OpenJDK系列(二):从ClassFileParser谈Endian
对TensorFlow的研究暂时告一段落.就目前看来,AI的应用场景还有待发掘,后续如果有时间将写点关于TF结合树莓派的一些玩法.
Endian
Endian即所谓的字节序,通俗点说就是多于一个类型的数据在内存中存取的顺序目前有两种字节序.
- Big-Endian: 也称为大端序:高位字节存放在内存的低地址端,低位字节存放在内存的高地址端.
- Little-Endian: 也称为小端序:高位字节存放在内存的高地址端,低位字节存放在内存的低地址端.
Endian与内存单元
对于0x12345678而言,1234是高四位,5678是低四位.再以十进制的98来说9是高位,8是低位.现在回顾下内存的抽象模型:由不同的存储单元的构成,每个存储单元容量为1个字节.
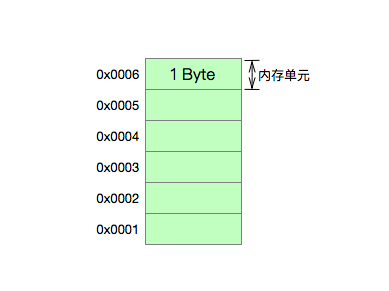
也就是说一个内存单元可以存放C语言中一个char类型数据,如果是short类型,则需要占用2个内存单元,而int类型则需要占据4个内存单元,比如int类型的305419896,其十六进制为0x12345678,需要占据4个内存单元,那这个四个内存单元中到底该如何存放数据呢?此时就用到了刚才的Endian.
如果按照Little-Endian方式,其内存布局如下:
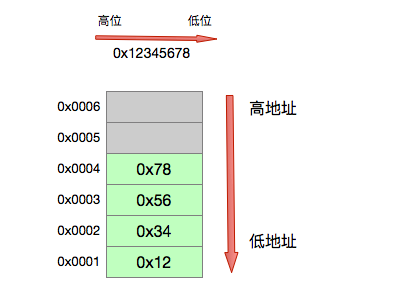
如果按照Big-Endian方法,其内存布局如下:

可以看出,对于超过一个字节类型的数据按照不同Endian会在内存中呈现不同的存放顺序,那为什么会出现大小端呢?
Endian起因
Endian产生根本原因在于CPU要想读写内存中的数据必须借助于寄存器.内存单元的容量一直保持1Byte不变,但寄存器却随着发展其容量不断增加,比如现代计算机的寄存器的容量都是超过1Byte的.这种寄存器容量和内存单元容量的差异最终导致字节序问题.寄存器如何保存超过一个字节数据必然涉及到某种顺序,这种顺序就体现在寄存器高低位的定义,而这种定义又会影响到数据在寄存器中的存放,最终在内存的存储顺序上体现出来.
Endian与Class解析
Endian和字节流解析有什么联系呢?在单机上采用同一种模式进行存取操作时,CPU会自动处理这种变化,保证数据写入和读取之后的结果一致.但涉及到网络传输或者跨平台后,就无法保证双方使用的是同一种模式,如果不一致则会导致数据问题,因此需要进行大小端的转换.
对于Java这种跨平台语言而言,同样需要关注这种差异.Java输出的字节信息都是大端模式,但JVM是却由C/C++编写的.在默认情况下C/C++的大小端模式与当前计算机硬件平台的大小端模式保持一致,如果JVM对此不做特殊处理,最终读取的字节码文件会有问题.在实际开发中,我们并不会关注该问题,这是因为JVM在读取字节码文件时做了特殊处理:如果检测到当前平台采用的是小端模式,会将其转为大端模式,以保证字节码文件的在JVM中的一致性.
整个流程可以简单描述为:当一个类需要被加载时,最终会交给classload.cpp的 load_class() ,接下来由ClassFileParser.cpp的 parse_stream() 负责解析.class文件对应ClassFileStream,在解析的过程中会根据平台的Endian来决定是否要进行转换.
ClassFileStream
ClassFileStream是用于读取.class文件的输入流,其路径为: /OpenJDK10/OpenJDK10/hotspot/src/share/vm/classfile/classFileParser.hpp
class ClassFileStream: public ResourceObj {
private:
const u1* const _buffer_start; // Buffer bottom
const u1* const _buffer_end; // Buffer top (one past last element)
mutable const u1* _current; // Current buffer position
const char* const _source; // Source of stream (directory name, ZIP/JAR archive name)
bool _need_verify; // True if verification is on for the class file
.......
}
_current 指针指向Java字节流中当前已经读取到的位置.当class文件刚被加载时, _current 指向当前字节流的第一个字节所在的位置,后续随着解析操作的不断进行, _current 指针不断的往后移动,直至当前字节流最后.
根据字节码规范,该类中定义了用于读取固定字节长度的方法:
class ClassFileStream: public ResourceObj {
......
public:
ClassFileStream(const u1* buffer,
int length,
const char* source,
bool verify_stream = verify);
u2 get_u2_fast() const {
u2 res = Bytes::get_Java_u2((address)_current);
_current += 2;
return res;
}
u4 get_u4_fast() const {
u4 res = Bytes::get_Java_u4((address)_current);
_current += 4;
return res;
}
u8 get_u8_fast() const {
u8 res = Bytes::get_Java_u8((address)_current);
_current += 8;
return res;
}
......
}
除此之外也定义用于跳过固定字节码长度的常用方法,比如: skip_u4_fast(int length) 等.在后续的字节码解析过程中,这几个方法非常常见.
