不学无数 — Java 中 IO 和 NIO
I/O 问题是任何编程语言都无法回避的问题,可以说 I/O 问题是整个人机交互的核心问题,因为 I/O 是机器获取和交换信息的主要渠道。在当今这个数据大爆炸时代,I/O 问题尤其突出,很容易成为一个性能瓶颈。
什么是I/O
I/O ? 或者输入/输出 ? 指的是计算机与外部世界或者一个程序与计算机的其余部分的之间的接口。它对于任何计算机系统都非常关键,因而所有 I/O 的主体实际上是内置在操作系统中的。单独的程序一般是让系统为它们完成大部分的工作。
-
I:就是从 硬盘 将内容读取到 内存 中 -
O:就是从 内存 将内容读取到 硬盘 中
Java中的I/O操作类在包 java.io 下面,大概将近有80多个类,但是这些类可以分为三组
- 基于字节操作的I/O接口:
InputStream和OutputStream - 基于字符操作的 I/O 接口:
Writer和Reader - 基于磁盘操作的 I/O 接口:
File
然后在各个接口下还有其各自的包装类,其运用到了装饰模式,为其增加一些功能,而Java的I/O复杂也在这,不同的装饰模式创建类的代码也不同。
基于字节操作
InputStream 的作用是用来表示那些从不同数据源产生输入的类,这些数据源包括
- 字节数组
- String对象
- 文件
- 管道,工作方式和实际中的管道相同,从一端输入,从另一端输出
- 其他的数据源,例如
Internet中的Socket连接
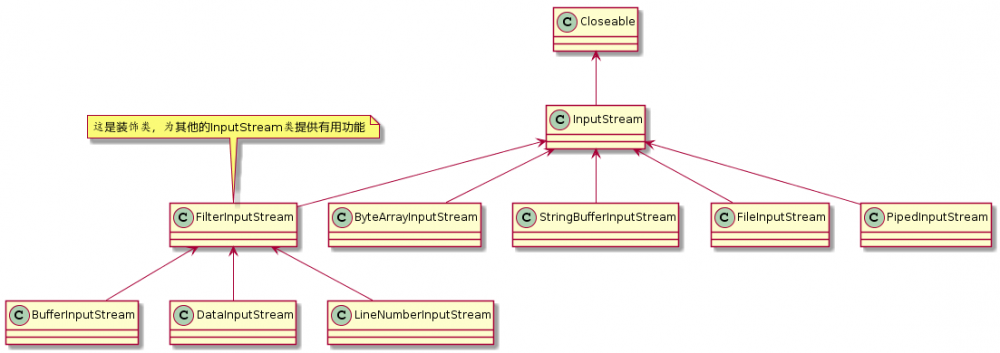
InputStream 的类图, OutputStream 类图和这个类似
| 类 | 功能 | 构造器参数 | 如何使用 |
|---|---|---|---|
ByteArrayInputStream |
允许将内存的缓冲区当做 InputStream 使用 |
缓冲区,字节将其从中取出 | 作为数据源:将其与 FilterInputStream 对象相连以提供有用的接口 |
StringBufferInputStream |
将String转换成 InputStream |
字符串,底层实现实际使用 StringBuffer |
作为数据源:将其与 FilterInputStream 对象相连提供有用接口 |
FileInputStream |
用于从文件中读取信息 | 字符串,表示文件名,文件或者 FileDescriptor 对象 |
作为一种数据源,将其与 FilterInputStream 对象相连提供有用接口 |
PipedInputStream |
产生用于写入相关 PipedOutputStream 的额数据,实现管道化的概念 |
PipedOutputStream |
作为多线程的数据源:将其与 FilterInputStream 对象相连提供有用接口 |
FilterInputStream |
抽象类,作为装饰器的接口,为其他的 InputStream 提供有用的功能 |
使用过滤器添加有用的属性和有用的接口
Java的I/O类库需要多种不同功能的组合,这正是装饰模式的理由所在。而这也是java的I/O类库中存在Filter(过滤器)类的原因所在,Filter作为所有装饰类的基类。
| 类 | 功能 |
|---|---|
BufferedInputStream |
使用它可以防止每次读取都进行与磁盘的交互,使用缓冲区进行一次性读取固定值的以后再向磁盘中执行写操作,减少了与磁盘的交互次数。提高速度 |
DataInputStream |
允许应用程序以与机器无关方式从底层输入流中读取基本 Java 数据类型 |
举个简单使用过滤器进行读取一个文件的内容并输出,例子如下:
public static void main(String[] args) throws IOException {
InputStream inputStream = new BufferedInputStream(new FileInputStream("/Users/hupengfei/Downloads/a.sql"));
byte[] buffer = new byte[1024];
while ( inputStream.read(buffer)!=-1){
System.out.println(new String(buffer));
}
inputStream.close();
}
复制代码
复制一个文件的例子:
public static void main(String[] args) throws IOException {
