java 中的 Executors 简介与多线程在网站上逐步优化的运用案例
提供Executor的工厂类
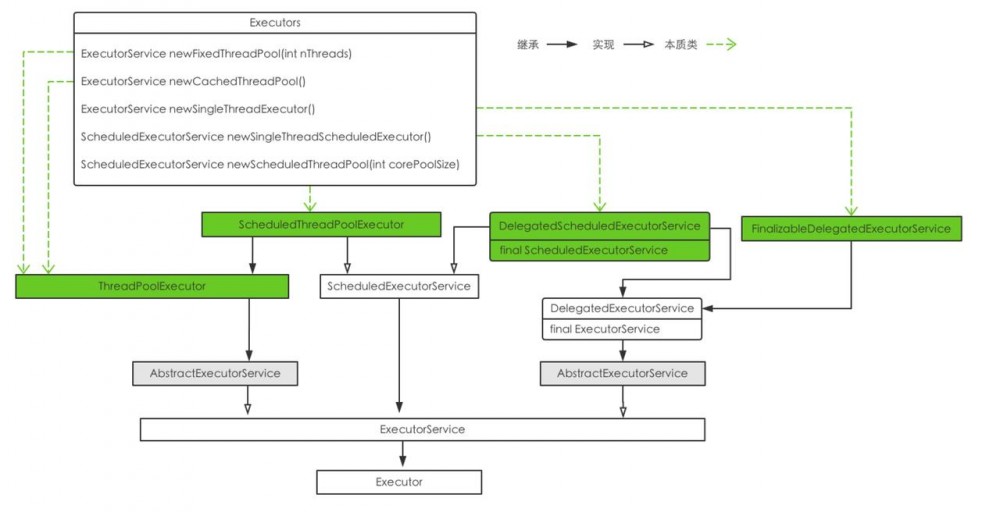
忽略了自定义的ThreadFactory、callable和unconfigurable相关的方法
-
newFixedxxx:在任意时刻,最多有nThreads个线程在处理task;如果所有线程都在运行时来了新的任务,它会被扔入队列;如果有线程在执行期间因某种原因终止了运行,如果需要执行后续任务,新的线程将取代它
return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); 复制代码 -
newCachedxxx:新任务到来如果线程池中有空闲的线程就复用,否则新建一个线程。如果一个线程超过60秒没有使用,它就会被关闭移除线程池
return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); 复制代码 -
newSingleThreadExecutor:仅使用一个线程来处理任务,如果这线程挂了,会产生一个新的线程来代替它。每一个任务被保证按照顺序执行,而且一次只执行一个
public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); } 复制代码使用newFixedxxx方法也能实现类似的作用,但是ThreadPoolExecutor会提供修改线程数的方法,FinalizableDelegatedExecutorService则没有修改的途径,它在DelegatedExecutorService的基础 上仅提供了执行finalize时候去关闭线程,而DelegatedExecutorService仅暴漏ExecutorService自身的方法
-
newScheduledThreadPool:提供一个线程池来延迟或者定期执行任务
public ScheduledThreadPoolExecutor(int corePoolSize) { super(corePoolSize, Integer.MAX_VALUE, 0, TimeUnit.NANOSECONDS, new DelayedWorkQueue()); } 复制代码 -
newSingleThreadScheduledExecutor:提供单个线程来延迟或者定期执行任务,如果执行的线程挂了,会生成新的。
return new DelegatedScheduledExecutorService (new ScheduledThreadPoolExecutor(1)); 复制代码同样,它保证返回的Executor自身的线程数不可修改
从上述的实现可以看出,核心在于三个部分
- ThreadPoolExecutor:提供线程数相关的控制
- DelegatedExecutorService:仅暴露ExecutorService自身的方法,保证线程数不变来实现语义场景
- ScheduledExecutorService:提供延迟或者定期执行的功能
对应的,相应也有不同的队列去实现不同的场景
- LinkedBlockingQueue:无界阻塞队列
- SynchronousQueue:没有消费者消费时,新的任务就会被阻塞
- DelayQueue:队列中的任务过期之后才可以执行,否则无法查询到队列中的元素
DelegatedExecutorService
它仅仅是包装了ExecutorService的方法,交由传入的ExecutorService来执行,所谓的UnConfigurable实际也就是它没有暴漏配置各种参数调整的方法
static class DelegatedExecutorService extends AbstractExecutorService {
private final ExecutorService e;
DelegatedExecutorService(ExecutorService executor) { e = executor; }
public void execute(Runnable command) { e.execute(command); }
public void shutdown() { e.shutdown(); }
public List<Runnable> shutdownNow() { return e.shutdownNow(); }
public boolean isShutdown() { return e.isShutdown(); }
public boolean isTerminated() { return e.isTerminated(); }
public boolean awaitTermination(long timeout, TimeUnit unit)
throws InterruptedException {
return e.awaitTermination(timeout, unit);
}
public Future<?> submit(Runnable task) {
return e.submit(task);
}
public <T> Future<T> submit(Callable<T> task) {
return e.submit(task);
}
public <T> Future<T> submit(Runnable task, T result) {
return e.submit(task, result);
}
public <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks)
throws InterruptedException {
return e.invokeAll(tasks);
}
public <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks,
long timeout, TimeUnit unit)
throws InterruptedException {
return e.invokeAll(tasks, timeout, unit);
}
public <T> T invokeAny(Collection<? extends Callable<T>> tasks)
throws InterruptedException, ExecutionException {
return e.invokeAny(tasks);
}
public <T> T invokeAny(Collection<? extends Callable<T>> tasks,