ClassFileParser
ClassFileParser负责class文件解析,并尝试创建oops.创建ClassFileParser对象后会继续调用其parse_stream()`对当前类文件的字节码流进行解析.由于class文件解析相对复杂,因此这里只介绍magic number是如何被解析出来的.
void ClassFileParser::parse_stream(const ClassFileStream* const stream,
TRAPS) {
assert(stream != NULL, "invariant");
assert(_class_name != NULL, "invariant");
// BEGIN STREAM PARSING
stream->guarantee_more(8, CHECK); // magic, major, minor
// Magic value
const u4 magic = stream->get_u4_fast();
guarantee_property(magic == JAVA_CLASSFILE_MAGIC,
"Incompatible magic value %u in class file %s",
magic, CHECK);
// Version numbers
_minor_version = stream->get_u2_fast();
_major_version = stream->get_u2_fast();
......
}
按照字节码规范,字节码前三部分依次是magic number,minor_version及major_version,分别占用u4,u2,u2,即4个字节,2个字节,2个字节,总共是8个字节, guarantee_more(8, CHECK) 中的参数8含义就是如此:比较当前字节流文件剩余的长度是否大于想要读取的字节长度,否则报错.
校验通过后,调用stream的get_u4_fast()方法从字节码流中读取u4长度的字节序,即ClassFileStream中 get_u4_fast() :
u4 get_u4_fast() const {
u4 res = Bytes::get_Java_u4((address)_current);
// 读取完4个字节后,需要后移_current,因此需要对其进行+4
_current += 4;
return res;
}
在该方法中,从字节流中读取4个字节的操作由 Bytes::get_Java_u4((address)_current) 实现.其中 Bytes 是与CPU架构相关的类.我这边CPU采用的是x86架构,因此调用的是/OpenJDK10/hotspot/src/cpu/x86/vm/bytes_x86.hpp`中Bytes类:
class Bytes: AllStatic {
......
static inline u4 get_Java_u4(address p) {
// 调用模板方法get_Java()
return get_Java<u4>(p);
}
......
template <typename T>
static inline T get_Java(const address p) {
// 1.读取u4,即get_native<u4>(p)
T x = get_native<T>(p);
// 2.如果当前平台的字节序和Java不一样,即不是Big-Endian,需要进行转换
// 也就是将Little_Endian转为Big_Endian
if (Endian::is_Java_byte_ordering_different()) {
//3.大小端转换,即swap<u4>(x)
x = swap<T>(x);
}
return x;
}
}
在模板方法 get_Java() 先是调用与平台相关的函数 get_native<u4>() 来读取4个字节:
class Bytes: AllStatic {
template <typename T>
static inline T get_native(const void* p) {
assert(p != NULL, "null pointer");
T x;
// is_aligned()用于判断当前值是否对齐与给定值,未对齐则使用memcpy从p指针出拷贝u4数据到x
if (is_aligned(p, sizeof(T))) {
// 此处由于是读取u4,因此最终将指针p强转为u4*类型的指针.
x = *(T*)p;
} else {
memcpy(&x, p, sizeof(T));
}
return x;
}
......
}
读取完成后判断当前平台的模式是否和Java中的一致,即当前是否是大端模式,如果不是则继续调用 swap<u4>() 实现小端到大端的转换.
class Bytes: AllStatic {
......
// Efficient swapping of byte ordering
template <typename T>
static T swap(T x) {
switch (sizeof(T)) {
case sizeof(u1): return x;
case sizeof(u2): return swap_u2(x);
case sizeof(u4): return swap_u4(x);
case sizeof(u8): return swap_u8(x);
default:
guarantee(false, "invalid size: " SIZE_FORMAT "/n", sizeof(T));
return 0;
}
}
static inline u2 swap_u2(u2 x); // compiler-dependent implementation
static inline u4 swap_u4(u4 x); // compiler-dependent implementation
static inline u8 swap_u8(u8 x);
}
需要注意swap_u4()是夸平台,为了兼容,可以看到在 /OpenJDK10/OpenJDK10/hotspot/src/os_cpu 根据平台进行了不同的实现,比如我这边用的是:
/OpenJDK10/hotspot/src/os_cpu/bsd_x86/vm/bytes_bsd_x86.inline.hpp
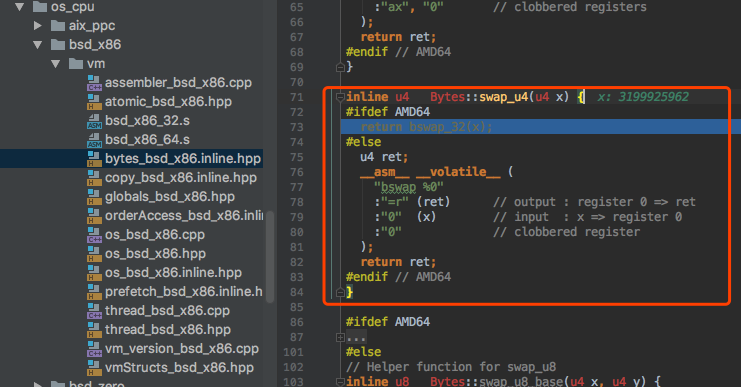
此处内嵌了一段汇编代码来实现大小端的转换.至此,我们已经清楚JVM是如何统一成大端模式的.最新文章见 浮游 .
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

