RxJava 沉思录(二):空间维度
本文是 “RxJava 沉思录” 系列的第二篇分享。本系列所有分享:
- RxJava 沉思录(一):你认为 RxJava 真的好用吗?
- RxJava 沉思录(二):空间维度
- RxJava 沉思录(三):时间维度
- RxJava 沉思录(四):总结
在上一篇分享中,我们澄清了目前有关 RxJava 的几个最流行的误解,它们分别是:“ 链式编程是 RxJava 的厉害之处 ”,“ RxJava 等于异步加简洁 ”,“ RxJava 是用来解决 Callback Hell 的 ”。在上一篇的最后,我们了解了 RxJava 其实给我们最基础的功能就是帮我们统一了所有异步回调的接口。但是 RxJava 并不止于此,本文我们将首先介绍 Observable 在空间维度上重新组织事件的能力 。
从一个简单的例子说起
情景:有一个相册应用,从网络获取当前用户的照片列表,展示在 RecyclerView 里:
public interface NetworkApi {
@GET("/path/to/api")
Call<List<Photo>> getAllPhotos();
}
上面是使用 Retrofit 定义的从网络获取照片的 API 的接口。大家都知道,如果我们使用 Retrofit 的 RxJavaCallAdapter 就可以把接口中的返回类型从 Call<List<Photo>> 转为 Observable<List<Photo>> :
public interface NetworkApi {
@GET("/path/to/api")
Observable<List<Photo>> getAllPhotos();
}
那么我们使用这个接口展示照片的代码应该长下面这样:
NetworkApi networkApi = ...
networkApi.getAllPhotos()
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
.subscribe(photos -> {
adapter.setData(photos);
adapter.notifyDataSetChanged();
});
现在新加一个需求,请求当前用户照片列表这个网络请求,需要加入缓存功能(缓存的是网络响应中的图片的URL,图片的 Bitmap 缓存交给专门的图片加载框架,例如 Glide ),也就是说,当用户希望展示图片列表时,先去缓存读取用户的照片列表进行加载(如果缓存里有这个接口的上次访问的数据),同时发起网络请求,待网络请求返回之后,更新缓存,同时使用使用最新的返回数据刷新照片列表。如果我们选择使用 JakeWharton 的 DiskLruCache 作为我们的缓存介质,那么上面的代码将变为:
DiskLruCache cache = ...
DiskLruCache.Snapshot snapshot = cache.get("getAllPhotos");
if (snapshot != null) {
// 读取缓存数据并反序列化
List<Photo> cachedPhotos = new Gson().fromJson(
snapshot.getString(VALUE_INDEX),
new TypeToken<List<Photo>>(){}.getType()
);
// 刷新照片列表
adapter.setData(photos);
adapter.notifyDataSetChanged();
}
NetworkApi networkApi = ...
networkApi.getAllPhotos()
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
.subscribe(photos -> {
adapter.setData(photos);
adapter.notifyDataSetChanged();
// 更新缓存
DiskLruCache.Editor editor = cache.edit("getAllPhotos");
editor.set(VALUE_INDEX, new Gson().toJson(photos)).commit();
});
上面的代码就是最直观的可以解决需求的代码,我们进一步思考一下,读取文件缓存也属于耗时操作,我们最好把它封装为异步任务,既然网络请求已经被封装成 Observable 了,我们尝试把读取文件缓存也封装为 Observable :
Observable<List<Photo>> cachedObservable = Observable.create(emitter -> {
DiskLruCache.Snapshot snapshot = cache.get("getAllPhotos");
if (snapshot != null) {
List<Photo> cachedPhotos = new Gson().fromJson(
snapshot.getString(VALUE_INDEX),
new TypeToken<List<Photo>>(){}.getType()
);
emitter.onNext(cachedPhotos);
}
emitter.onComplete();
});
