的,就是这么简单,当我们只需要获取某个对象中的某个属性时,通过map就可以实现了。
流的扁平化
你已经看到如何使用 map方法返回列表中每个菜单名称的长度了。让我们拓展一下:对于一张单词 表 , 如 何 返 回 一 张 列 表 , 列 出 里 面 各 不 相 同 的 字 符 呢 ? 例 如 , 给 定 单 词 列 表["Hello","World"] ,你想要返回列表 ["H","e","l", "o","W","r","d"] 。
你可能马上会想到,将每个单词映射成一张字符表,然后调用distance 来过滤重复的字符。
List<String> words = Arrays.asList("Hello", "World");
List<String[]> wordList = words.stream()
.map(word -> word.split(""))
.distinct()
.collect(Collectors.toList());
wordList.forEach(wordArray -> {
for (String s : wordArray) {
System.out.print(s);
}
System.out.println();
});
复制代码
执行结果:
Hello World 复制代码
执行完后一看,不对呀。仔细想一想:我们把["Hello", "World"]这两个单词把它们分割称为了字符数组,["H", "e", "l", "l", "o"],["W", "o", "r", "l", "d"]。然后将这个字符数组去判断是否重复,不是一个字符是否重复,而是这一个字符数组是否有重复。所以,打印出来就是Hello World。
幸好可以用flatMap来解决这个问题!让我们一步步地来解决它。
- 尝试使用 map 和 Arrays.stream()
首先,我们需要一个字符流,而不是数组流。有一个叫作Arrays.stream()的方法可以接受
一个数组并产生一个流,例如:
String[] arrayOfWords = {"Hello", "World"};
Stream<String> streamOfwords = Arrays.stream(arrayOfWords);
按照刚刚上面的做法,使用map和Arrays.stream(),显然是不行的。
这是因为,你现在得到的是一个流的列表(更准确地说是Stream<String>)!的确,
你先是把每个单词转换成一个字母数组,然后把每个数组变成了一个独立的流。
复制代码
- 使用 flatMap
我们可以像下面这样使用flatMap来解决这个问题:
String[] arrayOfWords = {"Hello", "World"};
Stream<String> streamOfwords = Arrays.stream(arrayOfWords);
List<String> uniqueCharacters = streamOfwords
// 将每个单词转换为由其字母构成的数组
.map(w -> w.split(""))
// 将各个生成流扁平化为单个流
.flatMap(Arrays::stream)
.distinct()
.collect(Collectors.toList());
// HeloWrd
uniqueCharacters.forEach(System.out::print);
复制代码
太棒了,实现了我们想要的效果!使用flatMap方法的效果是,各个数组并不是分别映射成为一个流,而是映射成流的内容。所有使用map(s -> split(""))时生成的单个流都被合并起来,即扁平化为一个流。一言以蔽之, flatMap 方法让你把一个流中的每个值都换成另一个流,然后把所有的流连接起来成为一个流。
查找和匹配
另一个常见的数据处理套路是看看数据集中的某些元素是否匹配一个给定的属性。Stream API通过 allMatch 、 anyMatch 、 noneMatch 、 findFirst 和 findAny 方法提供了这样的工具。
检查谓词是否至少匹配一个元素
anyMatch 方法可以回答“流中是否有一个元素能匹配给定的谓词”。比如,你可以用它来看 看菜单里面是否有素食可选择:
if(menu.stream().anyMatch(Dish::isVegetarian)){
System.out.println("有素菜,不用担心!");
}
复制代码
anyMatch 方法返回一个 boolean ,因此是一个终端操作。
检查谓词是否匹配所有元素
allMatch 方法的工作原理和 anyMatch 类似,但它会看看流中的元素是否都能匹配给定的谓词。比如,你可以用它来看看菜品是否有利健康(即所有菜的热量都低于1000卡路里):
boolean isHealthy = menu.stream().allMatch(d -> d.getCalories() < 1000); 复制代码
** noneMatch ** 和 allMatch 相对的是 noneMatch 。它可以确保流中没有任何元素与给定的谓词匹配。比如, 你可以用 noneMatch 重写前面的例子:
boolean isHealthy = menu.stream().noneMatch(d -> d.getCalories() >= 1000); 复制代码
anyMatch 、 allMatch 和 noneMatch 这三个操作都用到了我们所谓的短路,这就是大家熟悉 的Java中 && 和 || 运算符短路在流中的版本。
查找元素
findAny方法返回当前流中的任意元素。它可以与其他流结合操作使用。比如,你可能想找到一道素食菜肴。我们可以使用filter和findAny来实现:
