HDBS之应用代码优化
一、目录结构树
- 总体概述
- 代码检测工具sonar
- HDBS代码优化
- 总结开发注意点
二、总体概述
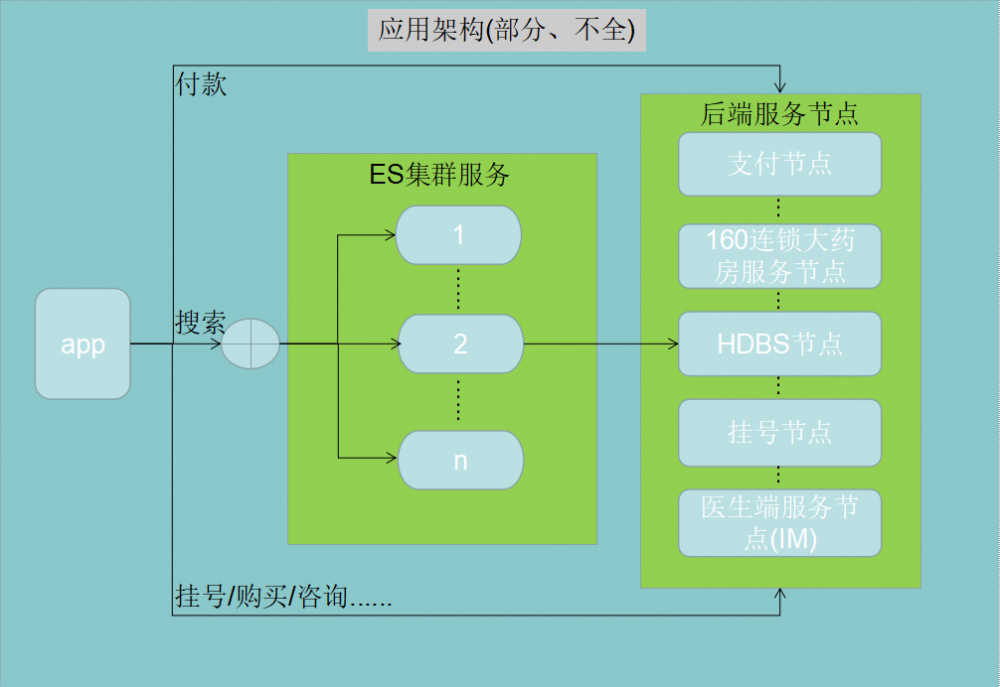
进入现在这家公司我的第一个任务就是对HDBS进行代码质量优化。HDBS可能大家不是很了解,现在给大家简单介绍下:HDBS是HadoopBaseService的简称,Hadoop有了解过大数据的朋友相信并不陌生,BaseService自然也就是基础服务的意思;所以HDBS这个服务主要是基础服务的配置,同时Hadoop则表示数据量的大。以下是我暂时了解的应用架构图方便各位理解,毕竟才来这个公司一个星期可能画的不是很完整不过总体就是这么回事:
二、代码检测工具
-
前提描述
这篇文章侧重讲HDBS代码存在的质量问题,至于怎么用、怎么搭建sonar代码异常检测平台后续再讲。
-
SonarQube简介
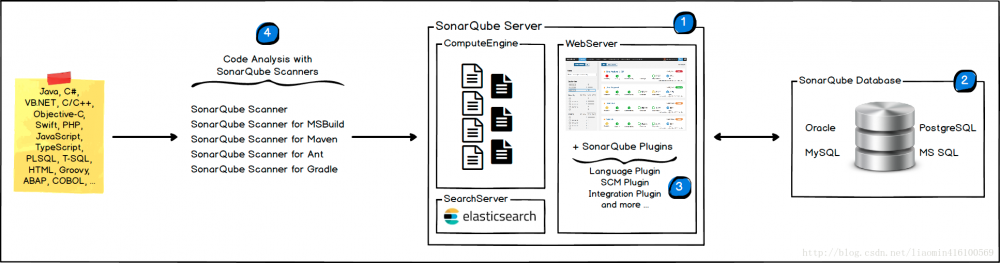
SonarQube系统是一个代码质量检测工具,主要用于检测代码的编写质量,比如:覆盖率、是否包含空指针异常、异常是否正确处理、map的遍历优化、是否包含无用代码块占据cpu资源等。 由以下四个组件组成(https://docs.sonarqube.org/display/SONAR/Architecture+and+Integration)
- 一个sonarqube服务器 包含三个子进程(web服务(界面管理),搜索服务 计算引擎服务(写入数据库))
- 一个sonarqube数据库 配置sonarqube服务
- 多个sonarqube插件 位于解压目录 extensions/plugins目录
- 一个或者多个sonarqube scanners 用于分析特定的项目
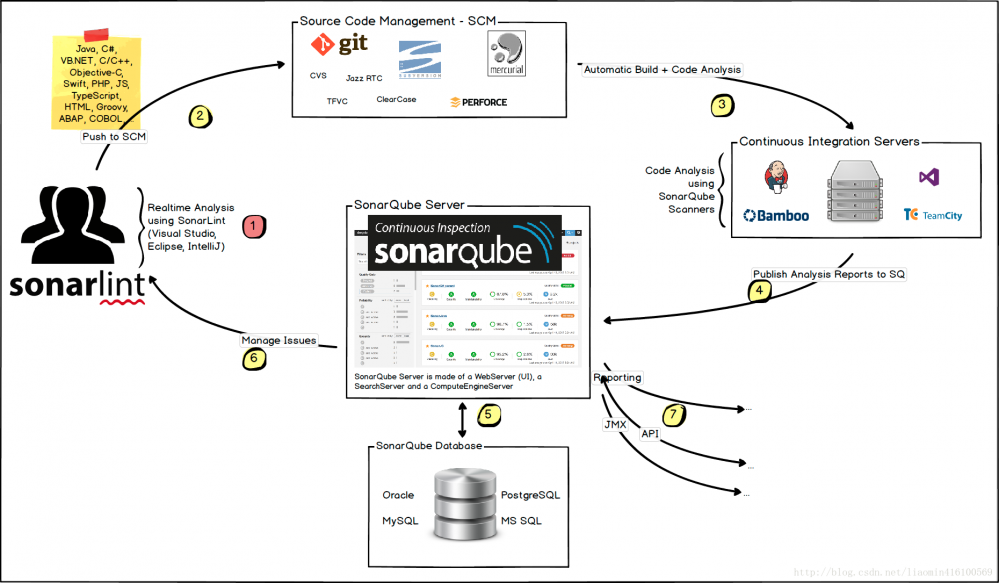
- 使用SonarQube(简称SQ)工作流程
开发者使用开发工具(eclipse,ide)上传代码到SCM(源代码管理器) 系统自动同步代码到某个位置 sonarqube scanners 扫描该代码检查质量 将分析结果 将分析结果推送到SQServer 存储在SQ数据库 用户可以使用eclipse插件sonarlint来同步sonarqube服务器配置(java和js版本等)可以实时在线分析。
三、HDBS代码优化
- 代码优化的重要性
通过sonar代码检测平台针对性地解决代码中相关问题。在大项目中代码质量尤为重要,虽然这些代码问题并不是错误,在正常的数据情况下是不会发生问题的,但是也有很多情况是数据不正常的时候;一个小小的bug可能导致成千上万的订单作废,性能的优化也很重要因为性能的优化可以使得QPS显著上升,代码问题最为严重的就可能导致整个实例挂掉(JVM异常退出)。所以代码质量的提升是重中之重。
- 如何优化