到目前为止,发起网络请求和读取缓存这两个异步操作都被我们封装成了 Observable 的形式,前面做了这么多铺垫,接下来进入正题:把原先的面向 Callback 的异步操作统一改写为 Observable 的形式以后,首先带来的好处就是可以对 Observable 在空间维度上进行重新组织 。
networkApi.getAllPhotos()
.doOnNext(photos ->
// 更新缓存
cache.edit("getAllPhotos")
.set(VALUE_INDEX, new Gson().toJson(photos))
.commit()
)
// 读取现有缓存
.startWith(cachedObservable)
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
.subscribe(photos -> {
adapter.setData(photos);
adapter.notifyDataSetChanged();
});
调用 startWith 操作符后,会生成一个新的 Observable,新的 Observable 会首先发射传入的 Observable 包含的元素,而后才会发射原来的 Observable 包含的元素。例如 Observable A 包含 a1, a2 两个元素, Observable B 包含 b1, b2 两个元素,那么 b.startWith(a) 返回的新 Observable 发射序列顺序为: a1, a2, b1, b2。—— 参考资料:StartWith
在上面的例子中,我们连接了网络请求和读取缓存这两个 Observable,原先需要分别处理结果的两个异步任务,我们现在把它们结合成了一个,指定了一个观察者就满足了需求。这个观察者会被回调 2 次,第一次是来自缓存的结果,第二次是来自网络的结果,体现在界面上就是列表刷新了两次。
这里引发了我们的思考,原先 Callback 的写法,如果我们有 n 个异步任务,我们就需要指定 n 个回调;而如果在 n 个异步任务都已经被封装成 Observable 的情况下,我们就可以对 Observable 进行分类、组合、变换,经过这样的处理以后,我们的观察者的数量就会减少,而且职责会变的简单而直接,只需要对它所关心的数据类型做出响应,而不需要关心数据从何而来,经历过怎样的变化。
我们再进一步,上面的例子再加一个需求:如果从网络请求回来的数据和缓存中提前响应的数据一致,就不需要再刷新一次了。也就是说,如果缓存数据和网络数据一致,那缓存数据刷新一次列表以后,网络数据不需要再去刷新一次列表了。
我们考虑一下,如果我们使用传统 Callback 的形式,指定了两个 Callback 去处理这个需求,为了保证第二次网络请求回来的相同数据不刷新,我们势必需要在两个 Callback 之外,定义一个变量来保存缓存数据,然后在网络请求的回调内,比较两个值,来决定是否需要刷新界面。
但如果我们用 RxJava 如何来实现这个需求,该如何写呢:
networkApi.getAllPhotos()
.doOnNext(photos ->
cache.edit("getAllPhotos")
.set(VALUE_INDEX, new Gson().toJson(photos))
.commit()
)
.startWith(cachedObservable)
// 保证不会出现相同数据
.distinctUntilChanged()
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
.subscribe(photos -> {
adapter.setData(photos);
adapter.notifyDataSetChanged();
});
distinctUntilChanged 操作符用来确保 Observable 发射的元素里,相邻的两个元素必须是不相等的。 参考资料:Distinct
与原先的写法相比,只多了一行 .distinctUntilChanged() ( 我们假设用于比较两个对象是否相等的 equals 方法已经实现 ),就可以满足,在网络数据和缓存数据一致的情况下,观察者只回调一次。
我们比较一下使用 Callback 的写法和使用 Observable 进行组装的写法,可以发现,使用 Callback 的写法,经常会由于需求的变化,导致 Callback 内部的逻辑发生变动,而使用 Observable 的写法,观察者的核心逻辑则较为稳定,很少发生变化(本例中为刷新列表)。 Observable 通过内置的操作符对自身发射的元素在空间维度上重新组织,或者与其他的 Observable 一起在空间维度上进行重新组织,使得观察者的逻辑简单而直接,不需要关心数据从何而来,从而使观察者的逻辑较为稳定 。
一个复杂的例子
情景:实现一个具有多种类型的 RecyclerView,如图所示:
假设列表中有 3 种类型的数据,这 3 种类型共同填充了一个 RecyclerView,简单起见,我们定义 Retrofit 接口如下:
public interface NetworkApi {
@GET("/path/to/api")
Observable<List<ItemA>> getItemListOfTypeA();
@GET("/path/to/api")