long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException {
return e.invokeAny(tasks, timeout, unit);
}
}
复制代码
ScheduledExecutorService
提供一系列的schedule方法,使得任务可以延迟或者周期性的执行,对应schedule方法会返回ScheduledFuture以供确认是否执行以及是否要取消。它的实现ScheduledThreadPoolExecutor也支持立即执行由submit提交的任务
仅支持相对延迟时间,比如距离现在5分钟后执行。类似Timer也可以管理延迟任务和周期任务,但是存在一些缺陷:
ScheduledExecutorService的多线程机制可弥补 1:可以使用try-catch-finally对相应执行快处理;2:通过execute执行的方法可以设置UncaughtExceptionHandler来接收未捕获的异常,并作出处理;3:通过submit执行的,将被封装层ExecutionException重新抛出
ThreadPoolExecutor
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
复制代码
- corePoolSize、maximumPoolSize:ThreadPoolExecutor会根据这两自动调整线程池的大小,当一个新任务通过execute提交的时候:
如果当前运行的线程数小于corePoolSize就新建线程;
如果当前线程数在corePoolSize与maximumPoolSize之间,则只有在队列满的时候才会创建新的线程;
如果已经达到最大线程数,并且队列都满了,在这种饱和状态下就会执行拒绝策略默认情况下,只有新任务到达的时候才会启动线程,可通过prestartCoreThread方法实现事先启动
- corePoolSize:默认线程池所需要维护的最小的worker的数量,就算是worker过期了也会保留。如果想要不保留,则需要设置allowCoreThreadTimeOut,此时最小的就是0
- maximumPoolSize:线程池最大的线程数。java限制最多为 2^29-1,大约5亿个
- keepAliveTime、unit:如果当前线程池有超过corePoolSize的线程数,只要有线程空闲时间超过keepAliveTime的设定,就会被终止;unit则是它的时间单位
- workQueue:任何BlockingQueue都可以使用,基本上有三种
- Direct handoffs,直接交付任务。比如 SynchronousQueue,如果没有线程消费,提交任务会失败,当然可以新建一个线程来处理。它适合处理有依赖关系的任务,一般它的maximumPoolSizes会被设置成最大的
- Unbounded queues,无界队列。比如LinkedBlockingQueue,这意味着如果有corePoolSize个线程在执行,那么其他的任务都只能等待。它适合于处理任务都是互相独立的,
- Bounded queues,有界队列。比如ArrayBlockingQueue,需要考虑队列大小和最大线程数之间的关系,来达到更好的资源利用率和吞吐量
- threadFactory:没有指定的时候,使用
Executors.defaultThreadFactory - RejectedExecutionHandler:通过execute添加的任务,如果Executor已经关闭或者已经饱和了(线程数达到了maximumPoolSize,并且队列满了),就会执行,java提供了4种策略:
- AbortPolicy,拒绝的时候抛出运行时异常RejectedExecutionException;
- CallerRunsPolicy,如果executor没有关闭,那么由调用execute的线程来执行它;
- DiscardPolicy,直接扔掉新的任务;
- DiscardOldestPolicy,如果executor没有关闭,那么扔掉队列头部的任务,再次尝试;
ThreadPoolExecutor可自定义beforeExecutor、afterExecutor可以用来添加日志统计、计时、件事或统计信息收集功能,无论run是正常返回还是抛出异常,afterExecutor都会被执行。如果beforeExecutor抛出RuntimeException,任务和afterExecutor都不会被执行。terminated在所有任务都已经完成,并且所有工作者线程关闭后会调用,此时也可以用来执行发送通知、记录日志等等。
如何估算线程池的大小
- 计算密集型,通常在拥有 个处理器的系统上,线程池大小设置为 能够实现最优的利用率;
cpu的个数
- I/O密集型或者其它阻塞型的任务,定义 为CPU的个数, 为CPU的利用率, 为等待时间与计算时间的比率,此时线程池的最优大小为
场景说明
将一个网站的业务抽象成如下几块
- 接收客户端请求与处理请求
- 页面渲染返回的文本和图片
- 获取页面的广告
接收请求与处理请求
理论模型
理论上,服务端通过实现约定的接口就可以实现接收请求和处理连续不断的请求过来
ServerSocket socket = new ServerSocket(80);
while(true){
Socket conn = socket.accept();
handleRequest(conn)
}
复制代码
缺点:每次只能处理一个请求,新请求到来时,必须等到正在处理的请求处理完成,才能接收新的请求
显示的创建多线程
为每个请求创建新的线程提供服务
ServerSocket socket = new ServerSocket(80);
while(true){
final Socket conn = socket.accept();
Runnable task = new Runnable(){
public void run(){
handleRequest(conn);
}
}
new Thread(task).start();
}
复制代码
缺点:
- 线程的创建和销毁都有一定的开销,延迟对请求的处理;
- 创建后的线程多于可用处理器的数量,造成线程闲置,这会给垃圾回收带来压力
- 存活的大量线程竞争CPU资源会产生很多性能开销
- 系统上对可创建的线程数存在限制
使用线程池
使用java自带的Executor框架。
private static final Executor exec = Executors.newFixedThreadPool(100);
...
