原 荐 Ignite集成Spark之IgniteRDD
本系列共两篇文章,会探讨如何将Ignite和Spark进行集成。
Ignite是一个分布式的内存数据库、缓存和处理平台,为事务型、分析型和流式负载而设计,在保证扩展性的前提下提供了内存级的性能。 Spark是一个流式数据和计算引擎,通常从HDFS或者其他存储中获取数据,一直以来,他都倾向于OLAP型业务,并且聚焦于MapReduce类型负载。
因此,这两种技术是可以互补的。
将Ignite与Spark整合
整合这两种技术会为Spark用户带来若干明显的好处:
- 通过避免大量的数据移动,获得真正可扩展的内存级性能;
- 提高RDD、DataFrame和SQL的性能;
- 在Spark作业之间更方便地共享状态和数据。
下图中显示了如何整合这两种技术,并且标注了显著的优势: 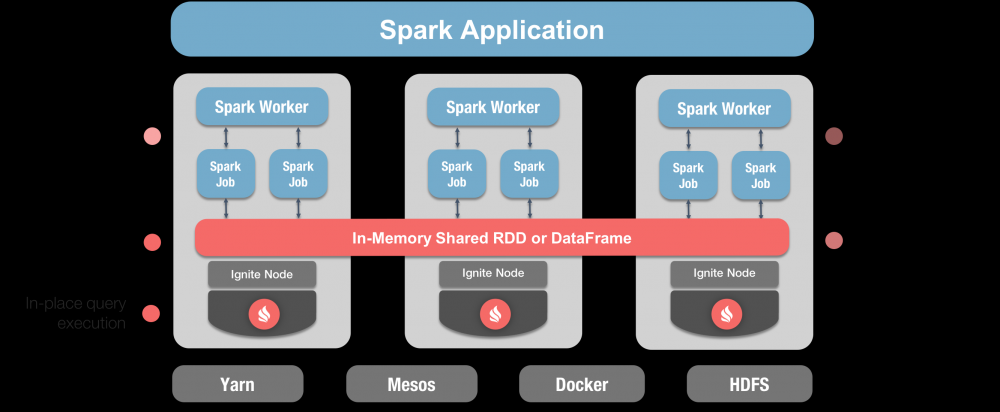 在本系列的第一篇文章中会聚焦于Ignite RDD,在第二篇文章中会聚焦于Ignite DataFrame。
在本系列的第一篇文章中会聚焦于Ignite RDD,在第二篇文章中会聚焦于Ignite DataFrame。
Ignite RDD
Ignite提供了一个SparkRDD的实现,叫做IgniteRDD,这个实现可以在内存中跨Spark作业共享任何数据和状态,IgniteRDD为Ignite中相同的内存数据提供了一个共享的、可变的视图,它可以跨多个不同的Spark作业、工作节点或者应用,相反,原生的SparkRDD无法在Spark作业或者应用之间进行共享。
IgniteRDD作为Ignite分布式缓存的视图,既可以在Spark作业执行进程中部署,也可以在Spark工作节点中部署,也可以在它自己的集群中部署。因此,根据预配置的部署模型,状态共享既可以只存在于一个Spark应用的生命周期的内部(嵌入式模式),或者也可以存在于Spark应用的外部(独立模式)。
Ignite还可以帮助Spark用户提高SQL的性能,虽然SparkSQL支持丰富的SQL语法,但是它没有实现索引。从结果上来说,即使在普通的较小的数据集上,Spark查询也可能花费几分钟的时间,因为需要进行全表扫描。如果使用Ignite,Spark用户可以配置主索引和二级索引,这样可以带来上千倍的性能提升。
IgniteRDD示例
下面通过一些代码以及创建若干应用的方式,演示如何使用IgniteRDD以及看到它的好处,代码的完整版本,可以从 GitHub 上进行下载。
代码共包括两个简单的Scala应用和两个Java应用。这是为了说明可以使用多种语言来访问Ignite RDD,这在使用不同编程语言和框架的组织中可能存在这样的场景。此外,会从两个不同的环境运行应用:从终端运行Scala应用以及通过IDE运行Java应用。作为一个花絮,还会在Java应用程序中运行一些SQL代码。
对于Scala应用,一个应用会用于往IgniteRDD中写入部分数据,而另一个应用会执行部分过滤然后结果集。使用Maven将代码构建为一个jar文件后在终端窗口中执行这个程序,下面是详细的代码:
object RDDWriter extends App {
val conf = new SparkConf().setAppName("RDDWriter")
val sc = new SparkContext(conf)
val ic = new IgniteContext(sc, "/path_to_ignite_home/examples/config/spark/example-shared-rdd.xml")
val sharedRDD: IgniteRDD[Int, Int] = ic.fromCache("sharedRDD")
sharedRDD.savePairs(sc.parallelize(1 to 1000, 10).map(i => (i, i)))
ic.close(true)
sc.stop()
}
object RDDReader extends App {
val conf = new SparkConf().setAppName("RDDReader")
val sc = new SparkContext(conf)
val ic = new IgniteContext(sc, "/path_to_ignite_home/examples/config/spark/example-shared-rdd.xml")
val sharedRDD: IgniteRDD[Int, Int] = ic.fromCache("sharedRDD")
val greaterThanFiveHundred = sharedRDD.filter(_._2 > 500)
println("The count is " + greaterThanFiveHundred.count())
ic.close(true)
sc.stop()
}