Observable<List<ItemB>> getItemListOfTypeB();
@GET("/path/to/api")
Observable<List<ItemC>> getItemListOfTypeC();
}
到目前为止,情况还是简单的, 我只要维护 3 个 RecyclerView 并分别各自更新即可。但是我们现在接到新加需求,这 3 种类型的数据在列表中出现的顺序是可配置的,而且 3 种类型数据不一定全部需要展示,也就是说可能展示 3 种,也可能只展示其中 2 种。我们定义与之对应的接口:
public interface NetworkApi {
@GET("/path/to/api")
Observable<List<ItemA>> getItemListOfTypeA();
@GET("/path/to/api")
Observable<List<ItemB>> getItemListOfTypeB();
@GET("/path/to/api")
Observable<List<ItemC>> getItemListOfTypeC();
// 需要展示的数据顺序
@GET("/path/to/api")
Observable<List<String>> getColumns();
}
新加的 getColumns 接口,返回的数据形如:
["a", "b", "c"] ["b", "a"] ["b", "c"]
首先考虑使用普通的 Callback 形式如何来实现这个需求。由于 3 种数据现在顺序可变,数量也无法确定,如果还是考虑由多个 RecyclerView 来维护的话需要在布局中调用 addView , removeView
来添加移除 RecyclerView,这样的话性能上不够好,我们考虑把所有数据填充到一个 RecyclerView 中,不同类型的数据通过不同 ItemType 进行区分。下面的代码中我依然使用了 Observable ,只是我仅仅把它当成普通的 Callback 功能使用:
private NetworkApi networkApi = ...
// 不同类型数据出现的顺序
private List<String> resultTypes;
// 这些类型对应的数据的集合
private LinkedList<List<? extends Item>> responseList;
public void refresh() {
networkApi.getColumns().subscribe(columns -> {
// 保存配置的栏目顺序
resultTypes = columns;
responseList = new LinkedList<>(Collections.nCopies(columns.size(), new ArrayList<>()));
for (String type : columns) {
switch (type) {
case "a":
networkApi.getItemListOfTypeA().subscribe(data -> onOk("a", data));
break;
case "b":
networkApi.getItemListOfTypeB().subscribe(data -> onOk("b", data));
break;
case "c":
networkApi.getItemListOfTypeC().subscribe(data -> onOk("c", data));
break;
}
}
});
}
private void onOk(String type, List<? extends Item> response) {
// 按配置的顺序,更新对应位置上的数据
responseList.set(resultTypes.indexOf(type), response);
// 把当前已返回的数据填充到一个 List 中
List<Item> data = new ArrayList<>();
for (List<? extends Item> itemList: responseList) {
data.addAll(itemList);
}
// 更新列表
adapter.setData(data);
adapter.notifyDataSetChanged();
}
上面的代码,为了避免 Callback Hell 出现,我已经提前把 onOk 提到了外部层次,使代码便于从上往下阅读。但是不知道你有没有和我相同的感觉,就是类似这样的代码总给人一种不是很 “ 内聚 ” 的感觉,就是为了把 Callback 展平,导致一些中间变量被暴露到了外层空间。
带着这个问题,我们先分析一下数据流动:
-
refresh方法发起第一次请求,得到需要被展示的 n 种数据的类型以及顺序。 - 根据第一次请求的结果,发起 n 次请求,分别得到每种数据的结果。
-
onOk方法作为观察者, 会被回调 n 次,按照第一个接口里返回的顺序正确的汇总 2 中每个数据接口返回的结果,并且通知界面更新。
有点像写作文一样,这是一种 总——分——总 的结构。
Observable 在空间维度重新组织事件
接下来我们使用 RxJava 来实现这个需求,我们会用到 RxJava 的一些操作符,来对 Observable 进行重新组织:
NetworkApi networkApi = ...
