OpenJDK系列(四):从JVM谈C/C++编译流程
编译器的这点事
gcc和g++还傻傻分不清楚?clang与gcc有什么关系?llvm又是什么?下面将对一些常见的名词进行说明以免在后续阅读中感到疑惑.
gcc和g++
gcc 即 GNU C Compiler, 刚开始它就是一个c编译器项目。后来越来越多的其他语言编译器也被添加到这个项目中,如用于编译c++代码的cc1plus.此时的gcc代表的是一堆编译器的集合(the GNU Compiler Collection).
现在编译系统中,我们执行的gcc已经不是特指当初的C语言编译器了,而是一个编译驱动程序:根据代码源文件后缀名来决定调用哪种的编译器或编译驱动器.比如后缀.c会调用c编译器(cc1)和链接器;如果后缀是.cpp则会调用g++(g++同样是一个驱动程序),g++最终会调用cc1plus编译器及链接器.用张图简单描述如下:
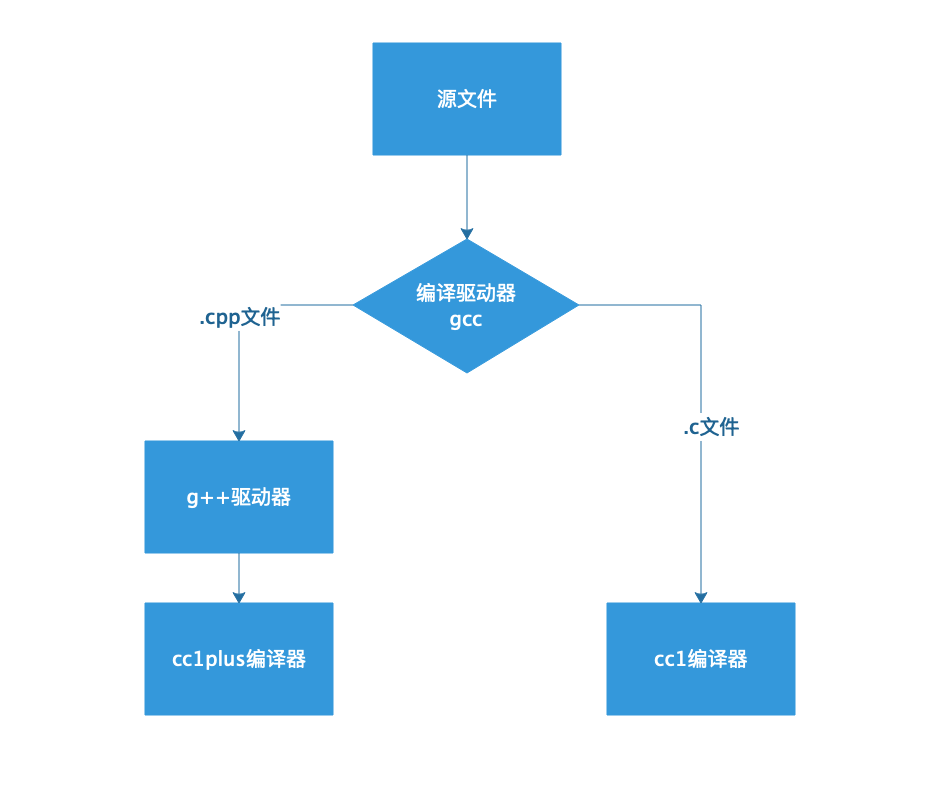
需要注意上图只是用来描述gcc和g++的位置关系.对于HelloWorld.c文件,当然我们也可以直接用g++驱动器,那下述两种方式有什么区别么?
gcc HelloWorld.c -o HelloWorld.out # 或 g++ HelloWorld.c -o HelloWorld.out
-
对于 .c和 .cpp文件,gcc分别当做c和cpp文件编译(c和cpp的语法强度是不一样的)
比如以下代码:
#include <stdio.h> int main(int argc, char* argv[]) { if(argv == 0) return 0; printDebug(argv); return 0; } int printDebug(char* string) { sprintf(string, "debug/n"); }如果将其保存成.c文件,gcc按照C的语法规则对其编译,没有任何问题.但是一旦将其保存为cpp文件,那gcc会按照C++语法规则对其编译,此时报错:
use of undeclared identifier 'printDebug' -
对于 .c和 .cpp文件,g++统一当做cpp文件编译.编译过程中如果遇到C代码,则仍会调用C编译器进行编译.
此外在编译阶段,使用g++会自动链接标准库STL,而gcc不会需要通过指定–lstdc++来进行链接.当然还有一宏定义上的区别,有兴趣的可以进一步探索.
