编写高性能 Java 代码的最佳实践
摘要:本文首先介绍了负载测试、基于APM工具的应用程序和服务器监控,随后介绍了编写高性能Java代码的一些最佳实践。最后研究了JVM特定的调优技巧、数据库端的优化和架构方面的调整。以下是译文。
介绍
在这篇文章中,我们将讨论几个有助于提升Java应用程序性能的方法。我们首先将介绍如何定义可度量的性能指标,然后看看有哪些工具可以用来度量和监控应用程序性能,以及确定性能瓶颈。
我们还将看到一些常见的Java代码优化方法以及最佳编码实践。最后,我们将看看用于提升Java应用程序性能的JVM调优技巧和架构调整。
请注意,性能优化是一个很宽泛的话题,而本文只是对JVM探索的一个起点。
性能指标
在开始优化应用程序的性能之前,我们需要理解诸如可扩展性、性能、可用性等方面的非功能需求。
以下是典型Web应用程序常用的一些性能指标:
-
应用程序平均响应时间
-
系统必须支持的平均并发用户数
-
在负载高峰期间,预期的每秒请求数
这些指标可以通过使用多种监视工具监测到,它们对分析性能瓶颈和性能调优有着非常大的作用。
示例应用程序
我们将使用一个简单的Spring Boot Web应用程序作为示例,在这篇文章中有相关的介绍。这个应用程序可用于管理员工列表,并对外公开了添加和检索员工的REST API。
我们将使用这个程序作为参考来运行负载测试,并在接下来的章节中监控各种应用指标。
找出性能瓶颈
负载测试工具和应用程序性能管理(APM)解决方案常用于跟踪和优化Java应用程序的性能。要找出性能瓶颈,主要就是对各种应用场景进行负载测试,并同时使用APM工具对CPU、IO、堆的使用情况进行监控等等。
Gatling是进行负载测试最好的工具之一,它提供了对HTTP协议的支持,是HTTP服务器负载测试的绝佳选择。
Stackify的Retrace是一个成熟的APM解决方案。它的功能很丰富,对确定应用程序的性能基线很有帮助。 Retrace的关键组件之一是它的代码分析功能,它能够在不减慢应用程序的情况下收集运行时信息。
Retrace还提供了监视基于JVM应用程序的内存、线程和类的小部件。除了应用程序本身的指标之外,它还支持监视托管应用程序的服务器的CPU和IO使用情况。
因此,像Retrace这样功能全面的监控工具是解锁应用程序性能潜力的第一步。而第二步则是在你的系统上重现真实使用场景和负载。
说起来容易,做起来难,而且了解应用程序当前的性能也非常重要。这就是我们接下来要关注的问题。
Gatling负载测试
Gatling的模拟测试脚本是用Scala编写的,但该工具还附带了一个非常有用的图形界面,可用于记录具体的场景,并生成Scala脚本。
在运行模拟脚本之后,Gatling会生成一份非常有用的、可用于分析的HTML报告。
定义场景
在启动记录器之前,我们需要定义一个场景,表示用户在浏览Web应用时发生的事情。
在我们的这个例子中,具体的场景将是“启动200个用户,每个用户发出一万个请求。”
配置记录器
根据“Gatling的第一步”所述,用下面的代码创建一个名为EmployeeSimulation的scala文件:
class EmployeeSimulation extends Simulation {
val scn = scenario("FetchEmployees").repeat(10000) {
exec(
http("GetEmployees-API")
.get("http://localhost:8080/employees")
.check(status.is(200))
)
}
setUp(scn.users(200).ramp(100))
}复制代码
运行负载测试
要执行负载测试,请运行以下命令:
$GATLING_HOME/bin/gatling.sh-sbasic.EmployeeSimulation复制代码
对应用程序的API进行负载测试有助于发现及其细微的并且难以发现的错误,如数据库连接耗尽、高负载情况下的请求超时、因为内存泄漏而导致堆的高使用率等等。
监控应用程序
要使用Retrace进行Java应用程序的开发,首先需要在Stackify上申请免费试用账号。然后,将我们自己的Spring Boot应用程序配置为Linux服务。我们还需要在托管应用程序的服务器上安装Retrace代理,按照这篇文章所述的操作即可。
Retrace代理和要监控的Java应用程序启动后,我们就可以到Retrace仪表板上单击AddApp按钮添加应用了。添加应用完成之后,Retrace将开始监控应用程序了。
找到最慢的那个点
Retrace会自动监控应用程序,并跟踪数十种常见框架及其依赖关系的使用情况,包括SQL、MongoDB、Redis、Elasticsearch等等。Retrace能帮助我们快速确定应用程序为什么会出现如下性能问题:
-
某个SQL语句是否会拖慢系统的速度?
