HashMap为何从头插入改为尾插入
微信公众号:如有问题或建议,请在下方留言;
最近更新:2018-09-21
前言
前面对于HashMap在jdk1.8中元素插入的实现原理,进行了详细分析,具体请看:HashMap之元素插入。文章发布之后,有一位朋友问了这么一个问题:"jdk1.7中采用头插入,为什么jdk1.8中改成了尾插入?"。有人说这就是java大神随性而为,没什么特殊的用处。当时因为没仔细看过1.7的源码,所以不好解答。现在特此写了本文,来对该问题进行详细的分析。
静态常量
源码:
1/**
2 * 默认初始大小,值为16,要求必须为2的幂
3 */
4static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
5
6/**
7 * 最大容量,必须不大于2^30
8 */
9static final int MAXIMUM_CAPACITY = 1 << 30;
10
11/**
12 * 默认加载因子,值为0.75
13 */
14static final float DEFAULT_LOAD_FACTOR = 0.75f;
15
16/**
17 * HashMap的空数组
18 */
19static final Entry<?,?>[] EMPTY_TABLE = {};
20
21/**
22 * 可选的默认哈希阈值
23 */
24static final int ALTERNATIVE_HASHING_THRESHOLD_DEFAULT = Integer.MAX_VALUE;
复制代码
注意: jdk1.7中HashMap默认采用数组+单链表方式存储元素,当元素出现哈希冲突时,会存储到该位置的单链表中。这和1.8不同,除了数组和单链表外,当单链表中元素个数超过8个时,会进而转化为红黑树存储,巧妙地将遍历元素时时间复杂度从O(n)降低到了O(logn))。
构造函数
1、无参构造函数:
1public HashMap() {
2 this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
3}
复制代码
2、带参构造函数,指定初始容量:
1public HashMap(int initialCapacity) {
2 this(initialCapacity, DEFAULT_LOAD_FACTOR);
3}
复制代码
3、带参构造函数,指定初始容量和加载因子:
1public HashMap(int initialCapacity, float loadFactor) {
2 if (initialCapacity < 0)
3 throw new IllegalArgumentException("Illegal initial capacity: " +
4 initialCapacity);
5 if (initialCapacity > MAXIMUM_CAPACITY)
6 initialCapacity = MAXIMUM_CAPACITY;
7 if (loadFactor <= 0 || Float.isNaN(loadFactor))
8 throw new IllegalArgumentException("Illegal load factor: " +
9 loadFactor);
10
11 this.loadFactor = loadFactor;
12 threshold = initialCapacity;//和jdk8不同,初始阈值就是初始容量,并没做2次幂处理
13 init();
14}
复制代码
4、带参构造函数,指定Map集合:
1public void putAll(Map<? extends K, ? extends V> m) {
2 int numKeysToBeAdded = m.size();
3 if (numKeysToBeAdded == 0)
4 return;
5
6 if (table == EMPTY_TABLE) {
7 inflateTable((int) Math.max(numKeysToBeAdded * loadFactor, threshold));
8 }
9
10 if (numKeysToBeAdded > threshold) {
11 int targetCapacity = (int)(numKeysToBeAdded / loadFactor + 1);
12 if (targetCapacity > MAXIMUM_CAPACITY)
13 targetCapacity = MAXIMUM_CAPACITY;
14 int newCapacity = table.length;
15 while (newCapacity < targetCapacity)
16 newCapacity <<= 1;
17 if (newCapacity > table.length)
18 resize(newCapacity);
19 }
20
21 for (Map.Entry<? extends K, ? extends V> e : m.entrySet())
22 put(e.getKey(), e.getValue());
23 }
复制代码
说明: 执行构造函数时,存储元素的数组并不会进行初始化,而是在第一次放入元素的时候,才会进行初始化操作。创建HashMap对象时,仅仅计算初始容量和新增阈值。
添加元素