InputStream inputStream =new BufferedInputStream(new FileInputStream("/Users/hupengfei/Downloads/leijicheng.png"));
OutputStream outputStream =new BufferedOutputStream(new FileOutputStream("/Users/hupengfei/Downloads/fuzhi.png"));
byte [] buffer = new byte[1024];
while (inputStream.read(buffer)!=-1){
outputStream.write(buffer);
}
outputStream.flush();
inputStream.close();
outputStream.close();
}
复制代码
如果要使用 BufferedOutputStream 进行在文件中写入的话,那么在缓冲区写完之后要记得调用 flush() 清空缓冲区。强行将缓冲区中的数据写出。否则可能无法写出数据。
基于字符的操作
不管是磁盘还是网络传输,最小的存储单元都是字节,而不是字符,所以 I/O 操作的都是字节而不是字符,但是为啥有操作字符的 I/O 接口呢?这是因为我们的程序中通常操作的数据都是以字符形式,为了操作方便当然要提供一个直接写字符的 I/O 接口。
还是老规矩,我们先来看一下关于 Reader 的类图,对应的字节流是 InputStream
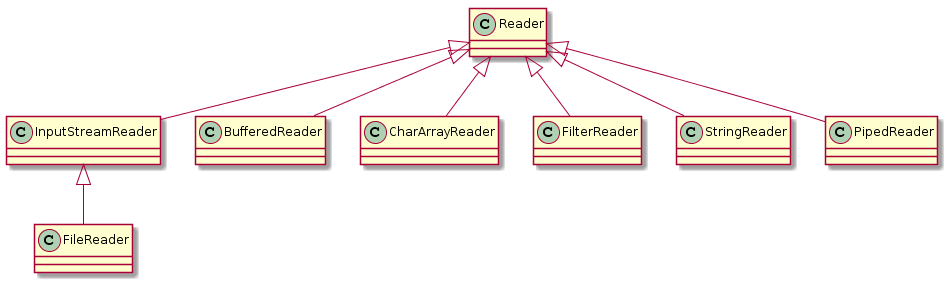
其中的 InputStreamReader 是可以将 InputStream 转换为 Reader 即将字节翻译为字符。其中为什么要设计 Reader 和 Writer ,主要是为了国际化,之前的字节流仅仅支持8位的字节流,不能很好的处理16位的Unicode字符,由于Unicode用于字符国际化,所以添加了 Reader 和 Writer 是为了在所有的I/O操作中都支持Unicode。
在某些场合,面向字节流 InputStream 和 OutputStream 才是正确的解决方案,特别是在 java.util.zip 类库就是面向字节流而不是面向字符的。因此,最明智的做法就是尽量优先使用 Reader 和 Writer ,一旦程序无法编译,那么我们就会发现自己不得不使用面向字节类库。
还是写一个相关的读取文件的简单例子
public static void main(String[] args) throws IOException {
BufferedReader bufferedReader = new BufferedReader(new FileReader("/Users/hupengfei/Downloads/a.sql"));
String date;
StringBuilder stringBuilder = new StringBuilder();
while ((date = bufferedReader.readLine()) != null){
stringBuilder.append(date +"/n");
}
bufferedReader.close();
System.out.println(stringBuilder.toString());
}
复制代码
调用 readLine() 方法时要添加换行符,因为 readLine() 自动将换行符给删除了
NIO又是什么
在 JDK1.4 中添加了NIO类,我们也可以称之为新I/O。NIO 的创建目的是为了让 Java 程序员可以实现高速 I/O 而无需编写自定义的本机代码。NIO 将最耗时的 I/O 操作(即填充和提取缓冲区)转移回操作系统,因而可以极大地提高速度。
速度的提高来自于所使用的结构更接近于操作系统执行I/O的方式:通道(Channel)和缓冲器(Buffer)
通道和缓冲器是NIO中的核心对象,几乎每一个I/O操作中都会使用它们。通道是对原I/O包中的流的模拟。到任何地方(来自任何地方)的数据都得必须通过一个Channel对象。一个Buffer实质上是一个容器对象。发送给一个通道的所有对象都必须首先放到Buffer缓冲器中。
我们可以将它们想象成一个煤矿,通道就是一个包含煤矿(数据)的矿藏,而缓冲器就是派送到矿藏中的矿车,矿车载满煤炭而归,我们再从矿车上获取煤炭。也就是说,我们并没有直接和通道交互,我们只是和缓冲器进行交互。
缓冲器(Buffer)介绍
Buffer是一个对象,它包含着一些需要读取的数据或者是要传输的数据。在NIO中加入了Buffer对象,体现了和之前的I/O的一个重要的区别。在面向流的I/O中我们直接通过流对象直接和数据进行交互的,但是在NIO中我们和数据的交互必须通过Buffer了。