LLVM和Clang
LLVM(Low Level Virtual Machine) 是一个开源的编译器架构,采用C++编写,由Chris Lattner负责.在Chris Lattner加入Apple公司后,Apple公司成为LLVM计划的主要资助者.和其他现代编译器架构一样,LLVM同样分为前端编译器和后端编译器,早期在LLVM架构中最重要组成部分是后端编译器.
Apple公司在早期使用GCC作为其官方的编译工具,但随着Objective-C推出,其中许多新特性需要编译器来支持,但GCC的开发者并不买Apple的帐,同时由于GCC过于复杂繁重,加之和XCode的配合不好,Apple公司在LLVM的基础上开发前端编译器Clang以取代GCC.现代LLVM整体架构如下,关于前端编译器和后端编译器后续说明.
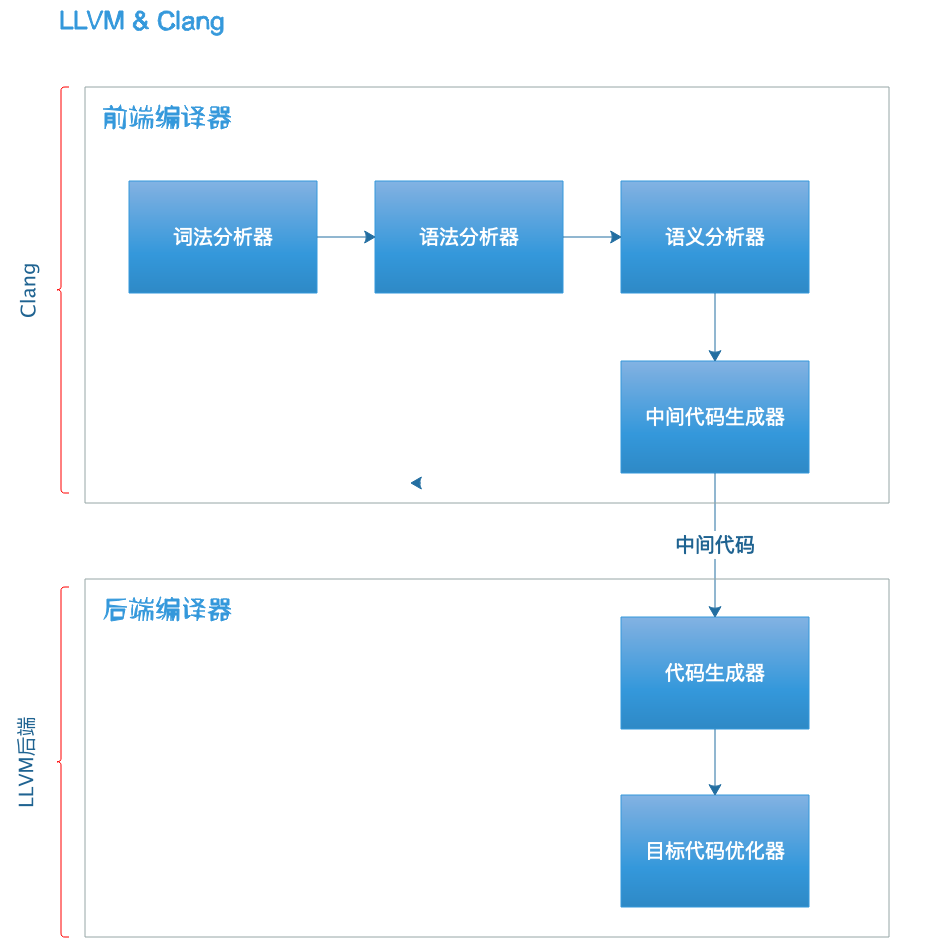
相比于 GCC,Clang 具有如下优点:
- 更快的编译速度:在某些平台上,Clang 的编译速度要比GCC快很多
- 内存占用小:Clang 生成的 AST 所占用的内存要远远小于GCC
- Clang输出的信息更详细,更容易理解,和GCC相比,更易排查和定位问题
- 诊断信息可读性强:在编译过程中,Clang 创建并保留了大量详细的元数据 (metadata),有利于调试和错误报告。
- Clang采用模块化设计,整个项目相比GCC要清晰简单,扩展性较好.
当然Clang由于面世时间较短,其最大的问题仍然是对语言和平台的支持度不够,和GCC相比,Clang目前只支持C/C++/Objective-C/Objective-C++/Swift,且当前只能应用于Linux/Windows/Mac OS.