ServerSocket socket = new ServerSocket(80);
while(true){
final Socket conn = socket.accept();
Runnable task = new Runnable(){
public void run(){
handleRequest(conn);
}
}
exec.execute(task);
}
...
复制代码
线程池策略通过实现预估好的线程需求,限制并发任务的数量,重用现有的线程,解决每次创建线程的资源耗尽、竞争过于激烈和频繁创建的问题,也囊括了线程的优势,解耦了任务提交和任务执行。
页面渲染返回的文本和图片
串行渲染
renderText(source);
List<ImageData> imageData = new ArrayList<ImageData>();
for(ImageInfo info:scaForImageInfo(source)){
imageData.add(info.downloadImage());
}
for(ImageData data:imageData){
renderImage(data);
}
复制代码
缺点:图像的下载大部分时间在等待I/O操作执行完成,这期间CPU几乎不做任何工作,使得用户看到最终页面之前要等待过长的时间
并行化
渲染过程可以分成两个部分,1是渲染文本,1是下载图像
private static final ExecutorService exec = Executors.newFixedThreadPool(100);
...
final List<ImageInfo> infos=scaForImageInfo(source);
Callable<List<ImageData>> task=new Callable<List<ImageData>>(){
public List<ImageData> call(){
List<ImageData> r = new ArrayList<ImageData>();
for(ImageInfo info:infos){
r.add(info.downloadImage());
}
return r;
}
};
Future<List<ImageData>> future = exec.submit(task);
renderText(source);
try{
List<ImageData> imageData = future.get();
for(ImageData data:imageData){
renderImage(data);
}
}catch(InterruptedException e){
Thread.currentThread().interrupt();
future.cancel(true);
}catche(ExecutionException e){
throw launderThrowable(e.getCause());
}
复制代码
使用Callable来返回下载的图片结果,使用future来获得下载的图片,这样将减少用户所需要的等待时间。
缺点:图片的下载很明显时间要比文本要慢,这样的并行化很可能速度可能只提升了1%
并行性能提升
使用CompletionService。
private static final ExecutorService exec;
...
final List<ImageInfo> infos=scaForImageInfo(source);
CompletionService<ImageData> cService = new ExecutorCompletionService<ImageData>(exec);
for(final ImageInfo info:infos){
cService.submit(new Callable<ImageData>(){
public ImageData call(){
return info.downloadImage();
}
});
}
renderText(source);
try{
for(int i=0,n=info.size();t<n;t++){
Future<ImageData> f = cService.take();
ImageData imageData=f.get();
renderImage(imageData)
}
}catch(InterruptedException e){
Thread.currentThread().interrupt();
}catche(ExecutionException e){
throw launderThrowable(e.getCause());
}
复制代码
核心思路为为每一幅图像下载都创建一个独立的任务,并在线程池中执行他们,从而将串行的下载过程转换为并行的过程
获取页面的广告
广告展示如果在一定的时间以内没有获取,可以不再展示,并取消超时的任务。
ExecutorService exe = Executors.newFixedThreadPool(3);
List<MyTask> myTasks = new ArrayList<>();
for (int i=0;i<3;i++){
myTasks.add(new MyTask(3-i));
}
try {
List<Future<String>> futures = exe.invokeAll(myTasks, 1, TimeUnit.SECONDS);
for (int i=0;i<futures.size();i++){
try {
String s = futures.get(i).get();
System.out.println("task execut "+myTasks.get(i).getSleepSeconds()+" s");
} catch (ExecutionException e) {
System.out.println("task sleep "+myTasks.get(i).getSleepSeconds()+" not execute ");
}catch (CancellationException e){
System.out.println("task sleep "+myTasks.get(i).getSleepSeconds()+" not execute ,because "+e);
}
}
} catch (InterruptedException e) {
e.printStackTrace();
}
exe.shutdown();
复制代码
invokeAll方法对于没有完成的任务会被取消,通过CancellationException可以捕获,invokeAll返回的序列顺序和传入的task保持一致。结果如下:
task sleep 3 not execute ,because java.util.concurrent.CancellationException task sleep 2 not execute ,because java.util.concurrent.CancellationException task execut 1 s 复制代码
正文到此结束
- 本文标签: REST ACE rmi IO 线程 需求 并发 src 处理器 mina 配置 id list http 图片 广告 代码 zab ThreadPoolExecutor queue db 网站 服务端 value ask executor tar 多线程 拒绝策略 final 线程池 ssh cat 垃圾回收 CTO 统计 cache 管理 ArrayList 参数 下载 java Collection 压力 时间 core Service https UI 模型
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