在这个Scala的RDDWriter中,首先创建了包含应用名的 SparkConf ,之后基于这个配置创建了 SparkContext ,最后,根据这个 SparkContext 创建一个 IgniteContext 。创建 IgniteContext 有很多种方法,本例中会使用一个叫做 example-shared-rdd.xml 的XML文件,该文件会结合Ignite发行版然后根据需求进行了预配置。显然,需要根据自己的环境修改路径(Ignite主目录),之后指定IgniteRDD持有的整数值元组,最后,将从1到1000的整数值存入IgniteRDD,数值的存储使用了10个parallel操作。
在这个Scala的RDDReader中,初始化和配置与Scala RDDWriter相同,也会使用同一个xml配置文件,应用会执行部分过滤,然后关注存储了多少大于500的值,答案最后会输出出来。
关于 IgniteContext 和 IgniteRDD 的更多信息,可以看Ignite的 文档 。
要构建jar文件,可以使用下面的maven命令:
mvn clean install
接下来,看下Java代码,先写一个Java应用往IgniteRDD中写入多个元组,然后另一个应用会执行部分过滤然后返回结果集,下面是RDDWriter的代码细节:
public class RDDWriter {
public static void main(String args[]) {
SparkConf sparkConf = new SparkConf()
.setAppName("RDDWriter")
.setMaster("local")
.set("spark.executor.instances", "2");
JavaSparkContext sparkContext = new JavaSparkContext(sparkConf);
Logger.getRootLogger().setLevel(Level.OFF);
Logger.getLogger("org.apache.ignite").setLevel(Level.OFF);
JavaIgniteContext<Integer, Integer> igniteContext = new JavaIgniteContext<Integer, Integer>(
sparkContext, "/path_to_ignite_home/examples/config/spark/example-shared-rdd.xml", true);
JavaIgniteRDD<Integer, Integer> sharedRDD = igniteContext.<Integer, Integer>fromCache("sharedRDD");
List<Integer> data = new ArrayList<>(20);
for (int i = 1001; i <= 1020; i++) {
data.add(i);
}
JavaRDD<Integer> javaRDD = sparkContext.<Integer>parallelize(data);
sharedRDD.savePairs(javaRDD.<Integer, Integer>mapToPair(new PairFunction<Integer, Integer, Integer>() {
public Tuple2<Integer, Integer> call(Integer val) throws Exception {
return new Tuple2<Integer, Integer>(val, val);
}
}));
igniteContext.close(true);
sparkContext.close();
}
}
在这个Java的RDDWriter中,首先创建了包含应用名和执行器数量的 SparkConf ,之后基于这个配置创建了 SparkContext ,最后,根据这个 SparkContext 创建一个 IgniteContext 。创建 IgniteContext 有很多种方法,本例中会使用一个叫做 example-shared-rdd.xml 的XML文件,该文件会结合Ignite发行版然后根据需求进行了预配置。显然,需要根据自己的环境修改路径(Ignite主目录),最后,往IgniteRDD中添加了额外的20个值。
在这个Java的RDDReader中,初始化和配置与Java RDDWriter相同,也会使用同一个xml配置文件,应用会执行部分过滤,然后关注存储了多少大于500的值,答案最后会输出出来,下面是Java RDDReader的代码:
public class RDDReader {
public static void main(String args[]) {
SparkConf sparkConf = new SparkConf()
.setAppName("RDDReader")
.setMaster("local")
.set("spark.executor.instances", "2");
JavaSparkContext sparkContext = new JavaSparkContext(sparkConf);
Logger.getRootLogger().setLevel(Level.OFF);