另外通过下图来展示Apple公司中编译系统的演化过程:
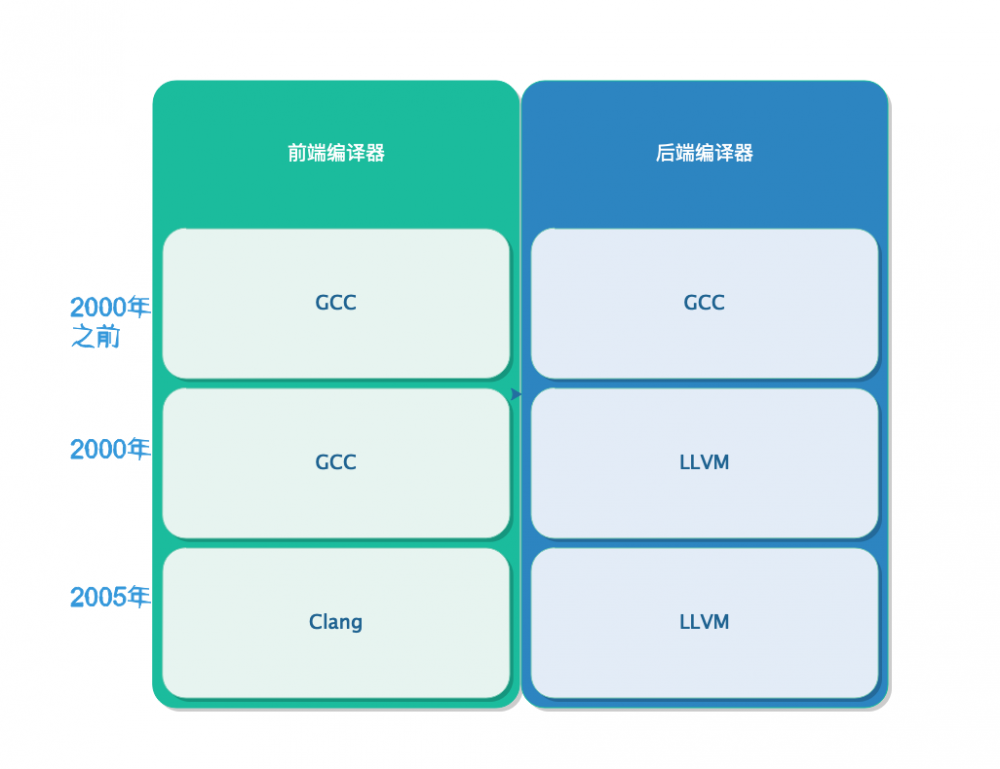
需要注意,从Mac OS X 10.9/Xcode 5开始,系统中已经不预装GCC了.此时我们在MacOS中使用的gcc只是clang的别名.此时通过 gcc -v 查看版本信息:
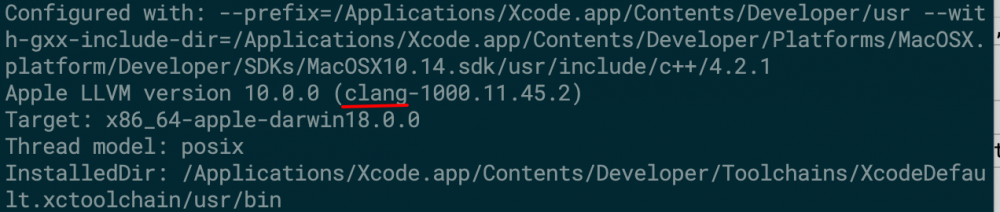
在大多情况,使用clang并不会遇到什么问题.但如果你从事Android系统开发,那么在编译MTK平台上会遇到编译错误,其原因在于MTK的某些工具只支持GCC.
尽管在细节来看Mac OS中的gcc(即clang)和Linux下gcc有所差异,但不妨碍我们整体把握编译流程.如果你想体会原汁原味的GCC,那么在Mac OS可使用Hombrew自行安装:
# 查看Homebrew支持的Gcc版本,目前支持:apple-gcc42,gcc,gcc@4.9,gcc@5,gcc@6,gcc@7 brew search gcc # 安装指定版本,比如这里我安装gcc-6 brew install gcc@6
安装完成后,gcc的命令需要替换为gcc-6,比如 gcc HelloWorld.c 需要修改为 gcc-6 HelloWorld.c .如果你不想这么麻烦,那么将为gcc-6定义别名,在.bash_profile中添加以下:
alias gcc='gcc-6' alias cc='gcc-6' alias g++='g++-6' alias c++='c++-6'
添加完成后,保存退出,执行 source ~/.bash_profile 使其生效,这样我们就可以使用真正的gcc了:
GDB和LLDB
GDB是GCC中提供的诊断工具,调试时非常有用.同样的,在Clang中也提供了类似的诊断工具 LLDB .LLDB在GDB的基础上进行扩展,更加好用.从XCode 4.3开始,已经默认LLDB来代替之前的GDB了.得益于LLDB良好的兼容性,对于IOS开发者而言,基本上可以实现平稳过渡.
