Map大家族的那点事儿(4) :HashMap – 解决冲突
解决冲突
在上文中我们已经多次提到碰撞冲突,但是散列函数不可能是完美的,key分布完全均匀的情况是不存在的,所以碰撞冲突总是难以避免。
那么发生碰撞冲突时怎么办?总不能丢弃数据吧?必须要有一种合理的方法来解决这个问题,HashMap使用了叫做分离链接(Separate chaining,也有人翻译成拉链法)的策略来解决冲突。它的主要思想是每个bucket都应当是一个互相独立的数据结构,当发生冲突时,只需要把数据放入bucket中(因为bucket本身也是一个可以存放数据的数据结构),这样查询一个key所消耗的时间为访问bucket所消耗的时间加上在bucket中查找的时间。
HashMap的buckets数组其实就是一个链表数组,在发生冲突时只需要把Entry(还记得Entry吗?HashMap的Entry实现就是一个简单的链表节点,它包含了key和value以及hash code)放到链表的尾部,如果未发生冲突(位于该下标的bucket为null),那么就把该Entry做为链表的头部。而且HashMap还使用了Lazy策略,buckets数组只会在第一次调用 put() 函数时进行初始化,这是一种防止内存浪费的做法,像ArrayList也是Lazy的,它在第一次调用 add() 时才会初始化内部的数组。

不过链表虽然实现简单,但是在查找的效率上只有 O(n) ,而且我们大部分的操作都是在进行查找,在 hashCode() 设计的不是非常良好的情况下,碰撞冲突可能会频繁发生,链表也会变得越来越长,这个效率是非常差的。Java 8对其实现了优化,链表的节点数量在到达阈值时会转化为红黑树,这样查找所需的时间就只有 O(log n) 了,阈值的定义如下:
/** * The bin count threshold for using a tree rather than list for a * bin. Bins are converted to trees when adding an element to a * bin with at least this many nodes. The value must be greater * than 2 and should be at least 8 to mesh with assumptions in * tree removal about conversion back to plain bins upon * shrinkage. */ static final int TREEIFY_THRESHOLD = 8;
如果在插入Entry时发现一条链表超过阈值,就会执行以下的操作,对该链表进行树化;相对的,如果在删除Entry(或进行扩容)时发现红黑树的节点太少(根据阈值UNTREEIFY_THRESHOLD),也会把红黑树退化成链表。
/**
* 替换指定hash所处位置的链表中的所有节点为TreeNode,
* 如果buckets数组太小,就进行扩容。
*/
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
// MIN_TREEIFY_CAPACITY = 64,小于该值代表数组中的节点并不是很多
// 所以选择进行扩容,只有数组长度大于该值时才会进行树化。
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
// 转换链表节点为树节点,注意要处理好连接关系
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab); // 从头部开始构造树
}
}
// 该函数定义在TreeNode中
final void treeify(Node<K,V>[] tab) {
TreeNode<K,V> root = null;
for (TreeNode<K,V> x = this, next; x != null; x = next) {
next = (TreeNode<K,V>)x.next;
x.left = x.right = null;
if (root == null) { // 初始化root节点
x.parent = null;
x.red = false;
root = x;
}
else {
K k = x.key;
int h = x.hash;
Class<?> kc = null;
for (TreeNode<K,V> p = root;;) {
int dir, ph;
K pk = p.key;
// 确定节点的方向
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
// 如果kc == null
// 并且k没有实现Comparable接口
// 或者k与pk是没有可比较性的(类型不同)
// 或者k与pk是相等的(返回0也有可能是相等)
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0)
dir = tieBreakOrder(k, pk);
// 确定方向后插入节点,修正红黑树的平衡
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
x.parent = xp;
if (dir <= 0)
xp.left = x;
else
xp.right = x;
root = balanceInsertion(root, x);
break;
}
}
}
}
// 确保给定的root是该bucket中的第一个节点
moveRootToFront(tab, root);
}
static int tieBreakOrder(Object a, Object b) {
int d;
if (a == null || b == null ||
(d = a.getClass().getName().
compareTo(b.getClass().getName())) == 0)
// System.identityHashCode()将调用并返回传入对象的默认hashCode()
// 也就是说,无论是否重写了hashCode(),都将调用Object.hashCode()。
// 如果传入的对象是null,那么就返回0
d = (System.identityHashCode(a) <= System.identityHashCode(b) ?