Logger.getLogger("org.apache.ignite").setLevel(Level.OFF);
JavaIgniteContext<Integer, Integer> igniteContext = new JavaIgniteContext<Integer, Integer>(
sparkContext, "/path_to_ignite_home/examples/config/spark/example-shared-rdd.xml", true);
JavaIgniteRDD<Integer, Integer> sharedRDD = igniteContext.<Integer, Integer>fromCache("sharedRDD");
JavaPairRDD<Integer, Integer> greaterThanFiveHundred =
sharedRDD.filter(new Function<Tuple2<Integer, Integer>, Boolean>() {
public Boolean call(Tuple2<Integer, Integer> tuple) throws Exception {
return tuple._2() > 500;
}
});
System.out.println("The count is " + greaterThanFiveHundred.count());
System.out.println(">>> Executing SQL query over Ignite Shared RDD...");
Dataset df = sharedRDD.sql("select _val from Integer where _val > 10 and _val < 100 limit 10");
df.show();
igniteContext.close(true);
sparkContext.close();
}
}
最后,马上就可以对代码进行测试了。
运行这个应用
在第一个终端窗口中,启动Spark的主节点,如下:
$SPARK_HOME/sbin/start-master.sh
在第二个终端窗口中,启动Spark工作节点,如下:
$SPARK_HOME/bin/spark-class org.apache.spark.deploy.worker.Worker spark://ip:port
根据自己的环境,修改IP地址和端口号(ip:port)。
在第三个终端窗口中,启动一个Ignite节点,如下:
$IGNITE_HOME/bin/ignite.sh examples/config/spark/example-shared-rdd.xml
这里使用了之前讨论过的 example-shared-rdd.xml 文件。
在第四个终端窗口中,可以运行Scala版的RDDWriter应用,如下:
$SPARK_HOME/bin/spark-submit --class "com.gridgain.RDDWriter" --master spark://ip:port "/path_to_jar_file/ignite-spark-scala-1.0.jar"
根据自己的环境修改IP地址和端口(ip:port),以及jar文件的路径(/path_to_jar_file)。
会产生如下的输出:
The count is 500
这是我们期望的值。
接下来,杀掉Spark的主节点和工作节点,而Ignite节点仍然在运行中并且IgniteRDD对于其他应用仍然可用,下面会使用IDE通过Java应用接入IgniteRDD。
运行Java版RDDWriter会扩展之前存储于IgniteRDD中的元组列表,通过运行Java版RDDReader可以进行测试,它会产生如下的输出:
The count is 520
这也是我们期望的。
最后,SQL查询会在IgniteRDD中执行一个SELECT语句,返回范围在10到100之间的最初10个值,输出如下:
+----+ |_VAL| +----+ | 11| | 12| | 13| | 14| | 15| | 16| | 17| | 18| | 19| | 20| +----+
结果正确。
总结
本文中,看到了如何从多个环境中使用多个编程语言轻松地访问IgniteRDD。可以对IgniteRDD进行数据的读写,并且即使Spark已经关闭状态也通过Ignite得以保持,因此可以看到,这为Spark用户带来了很大的灵活性和好处。
在本系列的下一篇文章中,会看到Ignite和Spark整合之后的Ignite DataFrames及其优势。
正文到此结束
热门推荐










相关文章

近期评论
-
不会英语啊。
-
前100名用户会展示特殊的纪念徽章
-
-
https://pplx.ai/floraliu4199466 这个链接打不开是什么原因?
-
-
-
-
来看看,最近更新了一波,顺着友联过来的,几年过去了,网站越搞越好,厉害
-
哥太牛了
-
是呀,看您的IP显示在美国,还以为您移民了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