C语言编译流程
学习OpenJDK首先要学会如何编译OpenJDK,之前在OpenJDK根目录下执行.configure脚本即可实现对OpenJDK的编译.抱着知其然更知其所以然的态度,我们重新来捋一捋关于编译的事情,当然由于VM主要是由C/C++来开发的,因此我们这里谈的编译就非Java视角中的编译了.
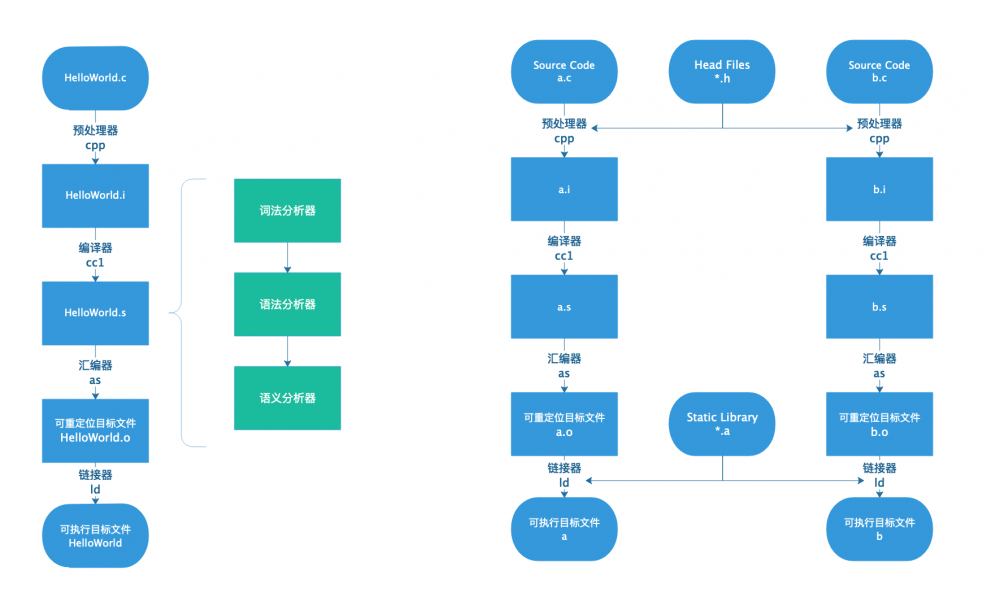
C++是C语言的超集,其编译流程和C编译流程一样,这里选择C语言.C语言的源码文件的扩展名是.c,最终其可执行文件的扩展名是.out.任何一个.c到.out都要经过以下四步:
- 预处理(Prepressing)
- 编译(Compilation)
- 汇编(Assembly)
- 链接(Linking)
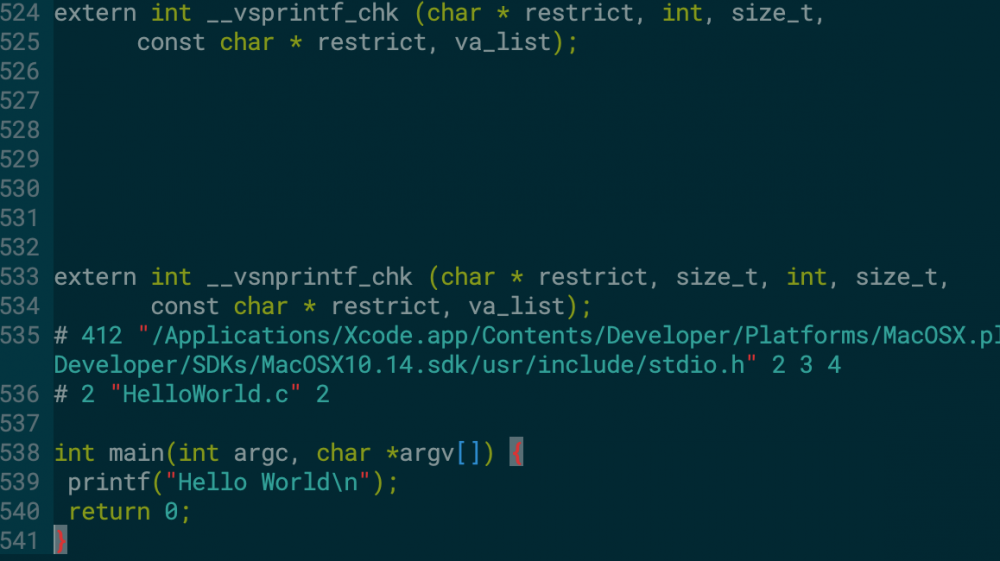
需要注意的是,使用IDE开发时所谈的编译是个高层概念,是以上四个步骤的统称.以下述代码HelloWorld.c为例:
#include <stdio.h>
int main(int argc, char *argv[]) {
printf("Hello World/n");
return 0;
}
在命令行工具中执行以下命令来编译并运行该程序:
gcc HelloWorld.c -o HelloWorld ./HelloWorld
第一行命令实际上就是对HelloWorld.c依次进行了 预处理->编译->汇编->链接 操作,得到可执行文件HelloWorld.out;第二行命令则是对HelloWorld.out进行装载操作.