-
Redis突然变慢了吗?
-
特定的HTTP Web服务宕了,还是变慢了?
例如,下面的图形展示了在一段给定的时间内速度最慢的组件。
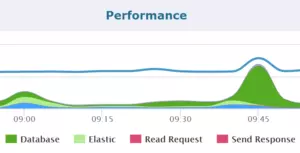
代码级别的优化
负载测试和应用程序监控对于确定应用程序的一些关键性能瓶颈非常有用。但同时,我们需要遵循良好的编码习惯,以避免在对应用程序进行监控的时候出现过多的性能问题。
在下一章节中,我们将来看一些最佳实践。
使用StringBuilder来连接字符串
字符串连接是一个非常常见的操作,也是一个低效率的操作。简单地说,使用+=来追加字符串的问题在于每次操作都会分配新的String。
下面这个例子是一个简化了的但却很典型的循环。前面使用了原始的连接方式,后面使用了构建器:
public String stringAppendLoop() {
String s = ""; for (int i = 0; i < 10000; i++) { if (s.length() > 0)
s += ", ";
s += "bar";
} return s;
}public String stringAppendBuilderLoop() {
StringBuilder sb = new StringBuilder(); for (int i = 0; i < 10000; i++) { if (sb.length() > 0)
sb.append(", ");
sb.append("bar");
} return sb.toString();
}复制代码
上面代码中使用的StringBuilder对性能的提升非常有效。请注意,现代的JVM会在编译或者运行时对字符串操作进行优化。
避免递归
导致出现StackOverFlowError错误的递归代码逻辑是Java应用程序中另一种常见的问题。如果无法去掉递归逻辑,那么尾递归作为替代方案将会更好。
我们来看一个头递归的例子:
public int factorial(int n) { if (n == 0) { return 1;
} else { return n * factorial(n - 1);
}
}复制代码
现在我们把它重写为尾递归:
private int factorial(int n, int accum) { if (n == 0) { return accum;
} else { return factorial(n - 1, accum * n);
}
}public int factorial(int n) { return factorial(n, 1);
}复制代码
其他JVM语言(如Scala)已经在编译器级支持尾递归代码的优化,当然,对于这种优化目前也存在着一些争议。
谨慎使用正则表达式
正则表达式在很多场景中都非常有用,但它们往往具有非常高的性能成本。了解各种使用正则表达式的JDK字符串方法很重要,例如String.replaceAll()、String.split()。
如果你不得不在计算密集的代码段中使用正则表达式,那么需要缓存Pattern的引用而避免重复编译:
static final Pattern HEAVY_REGEX = Pattern.compile("(((X)*Y)*Z)*");复制代码
使用一些流行的库,比如Apache Commons Lang也是一个很好的选择,特别是在字符串的操作方面。
避免创建和销毁过多的线程
线程的创建和处置是JVM出现性能问题的常见原因,因为线程对象的创建和销毁相对较重。
如果应用程序使用了大量的线程,那么使用线程池会更加有用,因为线程池允许这些昂贵的对象被重用。
为此,Java的ExecutorService是线程池的基础,它提供了一个高级API来定义线程池的语义并与之进行交互。
Java 7中的Fork/Join框架也值得提一下,因为它提供了一些工具来尝试使用所有可用的处理器核心以帮助加速并行处理。为了提高并行执行效率,框架使用了一个名为ForkJoinPool的线程池来管理工作线程。
JVM调优
堆大小的调优
为生产系统确定合适的JVM堆大小并不是一件简单的事情。要做的第一步是回答以下问题以预测内存需求:
-
计划要把多少个不同的应用程序部署到单个JVM进程中,例如EAR文件、WAR文件、jar文件的数量是多少?
-
在运行时可能会加载多少个Java类,包括第三方API的类?