1、源码:
1public V put(K key, V value) {
2 if (table == EMPTY_TABLE) {
3 inflateTable(threshold);//初始化数组
4 }
5 if (key == null)//key为null,做key为null的添加
6 return putForNullKey(value);
7 int hash = hash(key);//计算键值的哈希
8 int i = indexFor(hash, table.length);//根据哈希值获取在数组中的索引位置
9 for (Entry<K,V> e = table[i]; e != null; e = e.next) {//遍历索引位置的单链表,判断是否存在指定key
10 Object k;
11 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {//key已存在则更新value值
12 V oldValue = e.value;
13 e.value = value;
14 e.recordAccess(this);
15 return oldValue;
16 }
17 }
18
19 modCount++;
20 addEntry(hash, key, value, i);//key不存在,则插入元素
21 return null;
22}
23
24private V putForNullKey(V value) {
25 for (Entry<K,V> e = table[0]; e != null; e = e.next) {
26 if (e.key == null) {//key为null已存在,更新value值
27 V oldValue = e.value;
28 e.value = value;
29 e.recordAccess(this);
30 return oldValue;
31 }
32 }
33 modCount++;
34 addEntry(0, null, value, 0);//不存在则新增,key为null的哈希值为0
35 return null;
36}
37
38void addEntry(int hash, K key, V value, int bucketIndex) {
39 if ((size >= threshold) && (null != table[bucketIndex])) {//插入位置存在元素,并且元素个数大于等于新增阈值
40 resize(2 * table.length);//进行2倍扩容
41 hash = (null != key) ? hash(key) : 0;//扩容中可能会调整哈希种子的值,所以重新计算哈希值
42 bucketIndex = indexFor(hash, table.length);//重新计算在扩容后数组中的位置
43 }
44
45 createEntry(hash, key, value, bucketIndex);//添加元素
46}
47
48//计算对象哈希值
49final int hash(Object k) {
50 int h = hashSeed;
51 if (0 != h && k instanceof String) {//String采用单独的算法
52 return sun.misc.Hashing.stringHash32((String) k);
53 }
54
55 h ^= k.hashCode();//利用哈希种子异或哈希值,为了进行优化,增加随机性
56
57 h ^= (h >>> 20) ^ (h >>> 12);
58 return h ^ (h >>> 7) ^ (h >>> 4);//这里的移位异或操作属于扰乱函数,都是为了增加哈希值的随机性,降低哈希冲突的概率
59}
60
61void createEntry(int hash, K key, V value, int bucketIndex) {
62 Entry<K,V> e = table[bucketIndex];
63 table[bucketIndex] = new Entry<>(hash, key, value, e);//新增元素插入到数组索引位置,原来元素作为其后继节点,即采用头插入方法
64 size++;
65}
复制代码
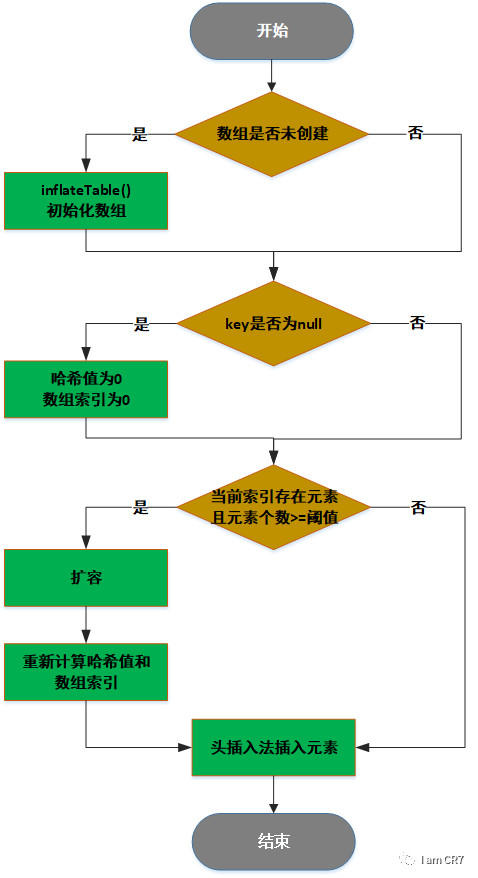
2、流程图:
3、示例:

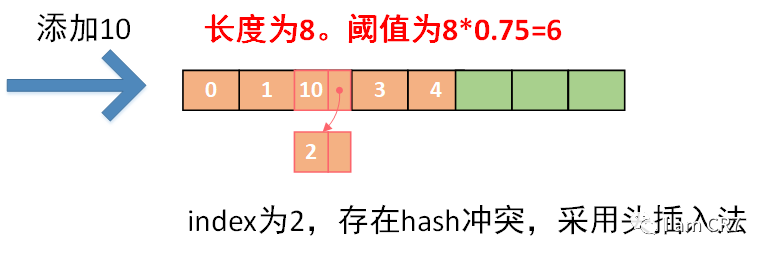
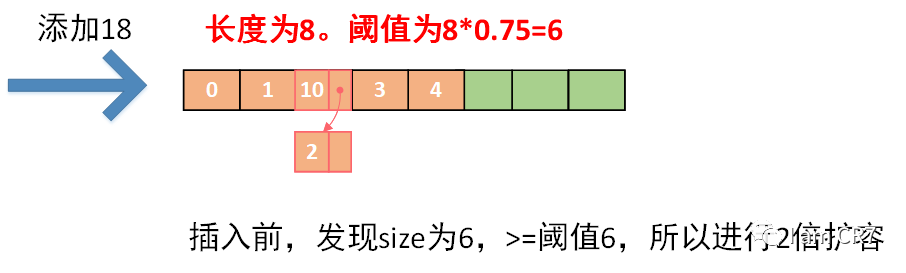


初始化数组
1、源码:
1//根据指定的大小,初始化数组
2private void inflateTable(int toSize) {
3 // Find a power of 2 >= toSize
4 int capacity = roundUpToPowerOf2(toSize);
5
6 threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);//根据容量和加载因子计算阈值,最大为2^30+1
7 table = new Entry[capacity];//创建指定容量大小的数组
8 initHashSeedAsNeeded(capacity);