下面分开来看每个过程.gcc允许指定不同的参数来了控制整个编译过程,下表中是我们将要用到的参数
| 参数 | 说明 |
|---|---|
| -E | 只进行预处理,不进行编译,汇编,链接 |
| -S | 只进行编译,不进行汇编和链接 |
| -c | 进行编译和汇编,不进行链接 |
| -o | 输出可执行文件 |
预编译过程主要包括删除注释,添加行号和文件名标志等用于调试的信息以及处理源代码中以"#"开始的预编译指令.C语言中常用的预编译指令有:
- 宏定义指令
#define - 条件编译指令
#if,#ifdef,#elif,#else,#endif - 文件包含指令
#include -
#pragma编译器指令
预处理器对不同的预编译指令有不同的处理过程,简单概括为:
-
#include:将被包含的文件插入到该预编译指令的位置.该过程是递归进行的,也就是被包含的文件可能还包含其他文件. -
#define:将所有的#define删除,并展开所有的宏定义 -
#pragma:保留所有的#pragma指令
预处理之后的文件扩展名是.i,其本质仍然是C代码.执行以下命令获得预处理之后的文件:
gcc -E HelloWorld.c -o HelloWorld.i
编译过程需要编译器的介入,所谓的编译器就是将一种语言编译另一种语言的工具.对于C语言编译器而言,在Linux上由程序cc1实现从c转为汇编代码的过程,该过程涉及一系列的词法分析,语法分析,语义分析及优化后生成相应的汇编代码文件.cc1会对预处理后生成的.i文件进行处理以生成对应的汇编代码,通过执行以下命令来获得编译后的文件:
gcc -S HelloWorld.i -o HelloWorld.s # 或 gcc -S HelloWorld.c -o HelloWorld.s
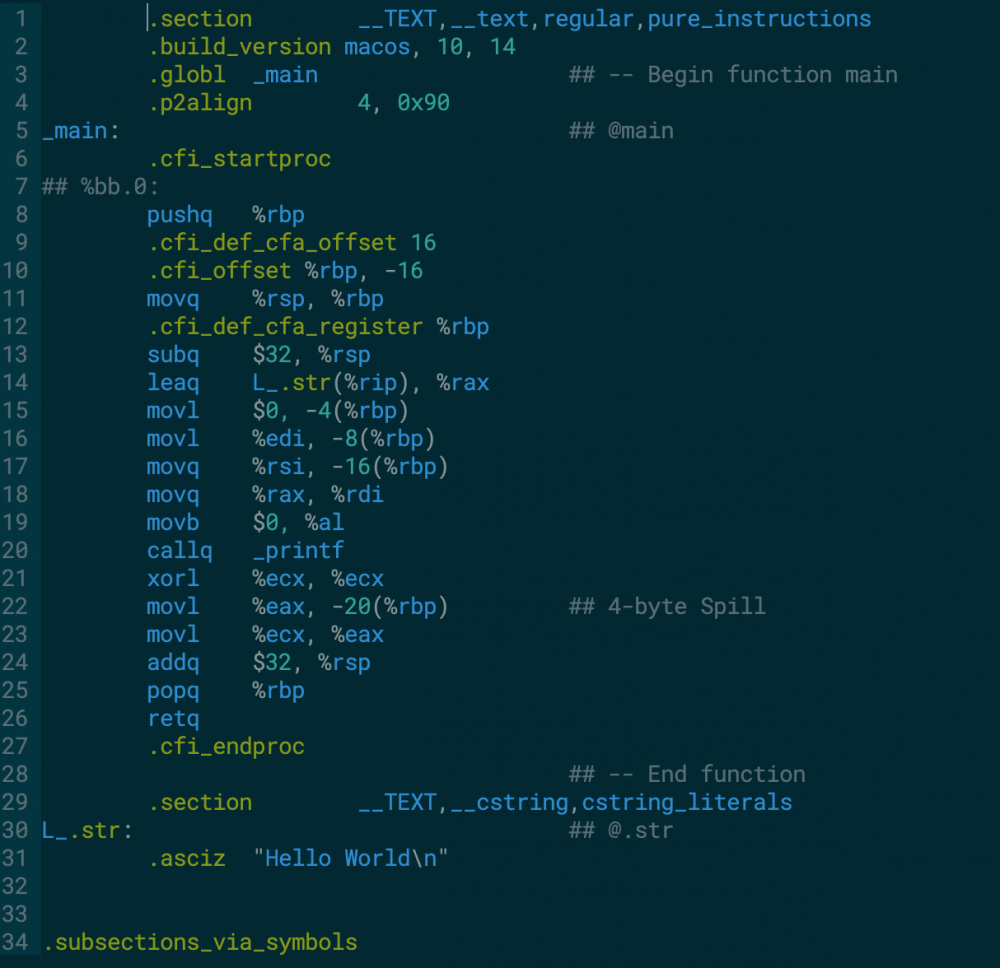
用一句话来描述汇编语言:所谓的汇编代码就是不同CPU指令二进制代码对应助记符的集合.汇编代码需要借助汇编器才能转换为平台相关的二进制代码.