networkApi.getColumns()
.map(types -> {
List<Observable<? extends List<? extends Item>>> requestObservableList = new ArrayList<>();
for (String type : types) {
switch (type) {
case "a":
requestObservableList.add(
networkApi.getItemListOfTypeA().startWith(new ArrayList<ItemA>())
);
break;
case "b":
requestObservableList.add(
networkApi.getItemListOfTypeB().startWith(new ArrayList<ItemB>())
);
break;
case "c":
requestObservableList.add(
networkApi.getItemListOfTypeC().startWith(new ArrayList<ItemC>())
);
break;
}
}
return requestObservableList;
})
.flatMap(requestObservables -> Observable.combineLatest(requestObservables, objects -> {
List<Item> items = new ArrayList<>();
for (Object response : objects) {
items.addAll((List<? extends Item>) response);
}
return items;
}))
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
.subscribe(data -> {
adapter.setData(data);
adapter.notifyDataSetChanged();
});
我们一步一步分析 RxJava 处理的具体步骤。首先是第一步,获取需要展示的栏目列表,这是最简单的, networkApi.getColumns() 这个方法返回是一个只发射一个元素的 Observable ,这个元素即为展示的栏目列表,为了方便后续讨论,假设栏目的顺序为 ["a", "b", "c"] , 如下图所示:

接下来的操作符是 map 操作符,原来的 Observable 进行了变换,变成了一个新的 Observable ,新的 Observable 还是只发射一个元素,这个元素的类型还是 List ,只不过 List 内部的数据类型从原先的字符串(代表数据类型)变成了 Observable 。 Observable 发射的元素还可以是 “ Observable 的 List ” 吗?是的,没有什么不可以 : )
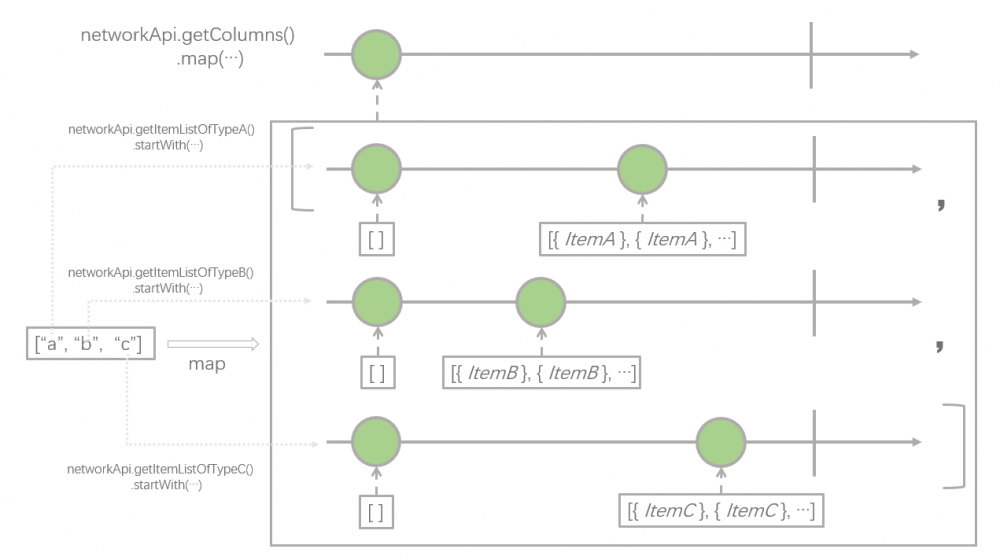
map 操作符负责把一个 Observable 里发射的元素全部进行转换,生成一个发射新的元素的 Observable ,元素的种类会发生改变,但是发射的元素的数量不会发生改变。 参考资料:Map