9}
10
11//获取大于指定值的最小2次幂,最大为2^30
12private static int roundUpToPowerOf2(int number) {
13 // assert number >= 0 : "number must be non-negative";
14 return number >= MAXIMUM_CAPACITY
15 ? MAXIMUM_CAPACITY
16 : (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
17}
复制代码
2、说明:
关于哈希种子,是为了优化哈希函数,让其值更加随机,从而降低哈希冲突的概率。通过HashMap中私有静态类Holder,在JVM启动的时候,指定-Djdk.map.althashing.threshold=值,来设置可选的哈希阈值,从而在initHashSeedAsNeeded中决定是否需要调整哈希种子。
1private static class Holder {
2
3 /**
4 * Table capacity above which to switch to use alternative hashing.
5 */
6 static final int ALTERNATIVE_HASHING_THRESHOLD;
7
8 static {
9 String altThreshold = java.security.AccessController.doPrivileged(
10 new sun.security.action.GetPropertyAction(
11 "jdk.map.althashing.threshold"));//通过-Djdk.map.althashing.threshold=值指定可选哈希阈值
12
13 int threshold;
14 try {
15 threshold = (null != altThreshold)
16 ? Integer.parseInt(altThreshold)
17 : ALTERNATIVE_HASHING_THRESHOLD_DEFAULT;//默认为Integer.MAX_VALUE
18
19 // disable alternative hashing if -1
20 if (threshold == -1) {
21 threshold = Integer.MAX_VALUE;
22 }
23
24 if (threshold < 0) {
25 throw new IllegalArgumentException("value must be positive integer.");
26 }
27 } catch(IllegalArgumentException failed) {
28 throw new Error("Illegal value for 'jdk.map.althashing.threshold'", failed);
29 }
30
31 ALTERNATIVE_HASHING_THRESHOLD = threshold;//指定可选的哈希阈值,在initHashSeedAsNeeded作为是否初始化哈希种子的判定条件
32 }
33}
34
35//根据容量决定是否需要初始化哈希种子
36final boolean initHashSeedAsNeeded(int capacity) {
37 boolean currentAltHashing = hashSeed != 0;//哈希种子默认为0
38 boolean useAltHashing = sun.misc.VM.isBooted() &&
39 (capacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);//如果容量大于可选的哈希阈值,则需要初始化哈希种子
40 boolean switching = currentAltHashing ^ useAltHashing;
41 if (switching) {
42 hashSeed = useAltHashing
43 ? sun.misc.Hashing.randomHashSeed(this)//生成一个随机的哈希种子
44 : 0;
45 }
46 return switching;
47}
复制代码
扩容
1、源码:
1//按照指定容量进行数组扩容
2void resize(int newCapacity) {
3 Entry[] oldTable = table;
4 int oldCapacity = oldTable.length;
5 if (oldCapacity == MAXIMUM_CAPACITY) {//原有容量达到最大值,则不再扩容
6 threshold = Integer.MAX_VALUE;
7 return;
8 }
9
10 Entry[] newTable = new Entry[newCapacity];
11 transfer(newTable, initHashSeedAsNeeded(newCapacity));
12 table = newTable;
13 threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);//按照扩容后容量重新计算阈值
14}
15
16//将元素重新分配到新数组中