词法分析
词法分析是编译过程的第一阶段,也称为扫描,其主要任务是读入源程序的输入字符,并将其分割成一系列的词法单元(Token),最终输出一个词法单元序列.以代码 int result = (index +2) * (5 - 2) 为例,分析之后生成的词法单元序列如下:
| 词法单元 | 属性 |
|---|---|
| int | 标志符 |
| = | 赋值 |
| ( | 左括号 |
| index | 标志符 |
| + | 加号 |
| 2 | 数字 |
| ) | 右括号 |
| * | 乘号 |
| ( | 左括号 |
| 5 | 数字 |
| - | 加号 |
| 2 | 数字 |
| ) | 右括号 |
语法分析
接下来词法分析器会对由词法分析器生成的词法单元序列进行语法分析,从而产生语法树.至于生成语法的方法不做详解,有兴趣的同学可以阅读龙书.还是以 int result = (index +2) * (5 - 2) 为例:

该赋值表达式左边是一个变量,右边是一个乘法表达式.这里符号和数字就是最小的表达式,表现为树的叶子节点.在语法分析的过程中,运算符的优先级和含义也会被确认下来.在分析的过程,如果表达式不合法,比如缺少括号不匹配,编译就会报错.
语义分析
正如我们英语翻译,语法分析能够保证当前句子合乎语法规则,但一个正确的句子还应该有正确的语义.比如 Dog is pig 合乎语法,但是却没有正确的语义.对于代码表达式而言,保证语义正确性同样是不可或缺的,比如对一个指针和浮点数进行乘法操作是否合法,赋值操作类型是否合法等等.
根据其检查的时机不同,语义分析分为静态语义分析和动态语义分析.静态语义分析作用于编译阶段,比如类型检查等;动态语义分析作用于运行阶段,比如数组访问越界等.同样表达式 int result = (index +2) * (5 - 2) 为例:
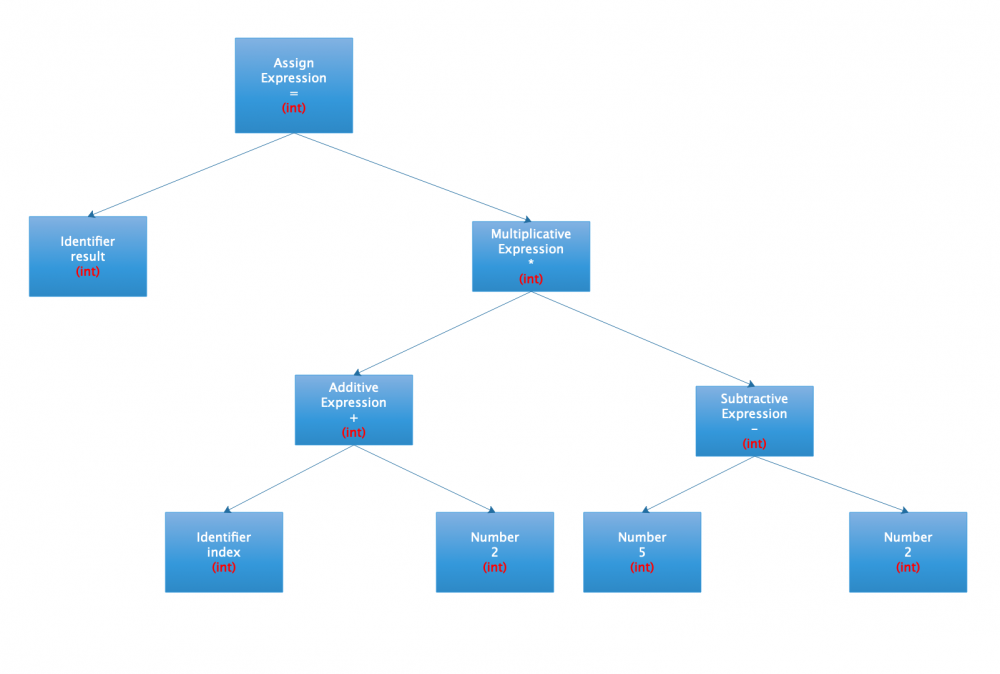
不难发现,语义分析完后,整个语法树的节点被标志了类型.实际上,整个语义分析的过程更为复杂,只不过由于我们的表达式比较简单,且本文重点不在于描述编译的细节,因此很多地方我们一笔带过.