这个操作,在业务上的含义是,根据上一步取回的栏目列表,即 ["a", "b", "c"] ,根据不同的数据类型,分别发起请求去获取对应栏目的数据列表,例如栏目类型是 a 的话,就对应发起 networkApi.getItemListOfTypeA() 请求。这里有一点值得注意,就是每一个具体的请求后面都跟了一个 .startWith(new ArrayList<>()) ,也就是说每个具体请求栏目内容的 Observable 在返回真正的数据 List 之前都会返回一个空的 List ,这里这么处理的原因我们会在下一步中解释。
接下来这一步可能是最难理解的一步了, map 操作之后,紧接着是 flatMap 操作符,而 flatMap 操作符传入的 lambda 表达式内部,又调用了 Observable.combineLatest 操作符,我们先从里面的 combineLatest 操作符开始讲起,请看下图:
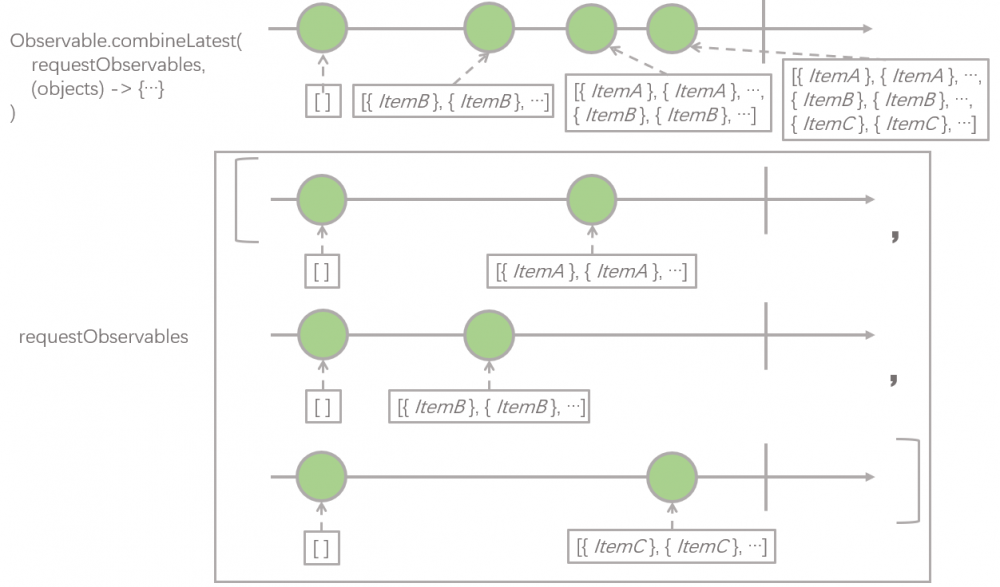
combineLatest 操作符的第一个参数 requestObservables ,它的类型是 Observable 的 List,它就是上一步中 map 操作符进行变换之后,新的 Observable 发射的数据,即由
networkApi.getItemListOfTypeA().startWith(...) networkApi.getItemListOfTypeB().startWith(...) networkApi.getItemListOfTypeC().startWith(...)
3 个 Observable 组成的 List。
combineLatest 操作符的第二个参数是个 lambda 表达式,这个 lambda 表达式的参数类型是 Object[] ,这个数组的长度等于 requestObservables 的长度, Object[] 数组中每个元素即为 requestObservables 中每个 Observable 发射的元素,即:
-
Object[0]对应requestObservables[0]发射的元素 -
Object[1]对应requestObservables[1]发射的元素 -
Object[2]对应requestObservables[2]发射的元素
那这个 lambda 表达式被调用的时机是什么时候呢?当 requestObservables 中任意一个 Observable 发射一个元素时,这个元素便会和 requestObservables 中剩余的所有 Observable 最近一次 发射的元素一起,作为参数调用这个 lambda 表达式。
那么整个 combineLatest 操作符的作用就是,返回一个新的 Observable , 根据第一个参数里输入的一组 Obsevable ,按照上面说的时机,调用第二个参数里的那个 lambda 表达式,把这个 lambda 表达式的返回值,作为新的 Observable 发射的值,lambda 被调用几次,就发射几个元素。
参考资料:CombineLatest
我们这里 lambda 表达式内部的逻辑比较简单,就是把 3 个接口里返回的数据进行汇总,组成一个新的 List 。我们再回过头看上面那张图,我们可以看到, Observable.combinLatest 返回的新的 Observable 一共发射了 4 个元素,它们分别是:
[]
[{ItemB}, {ItemB}, ...]
[{ItemA}, {ItemA}, ..., {ItemB}, {ItemB}, ...]