Optional<Dish> dish = menu.stream()
.filter(Dish::isVegetarian)
.findAny();
复制代码
OK,这样就完成我们想要的了。但是,你会发现它返回的是一个Optional。Optional类(java.util.Optional)是一个容器类,代表一个值存在或者不存在。在上面的代码中,findAny可能什么都没找到。。Java 8的库设计人员引入了 Optional ,这 样就不用返回众所周知容易出问题的 null 了。很好的解决了“十亿美元的错误”!不过我们现在不讨论它,以后再去详细的了解它是如何的使用。
查找第一个元素
有些流有一个出现顺序(encounter order)来指定流中项目出现的逻辑顺序(比如由 List 或 排序好的数据列生成的流)。对于这种流,你可能想要找到第一个元素。为此有一个 findFirst 方法,它的工作方式类似于 findany 。例如,给定一个数字列表,下面的代码能找出第一个平方 能被3整除的数:
List<Integer> someNumbers = Arrays.asList(1, 2, 3, 4, 5, 6);
Optional<Integer> firstSquareDivisibleByThree =
someNumbers.stream()
.map(x -> x * x)
.filter(x -> x % 3 == 0)
// 9
.findFirst();
复制代码
是的,通过链式调用,就完成了我们想要的功能,比起以前来说好太多了。你可能有一个疑问,findAny和findFrist在什么时候使用比较好或者说两个都存在怎么办。findAny和findFrist是并行的。找到第一个元素在并行上限制的更多。如果,你不关心放回元素是哪一个,请使用findAny,因为它在使用并行流时限制比较少。
归约
到目前为止,我们见到过的终端操作都是返回一个 boolean ( allMatch 之类的)、 void ( forEach )或 Optional 对象( findAny 等)。你也见过了使用 collect 来将流中的所有元素组合成一个 List 。接下来,我们将会看到如何把一个流中的元素组合起来,使用reduce操作来表达更复杂的查询,比如“计算菜单中的总卡路里”或者“菜单中卡路里最高的菜是哪一个”。此类查询需要将流中的所有元素反复结合起来,得到一个值,比如一个Integer。这样的查询可以被归类为归约操作(将流归约成一个值)。用函数式编程语言的术语来说,这称为折叠(fold),因为你可以将这个操作看成把一张长长的纸(你的流)反复折叠成一个小方块,而这就是折叠操作的结果。
元素求和
在没有reduce之前,我们先用foreach循环来对数字列表中的元素求和:
int sum = 0;
for (int x : numbers) {
sum += x;
}
复制代码
numbers 中的每个元素都用加法运算符反复迭代来得到结果。通过反复使用加法,你把一个 数字列表归约成了一个数字。
要是还能把所有的数字相乘,而不必去复制粘贴这段代码,岂不是很好?这正是 reduce 操 作的用武之地,它对这种重复应用的模式做了抽象。你可以像下面这样对流中所有的元素求和:
List<Integer> numbers = Arrays.asList(3, 4, 5, 1, 2); int sum = numbers.stream().reduce(0, (a, b) -> a + b); // 15 System.out.println(sum); 复制代码
我们很简单的就完成了元素与元素相加最后得到的结果。如果是元素与元素相乘,也很简单:
numbers.stream().reduce(1, (a, b) -> a * b); 复制代码
是的,就是这么简单!我们还可以使用方法引用来简化求和的代码,让它看起来更加简洁:
int sum2 = numbers.stream().reduce(0, Integer::sum); 复制代码
** 无初始值 ** reduce 还有一个重载的变体,它不接受初始值,但是会返回一个 Optional 对象:
Optional<Integer> sum = numbers.stream().reduce((a, b) -> (a + b)); 复制代码
为什么它返回一个 Optional 呢?考虑流中没有任何元素的情况。 reduce 操作无 法返回其和,因为它没有初始值。这就是为什么结果被包裹在一个 Optional 对象里,以表明和 可能不存在。现在看看用 reduce 还能做什么。
最大值和最小值
原来,只要用归约就可以计算最大值和最小值了!让我们来看看如何利用刚刚学到的 reduce 来计算流中最大或最小的元素。
Optional<Integer> max = numbers.stream().reduce(Integer::max); 复制代码
reduce 操作会考虑新值和流中下一个元素,并产生一个新的最大值,直到整个流消耗完!就像这样:
3 - 4 - 5 - 1 - 2
↓
3 → 4
↓
4 → 5
↓
5 → 1
↓
5 → 2
↓
5
复制代码
通过这样的形式去比较哪个数值是最大的!如果,你获取最小的数值,也很简单只需要这样:
Optional<Integer> min = numbers.stream().reduce(Integer::min); 复制代码
好了,关于流的使用就想讲到这了,在下一节中我们将会付诸实战,而不是看完了之后不去使用它,相信过不了多久我们就会忘记的!
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