中间代码生成
将给定语言翻译成特定的目标机器代码的过程中,编译器可能会构造出一系列的中间表示.其中高层的中间的表示接近于源代码,而底层中间表示接近于目标机器代码.
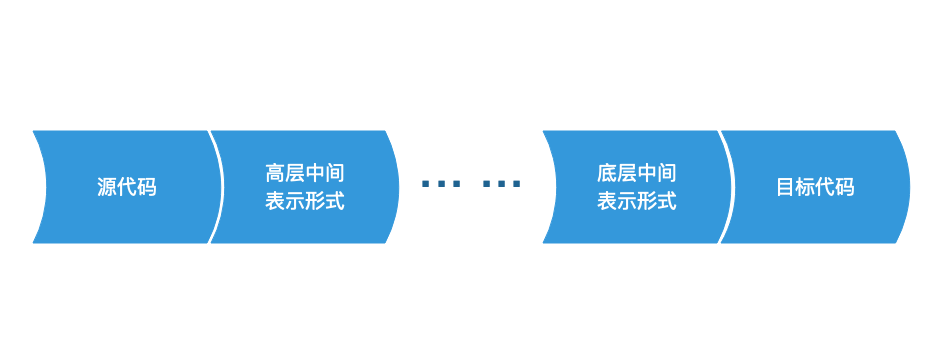
语法树是高层的表示,描述了源代码的自然的层次性结构;低层次的表示形式适用于机器相关的处理任务.为什么不是源代码直接翻译成目标代码,而要加入中间代码呢?
其原因在于编译器在执行过程中不仅仅是按部就班的进行代码的转换,还需要进行一定的优化.要直接在语法树上进行优化相对困难,因此引入了中间代码,然后在中间代码的基础上进行一系列的操作.仍然以 int result = (index +2) * (5 - 2) 为例,由于子表达式(5-2)在编译阶段即可确定值为3,因此最终会被优化成 int result = (index + 2) * 3 .这里我们只是举了简单的例子,实际上编译器对代码的优化流程非常复杂.后面会用单独的篇幅来讲述.
此外以中间代码为分割线,可以将编译器分为前端编译器和后端编译器.前端编译器负责生成与平台无关的中间代码,后端编译器则负责将其转换为目标代码.从这方面来说中间代码的引入也为支持多平台提供了有力的帮助.
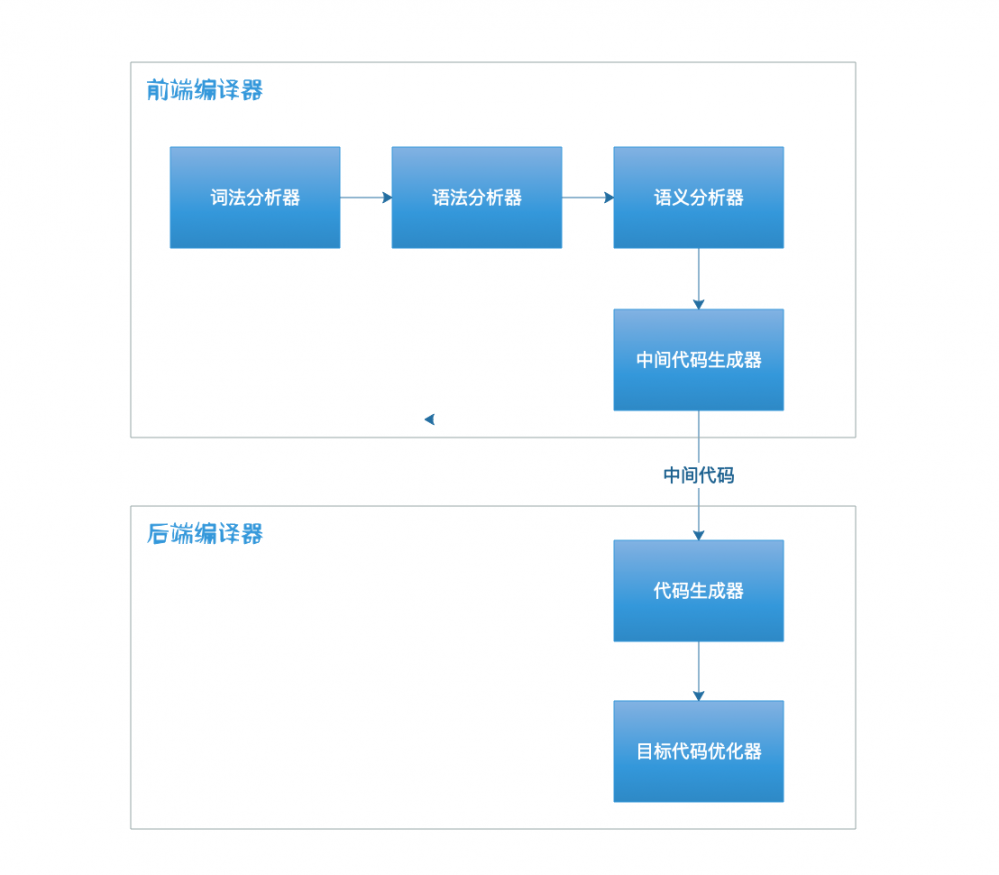
到现在关于前端编译器已经说清楚了,接下来便是目标代码的生成,即后端编译器的主要功能.
前端编译器最终生成的中间代码会作为后端编译器的输入,其中后端编译器主要包括用于生成目标代码的代码生成器以及对目标机器代码进行优化的目标代码优化器.其中目标代码优化器最终目标提高寻址速度以及减少指令调用以提供性能.
C/C++生成的中间代码是汇编语言,因此需用到汇编器将汇编代码转成机器代码(此处的汇编器即代码生成器).和编译器相比,汇编器比较简单:多数情况下每个汇编语句都对应于一条机器指令,因此汇编器只需要按汇编指令和机器指令的对照表一一进行翻译即可.
通过执行以下指令来进行汇编操作,最终得到可重定位目标文件HelloWorld.o:
as HelloWorld.s -o HelloWorld.o # 或 gcc -c HelloWorld.c -o HelloWorld.o
常见的三种格式的目标文件如下表所示:
| 格式 | 说明 |
|---|---|