[{ItemA}, {ItemA}, ..., {ItemB}, {ItemB}, ..., {ItemC}, {ItemC}, ...]
前面留了一个问题没有解释,为什么 3 个获取具体的栏目数据的接口需要调用 startWith 操作符发射一个空白列表,就像这样: networkApi.getItemListOfTypeA().startWith(...) ,现在这个答案应该清晰了,如果不调用这个操作符,那么 combineLatest 操作符生成的新 Observable 将会只发射一个元素, 即上面 4 个元素的最后一个,从用户的感受来看,必须要等所有栏目全部请求成功以后才会一次性展示,而不是渐进地展示。
说完了内部的 combineLatest 操作符,现在该说外层的 flatMap 操作符了, flatMap 操作符也会生成一个新的 Observable ,它会通过传入的 lambda 表达式,把旧的 Observable 里发射的每一个元素都映射成一个 Observable ,然后把这些 Observable 发射的所有元素作为新的 Observable 发射的元素。
参考资料:FlatMap
由于我们这里的情况,调用 flatMap 之前的 Observable 只发射了一个元素,所以 flatMap 之后生成的新 Observable 发射的元素,就是 flatMap 操作符传入的那个 lambda 表达式执行完生成的那个 Observable 所发射的元素,也就是说 flatMap 操作符执行完后的那个新的 Observable 发射的元素,和我们刚刚讨论的 combineLatest 操作符执行完后的 Observable 发射的元素是一致的。
到这里为止,RxJava 实现的版本的每一步我们都解释完了,我们回过头重新梳理一下 RxJava 对 Observable 进行变换的过程,如下图:
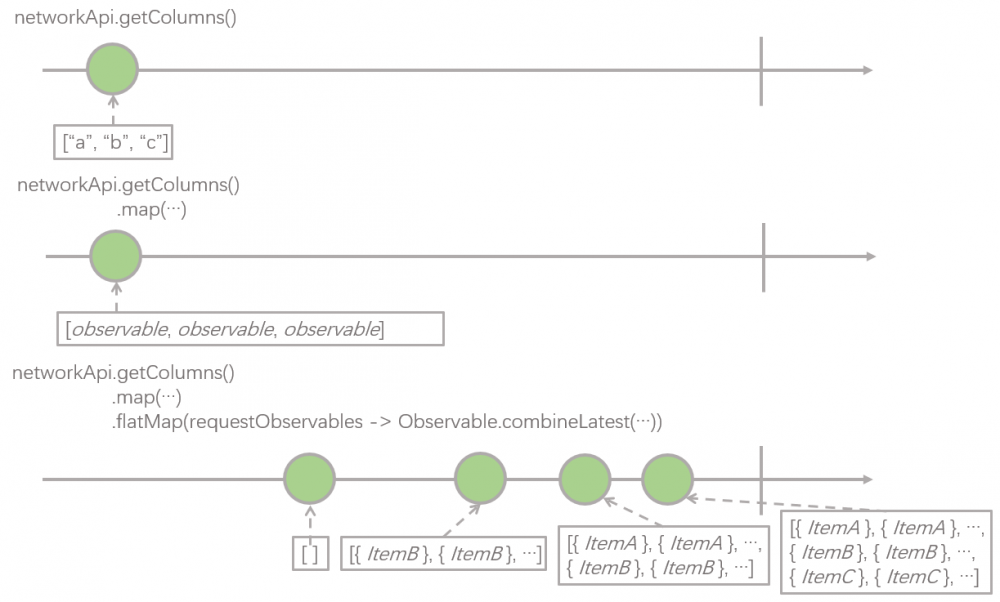
通过 RxJava 的操作符,我们把 networkApi 里的 4 个接口返回的 4 个 Observable , 在空间维度进行了重新组织 ,最终把它们转成了一个 Observable ,这个 Observable 发射的元素类型是 List<Item> ,而这正是我们的观察者 – Adapter 所关心的数据类型,观察者只需要监听这个 Observable ,并更新数据即可。
我们在讲 RxJava 实现的这个版本之前的时候,说到过 Callback 实现的版本不够 内聚 ,比较一下现在这个 RxJava 的版本,确实可以发现的确 RxJava 这个版本更内聚。但是并非 Callback 版本没有办法做到更内聚,我们可以把 Callback 版本里的 onOk , refresh , resultTypes , responseList 这几个方法和字段封装到一个对象中,对外只暴露 refresh 方法和一个设置观察者的方法,也可以做到一样的内聚,但是这就需要额外的工作量了。可如果我们使用 RxJava 就不一样了,它提供了一堆现成的操作符,通过 Observable 之间的变换与重组,直接就可以写出内聚的代码。
在上面代码里出现的所有操作符中,最核心的一个操作符就是 combineLatest 操作符,仔细比较 RxJava 版本和 Callback 版本就可以发现, combineLatest 操作符的功能其实和 Callback 版本里的 onOk 方法前半部分, resultTypes , responseList 合在一起功能是相当的,一方面负责收集多个接口返回的数据,另一方面保证收集回来的数据的顺序是和上一个接口返回的应该展示的数据的顺序是一致的。
一种更加函数式的写法
从代码量上来看,RxJava 版本与 Callback 版本相差无几,对函数式编程比较擅长的人来说,RxJava 版本里 for 循环的写法,不够 “ 函数式 ”,我们可以把原来的写法改成一种更紧凑、更函数式的写法:
NetworkApi networkApi = ...
netWorkApi.getColumns()
.flatMap(types -> Observable.fromIterable(types)
.map(type -> {
switch (type) {
case "a": return netWorkApi.getItemListOfTypeA().startWith(new ArrayList<ItemA>());
case "b": return netWorkApi.getItemListOfTypeB().startWith(new ArrayList<ItemB>());
case "c": return netWorkApi.getItemListOfTypeC().startWith(new ArrayList<ItemC>());
default: throw new IllegalArgumentException();
}
})
.<List<Observable<? extends List<? extends Item>>>>collectInto(new ArrayList<>(), List::add)
.toObservable()
)
.flatMap(requestObservables -> Observable.combineLates(requestObservables, objects -> objects))
.flatMap(objects -> Observable.fromArray(objects)
.<List<Item>>collectInto(new ArrayList<>(), (items, o) -> items.addAll((List<Item>) o))
.toObservable()
)
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
.subscribe(data -> {
adapter.setData(data);
adapter.notifyDataSetChanged();
});
这里引入了一个新的操作符 collectInto ,用于把一个 Observable 里面发射的元素,收集到一个可变的容器内部,本例中用它来替换 for 循环相关逻辑,具体内容这里不再详细展开。
小结
第二个例子花了这么大篇幅来讲,超出了我一开始的预期,这也可以看出来的确 RxJava 学习的曲线是陡峭的 ,不过我认为这个例子很好的表达我这一小节要阐述的观点,即 Observable 在空间维度上对事件的重新组织,让我们的事件驱动型编程更具想象力 ,因为原先的编程中,我们面对多少个异步任务,就会写多少个回调,如果任务之间有依赖关系,我们的做法就是修改观察者(回调函数)逻辑以及新增数据结构保证依赖关系,RxJava 给我们带来的新思路是, Observable 的事件在到达观察者之前,可以先通过操作符进行一系列变换(当然变换的规则还是和具体业务逻辑有关的),对观察者屏蔽数据产生的复杂性,只提供给观察者简单的数据接口。
那么是否在这个例子中,是否 RxJava 的版本更好呢,我个人的观点是虽然 RxJava 版本展现了其更有想象力的编程方式,但是就这个具体的例子, 两者并没有太大的差距 。RxJava 可以写出更短更内聚的代码,但是编写和理解的难度较大;Callback 版本虽然朴实无华,但是便于编写以及理解,可维护性更好。对于两者的好坏,我们也不要过于着急下结论,不妨继续看看 RxJava 还有什么其他的优势。
(未完待续)
本文属于 “RxJava 沉思录” 系列,欢迎阅读本系列的其他分享:
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