由于HDBS是经由不同的开发人员之手总体代码质量参差不其,虽然公司有一套开发手册但是执行起来似乎比较难;但是事实告诉我们:开发中要尽可能第按照公司开发手册,如果没有就要按照通用的开发规范进行开发,比如遵循阿里的开发规范,毕竟大公司走过的路躺过的坑还是比较多的我们要学会站在巨人的肩膀上往上爬。作为程序员开发效率其实是第一位,在实际开发中我们要学会使用工具来取得开发的最大效率,比如:这里我们采用sonar来管理代码质量问题、可以用SourceTree来管理git代码等;合理使用对应的工具可以达到开发效率的最大化,毕竟公司要的是一个能够有产出的人,如果你一天能够解决的问题而别人需要两天那么你就能得到上司的赏识。
四、总结开发注意点
- HDBS代码中发现的问题(部分)
- 异常没有正确处理。比如:直接在代码中使用e.printStackTrace代码打印异常;这是有一个问题就是:这些代码在本地启动遇到异常后是可以正常打印异常信息,但是当应用部署到Linux服务器的时候却可能不会打印,这如果在线上生产环境发生问题需要盘查的时候就尴尬了,因为你可能根本找不到异常的信息也就是说系统压根就没有记录任何异常信息。
解决方法 :LOGGER.error("xx异常:{}",e) - 可能发生NullPointerException。比如:前面的代码定义了 Map<Object,Object> map=null; 但后面在没有判断obj是否为null的情况下进行map.size()的操作;这也是我们需要注意的地方,这种代码逻辑一般我们是不会进行异常处理的,异常处理要遵循:能够不需要异常处理就不要用异常处理不能把异常处理当做工具来使用。这种情况下如果没判断为null就进行操作就会发生运行时异常当前线程就会意外终止。
解决方法 :先判断是否为null - Map的遍历方式优化。在开发中我见过很多人是这样遍历Map的:先得到keySet()视图,然后遍历keys,通过get(key)的方式来获取对应的value。这种遍历性能其实是很差的,因为我们在遍历keys的时候需要花费一定的时间,在get(key)的时候又会花费一定的时间;我们都知道Map的get()是要计算hashCode然后通过hashCode计算数组的下标,如果有hash冲突又会遍历链表,这种遍历方式显然是低效的,cpu资源是宝贵的这种方式会严重占用cpu并且时间花费的要长得多。
解决方法 :通过entrySet()获取key、value视图,一次遍历就可以获取对应的value,而不需要通过get();不过你也可以用迭代遍历,这都是可以的。 - 日志打印不规范。比如:LOGGER.info(“请求参数:”+params.toString); 日志是盘查问题的关键信息,所以在一个系统中无处不在,一个线程可能产生的log数量就是成百上千行,如果每条日志都这么打印的话会严重影响整个应用的性能。因为字符串拼接的性能是很差的,相信我们都对String不陌生,像这种String c=a+b的方式性能有多好自己也清楚。
解决方法 :LOGGER.info(“请求参数:{}”,params.toString) - 没有考虑线程安全问题。如:在多线程系统应用HashMap;线程安全的概念简单来讲就是:同一个代码块在单线程和多线程的执行情况下的结果是一样的,否则线程非安全。如果在多线程系统应用了HashMap可能导致多个线程之间数据混淆或者是严重占用系统资源,占用系统资源即为发生了循环链表的问题,具体为什么产生循环链表这里就不多加阐述了;同时String、StringBuffer、StringBuilder也类似。