-
估计内存缓存所需的空间,例如,由应用程序(和第三方API)加载的内部缓存数据结构,比如从数据库缓存的数据、从文件中读取的数据等等。
-
估计应用程序将创建的线程数。
如果没有经过真实场景的测试,这些数字很难估计。
要获得有关应用程序需求的最好最可靠的方法是对应用程序执行实际的负载测试,并在运行时跟踪性能指标。我们之前讨论的基于Gatling的测试就是一个很好的方法。
选择合适的垃圾收集器
Stop-the-world(STW)垃圾收集的周期是影响大多数面向客户端应用程序响应和整体Java性能的大问题。但是,目前的垃圾收集器大多解决了这个问题,并且通过适当的优化和大小的调整,能够消除对收集周期的感知。
分析器、堆转储和详细的GC日志记录工具对此有一定的帮助作用。再一次注意,这些都需要在真实场景的负载模式下进行监控。
有关不同垃圾收集器的更多信息,请查看这个指南。
JDBC性能
关系型数据库是Java应用程序中另一个常见的性能问题。为了获得完整请求的响应时间,我们很自然地必须查看应用程序的每一层,并思考如何让代码与底层SQL DB进行交互。
连接池
让我们从众所周知的事实开始,即数据库连接是昂贵的。 连接池机制是解决这个问题非常重要的第一步。
这里建议使用HikariCP JDBC,这是一个非常轻量级(大约130Kb)并且速度极快的JDBC连接池框架。
JDBC批处理
持久化处理应尽可能地执行批量操作。 JDBC批处理允许我们在单次数据库交互中发送多个SQL语句。
这样,无论是在驱动端还是在数据库端,性能都可能得到显著地提升。 * PreparedStatement*是一个非常棒的的批处理命令,一些数据库系统(例如Oracle)只支持预处理语句的批处理。
另一方面,Hibernate则更加灵活,它允许我们只需修改一个配置即可快速切换为批处理操作。
语句缓存
语句缓存是另一种提高持久层性能的方法,这是一种鲜为人知但又容易掌握的性能优化方法。
只要底层的JDBC驱动程序支持,你就可以在客户端(驱动程序)或数据库端(语法树甚至执行计划)中缓存PreparedStatement。
规模的缩放
数据库复制和分片是提高吞吐量非常好的方法,我们应该充分利用这些经过实践检验的架构模式,以扩展企业应用的持久层。
架构改进
缓存
现在内存的价格很低,而且越来越低,从磁盘或通过网络来检索数据的性能代价仍然很高。缓存自然而然的变成了在应用程序性能方面不能忽视的关键。
当然,在应用的拓扑结构中引入一个独立的缓存系统确实会增加架构的复杂度,所以,应当充分利用当前使用的库和框架现有的缓存功能。
例如,大多数的持久化框架都支持缓存。 Spring MVC等Web框架还可以使用Spring中内置的缓存支持,以及基于ETags的强大的HTTP级缓存。
横向扩展
无论我们在单个实例中准备了多少硬件,都会有不够用的时候。简而言之,扩展有着天生的局限性,当系统遇到这些问题时,横向扩展是处理更多负载的唯一途径。这一步肯定会相当的复杂,但却是扩展应用的唯一办法。
对大多数的现代框架和库来说,这方面还是支持得很好的,而且会变得越来越好。 Spring生态系统有一个完整的项目集,专门用于解决这个特定的应用程序架构领域,其他大多数的框架也都有类似的支持。
除了能够提升Java的性能,通过集群进行横向扩展也有其他的好处,添加新的节点能产生冗余,并更好的处理故障,从而提高整个系统的可用性。
结论
在这篇文章中,我们围绕着提升Java应用的性能探讨了许多概念。我们首先介绍了负载测试、基于APM工具的应用程序和服务器监控,随后介绍了编写高性能Java代码的一些最佳实践。最后,我们研究了JVM特定的调优技巧、数据库端的优化和架构方面的调整。
来源:雁惊寒
正文到此结束
- 本文标签: HTML 性能问题 免费 HTTP协议 JDBC linux 协议 进程 管理 App final 文章 IO 连接池 编译 线程 redis CTO 锁 ACE executor JVM 服务器 数据库 数据 空间 开发 http Service 回答 递归 web Oracle UI 时间 快的 src HTTP服务器 性能优化 tag apache 配置 REST build 处理器 mongo 并发 java https 安装 需求 实例 企业 scala Elasticsearch 缓存 spring db sql 代码 MongoDB Java类 线程池 Spring Boot Statement 正则表达式 测试 集群 API
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