-1 : 1);
return d;
}
解决碰撞冲突的另一种策略叫做开放寻址法(Open addressing),它与分离链接法的思想截然不同。在开放寻址法中,所有Entry都会存储在buckets数组,一个明显的区别是,分离链接法中的每个bucket都是一个链表或其他的数据结构,而开放寻址法中的每个bucket就仅仅只是Entry本身。
开放寻址法是基于数组中的空位来解决冲突的,它的想法很简单,与其使用链表等数据结构,不如直接在数组中留出空位来当做一个标记,反正都要占用额外的内存。
当你查找一个key的时候,首先会从起始位置(通过散列函数计算出的数组索引)开始,不断检查当前bucket是否为目标Entry(通过比较key来判断),如果当前bucket不是目标Entry,那么就向后查找(查找的间隔取决于实现),直到碰见一个空位(null),这代表你想要找的key不存在。
如果你想要put一个全新的Entry(Map中没有这个key存在),依然会从起始位置开始进行查找,如果起始位置不是空的,则代表发生了碰撞冲突,只好不断向后查找,直到发现一个空位。
开放寻址法的名字也是来源于此,一个Entry的位置并不是完全由hash值决定的,所以也叫做Closed hashing,相对的,分离链接法也被称为Open hashing或Closed addressing。
根据向后探测(查找)的算法不同,开放寻址法有多种不同的实现,我们介绍一种最简单的算法:线性探测法(Linear probing),在发生碰撞时,简单地将索引加一,如果到达了数组的尾部就折回到数组的头部,直到找到目标或一个空位。
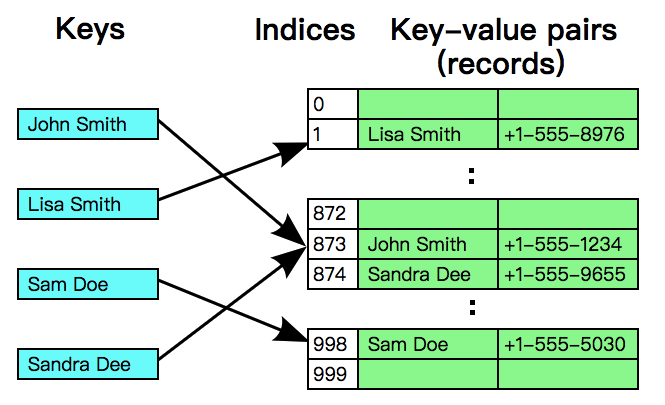
基于线性探测法的查找操作如下:
private K[] keys; // 存储key的数组
private V[] vals; // 存储值的数组
public V get(K key) {
// m是buckets数组的长度,即keys和vals的长度。
// 当i等于m时,取模运算会得0(折回数组头部)
for (int i = hash(key); keys[i] != null; i = (i + 1) % m) {
if (keys[i].equals(key))
return vals[i];
}
return null;
}
插入操作稍微麻烦一些,需要在插入之前判断当前数组的剩余容量,然后决定是否扩容。数组的剩余容量越多,代表Entry之间的间隔越大以及越早碰见空位(向后探测的次数就越少),效率自然就会变高。代价就是额外消耗的内存较多,这也是在用空间换取时间。
public void put(K key, V value) {
// n是Entry的数量,如果n超过了数组长度的一半,就扩容一倍
if (n >= m / 2) resize(2 * m);
int i;
for (i = hash(key); keys[i] != null; i = (i + 1) % m) {
if (keys[i].equals(key)) {
vals[i] = value;
return;
}
}
// 没有找到目标,那么就插入一对新的Entry
keys[i] = key;
vals[i] = value;
n++;
}
接下来是删除操作,需要注意一点,我们不能简单地把目标key所在的位置(keys和vals数组)设置为null,这样会导致此位置之后的Entry无法被探测到,所以需要将目标右侧的所有Entry重新插入到散列表中:
public V delete(K key) {
int i = hash(key);
// 先找到目标的索引
while (!key.equals(keys[i])) {
i = (i + 1) % m;
}
V oldValue = vals[i];
// 删除目标key和value
keys[i] = null;
vals[i] = null;
// 指针移动到下一个索引
i = (i + 1) % m;
while (keys[i] != null) {
// 先删除然后重新插入
K keyToRehash = keys[i];
V valToRehash = vals[i];
keys[i] = null;
vals[i] = null;
n--;
put(keyToRehash, valToRehash);
i = (i + 1) % m;
}
n--;
// 当前Entry小于等于数组长度的八分之一时,进行缩容
if (n > 0 && n <= m / 8) resize(m / 2);
return oldValue;
}
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