| 可重定位目标文件(Relocatable File) | 包含数据和二进制代码,可以在编译时与其他可重定位目标合并,创建一个可执行目标文件 |
| 可执行目标文件(Executable File) | 包含数据和二进制代码,可以直接被复制到到内存并执行.其典型代表为Linux下的ELF |
| 共享目标文件(Shared Object File) | 特殊类型的可重定位目标文件,包含数据和二进制代码,可在加载或者运行时被动态地加载到内存并连接. |
目标文件中存放是与源程序等效的目标机器语言代码.在目标文件中,引入了Section概念,它是一种数据结构,有时我们也称之为段.根据描述对象的不同划分了不同的段,目前只需要用于描述源代码的代码段以及用于变量的数据段即可
由汇编程序生成的目标文件通常不能被直接运行.比如一个项目有许多模块组成,不同的模块之间存在引用关系,如何将这些模块"拼接"成一个可执行的程序的过程就叫做链接.更准确说,链接就是各种代码和数据片段收集并组合成一个单一文件的过程,这个文件可以加载到内存并执行.为了构造可执行目标文件,链接器需要完成以下两个功能:
- 符号解析(symbol resolution):目标文件定义和引用符号,每个符号对应于一个函数,全局变量/静态变量,符号解析需要将每个符号引用正好是符号定义关联起来.
- 重定位(relocation):编译器和汇编器生成从地址0开始的代码段/数据段,链接器通过把每个符号定义和内存位置关联起来,从而重定位这些段(定位了段,根据段内代码的偏移量也就可以定位具体的代码/数据),然后修改对这些符号的引用,使它们指向这个内存位置,以便代码能被正确的运行.
此外根据作用的时期不同,链接分为编译时链接,加载时链接和运行时链接.像Java这种语言采用的是加载时链接.对C而言我们常说的是静态链接和动态链接.
通过执行以下指令来进行链接操作,最终得到可执行目标文件HelloWorld:
gcc HelloWorld.s -o HelloWorld
现在有了可执行目标文件后,就可以将其加载到内存并运行.链接的过程比较有趣,后面会另加解释.
到现在为止整个编译流程已经描述完成,下图是整个编译流程的描述.(此处的编译是我们说的高层概念)
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