缓冲器实质上是一个数组。通常它是一个字节的数组,但是也可以使用其他种类的数组。但是一个缓冲器不仅仅是一个数组,缓冲器提供了对数据结构化的访问,而且还可以跟踪系统的读写进程。
接下来我们可以看一下 Buffer 相关的实现类

每一个 Buffer 类都是 Buffer 接口的一个实例。 除了 ByteBuffer ,每一个 Buffer 类都有完全一样的操作,只是它们所处理的数据类型不一样。因为大多数标准 I/O 操作都使用 ByteBuffer ,所以它具有所有共享的缓冲区操作以及一些特有的操作。
ByteBuffer 是唯一一个直接与通道交互的缓冲器——也就说,可以存储未加工字节的缓冲器。当我们查看 ByteBuffer 源码时会发现其通过告知分配多少存储空间来创建一个 ByteBuffer 对象,并且还有一个方法选择集,用于以原始的字节形式或者基本数据类型输出和读取数据。但是,也没办法输出或者读取对象,即是是字符串的对象也不行。这种处理方式虽然很低级,但是正好,因为这是大多数操作系统中更有效的映射方式。
通道(Channel)介绍
Channel 是一个对象,缓冲器可以通过它进行读取和写入数据。和原来的I/O做个比较,通道就像个流。正如前面所提到的, Channel 是不和数据进行交互。但是它和流有一点不同,就是通道是双向的,而流只能是单向的(只能是InputStream或者OutputStream),但是通道可以用于读、写或者是同时用于读写。
在之前的I/O中有三个类被修改,可以用来产生 FileChannel 对象。这三个类是 FileInputStream 、 FileOutputStream 以及既用于读也用于写的 RandomAccessFile 。
下面就举个创建 FileChannel 的例子。
FileChannel in = new FileInputStream("fileName").getChannel();
复制代码
NIO的使用
我会举一个简单的例子来演示如何使用NIO对文件进行复制的操作。还是上面所说的,NIO中对数据操作的是缓冲器,和缓冲器交互的通道,所以现在需要我们有两个对象一个是 Buffer 和 Channel 。
public static void main(String[] args) throws IOException {
//获取读通道
FileChannel in = new FileInputStream("/Users/hupengfei/Downloads/hu.sql").getChannel();
//获取写通道
FileChannel out = new FileOutputStream("/Users/hupengfei/Downloads/a.sql").getChannel();
//为缓冲器进行初始化大小
ByteBuffer byteBuffer =ByteBuffer.allocate(1024);
while (in.read(byteBuffer)!=-1){
//做好让人读的准备
byteBuffer.flip();
out.write(byteBuffer);
//清除数据
byteBuffer.clear();
}
}
复制代码
一旦要用从缓冲器中读取数据的话,那么就要调用缓冲器的 flip() 方法,让它做好让别人读取字节的准备。那么写完数据以后就要调用缓存器的 clear() 方法对所有的内部的指针重新安排,以便缓冲器在另一个 read() 操作期间能够做好接受数据的准备。然后数据就会从源文件中源源不断的读到了目标文件中。
clear() 方法在源码中有介绍,此方法不会实际的清除在缓冲器的数据。
当然上面的方法也可以简便,直接将两个通道进行相连只需要调用 transferTo() 方法,这个也是复制文件的效果。
public static void main(String[] args) throws IOException {
FileChannel in = new FileInputStream("/Users/hupengfei/Downloads/hu.sql").getChannel();
FileChannel out = new FileOutputStream("/Users/hupengfei/Downloads/a.sql").getChannel();
in.transferTo(0,in.size(),out);
}
复制代码
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