解决方法 :用HashTable或者ConCurrentHashMap替换HashMap - 无效代码。比如:Date date=new Date(),在判断date是否是空的时候用if( date!=null && !"".equal(date));我们都知道date是Date类型永远也不可能是String类型,但是在写代码的时候我们却又一个习惯喜欢加上"".equal(date)来判断,当然这么写是不会有错的,虽然Date不是Strng但是由于 is-a的原则他们的父类都是Object,而equal是Object的方法所以那样判断自然也没有错。这里讲的不单单是Date这个类型,如果是非String类型都这样;还有就是当我们使用List<String> list=new ArrayList<>的方式的时候,后续用list这个对象的时候不需要判断是否为null,因为new出来的对象在没有被JVM回收之前引用的对象永远是非null。
解决方法 :去除无效代码 - 合理使用同步锁。比如:全局定义了一个private static final DateFormat df=new SimpleDateFormat(“yyyy-MM-dd HH:MM:ss”)变量; 在该类中使用到df对象的时候都应用了同步锁;如果在线程并大量大的时候同步锁会严重占用系统资源的开销,因为获得锁与释放锁的过程都是需要占用资源的同时也会带来并发量的下降,所以在能不用同步锁解决问题的时候尽可能不使用锁,万不得已的时候就可以使用。
解决方法 :去除同步锁,在方法中定义局部变量:DateFormat df=new SimpleDateFormat(“yyyy-MM-dd HH:MM:ss”)
Linux公社的RSS地址: https://www.linuxidc.com/rssFeed.aspx
本文永久更新链接地址: https://www.linuxidc.com/Linux/2018-09/154206.htm
正文到此结束
- 本文标签: db 数据库 数据 遍历 开发 ACE id 覆盖率 tab 开发者 程序员 解决方法 http 应用架构 QPS Hadoop js UI 时间 参数 src IO JVM 服务器 https 配置 代码 插件 build plugin ArrayList web git map 多线程 list 同步 ORM ConcurrentHashMap ip 安全 管理 value 总结 Service HashTable java 质量 进程 大数据 key final 文章 HashMap 目录 eclipse 线程 IDE 实例 锁 Architect bug 并发 linux
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