17void transfer(Entry[] newTable, boolean rehash) {
18 int newCapacity = newTable.length;
19 for (Entry<K,V> e : table) {//遍历原数组
20 while(null != e) {
21 Entry<K,V> next = e.next;
22 if (rehash) {//扩容后数组需要重新计算哈希
23 e.hash = null == e.key ? 0 : hash(e.key);
24 }
25 int i = indexFor(e.hash, newCapacity);//计算新数组中的位置
26 e.next = newTable[i];//采用头插入法,添加到新数组中
27 newTable[i] = e;
28 e = next;
29 }
30 }
31}
复制代码
2、问题:
上述扩容代码,在并发情况下执行,就会出现常说的链表成环的问题,下面通过示例来分析:
2.1、初始状态:
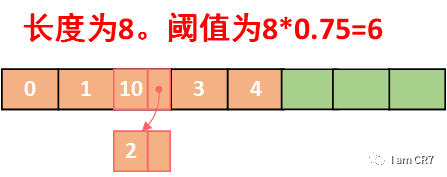
线程1插入18,线程2插入26。此时线程1发现size为6,进行扩容。线程2发现size为6,也进行扩容。
2.2、 线程1执行:
线程1首先获取到CPU执行权,执行transfer()中代码:
1for (Entry<K,V> e : table) {
2 while(null != e) {
3 Entry<K,V> next = e.next;//线程1执行到此行代码,e为10,next为2。此时CPU调度线程2执行。
4 if (rehash) {
5 e.hash = null == e.key ? 0 : hash(e.key);
6 }
7 int i = indexFor(e.hash, newCapacity);
8 e.next = newTable[i];
9 newTable[i] = e;
10 e = next;
11 }
12}
复制代码
2.3、 线程2执行:
线程2此时获取到CPU执行权,执行transfer()中代码:
1for (Entry<K,V> e : table) {
2 while(null != e) {
3 Entry<K,V> next = e.next;
4 if (rehash) {
5 e.hash = null == e.key ? 0 : hash(e.key);
6 }
7 int i = indexFor(e.hash, newCapacity);
8 e.next = newTable[i];
9 newTable[i] = e;
10 e = next;
11 }
12}
复制代码
第一次遍历:e为10,next为2,rehash为false,i为2,newTable[2]为null,10.next为null,newTable[2]为10,e为2。
第二次遍历:e为2,next为null,rehash为false,i为2,newTable[2]为10,2.next为10,newTable[2]为2,e为null。
第三次遍历:e为null,退出循环。

2.4、 线程1执行:
1for (Entry<K,V> e : table) {
2 while(null != e) {
3 Entry<K,V> next = e.next;//线程1执行到此行代码,e为10,next为2。CPU调度线程1继续执行。
4 if (rehash) {
5 e.hash = null == e.key ? 0 : hash(e.key);
6 }
7 int i = indexFor(e.hash, newCapacity);
8 e.next = newTable[i];
9 newTable[i] = e;
10 e = next;
11 }
12}
复制代码
e为10,next为2,rehash为false,i为2,newTable[2]为2,10.next为2,newTable[2]为10,e为2。
第二次遍历:e为2,next为null,rehash为false,i为2,newTable[2]为10,2.next为10,newTable[2]为2,e为10。此时,链表已经成环,进入死循环!!!

3、说明:
由上例可知,HashMap在jdk1.7中采用头插入法,在扩容时会改变链表中元素原本的顺序,以至于在并发场景下导致链表成环的问题。而在jdk1.8中采用尾插入法,在扩容时会保持链表元素原本的顺序,就不会出现链表成环的问题了。
总结
通过上述的分析,在这里总结下HashMap在1.7和1.8之间的变化:
- 1.7采用数组+单链表,1.8在单链表超过一定长度后改成红黑树存储
- 1.7扩容时需要重新计算哈希值和索引位置,1.8并不重新计算哈希值,巧妙地采用和扩容后容量进行&操作来计算新的索引位置。
- 1.7插入元素到单链表中采用头插入法,1.8采用的是尾插入法。
通过对HashMap在jdk1.7和1.8中源码的学习,深深地体会到一个道理:一切设计都有着它背后的原因。作为学习者,我们需要不断的问自己,为什么这么设计,这么设计有什么好处。本着这样的学习态度,我想不久的将来,你就会变成他。
文章的最后,感谢大家的支持,欢迎扫描下方二维码,进行关注。如有任何疑问,欢迎大家留言。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

