Netty LineBasedFrameDecoder 剖析(Netty Bug)
前言
Netty 自带多个粘包拆包解码器。今天介绍 LineBasedFrameDecoder,换行符解码器。看起来简单,但当前版本(2018-09-04)是一个 bug,此 bug 截止本文发布时,已被修复。
属性分析
- maxLength (每个完整的包的最大长度)
- failFast (是否快速失败,默认 false)
- discarding (是否进入丢弃模式)
- discardedBytes 丢弃字节数(用于抛出异常时提醒)
- offset 用于优化每次读取效率(bug 就是这里)
- stripDelimiter 是否应该剔除分隔符,默认剔除
decode 方法解析(包括 findEndOfLine())
虽然官方注释标注此解码器为换行符解码器,但我认为这是一个“换行符+最大长度”的一个解码器。
说下此解码器的逻辑:
首先限制单个包的大小,也是说,换行符和换行符之间的数据包的大小是用户配置的。超过最大则抛出异常。
每当有数据到来时,都会遍历缓冲区,找换行符,如果找到了,就返回数据;如果没找到,就记录此次读取到下标 offset,下次继续找。
如果找的过程中,长度超过用户设置的 maxLength,就进入丢弃模式:丢弃之前读取的所有字节,并根据 failFast 的属性决定什么时候抛出异常(如果是 true,则不等找到换行符,就抛出异常,反之,等找到换行符了,才抛出异常,这个异常是可以被用户的 exceptionCaught 方法捕获到的)。
整个流程大概如下图:

这里有个注意的地方:每当发现长度超出 maxLength 时,应该丢弃之前的所有数据,并重置 offset,代码如下:
if (length > maxLength) {// 如果大于愿意解码的最大长度,废弃
discardedBytes = length;// 废弃字节数
buffer.readerIndex(buffer.writerIndex());// 更新读下标
discarding = true;// 开启丢弃模式,因为tcp 包大小已经大于最大长度.
offset = 0;// 最后一次扫描次数重置
if (failFast) {// 如果是快速失败,抛出异常
fail(ctx, "over " + discardedBytes);
}
}
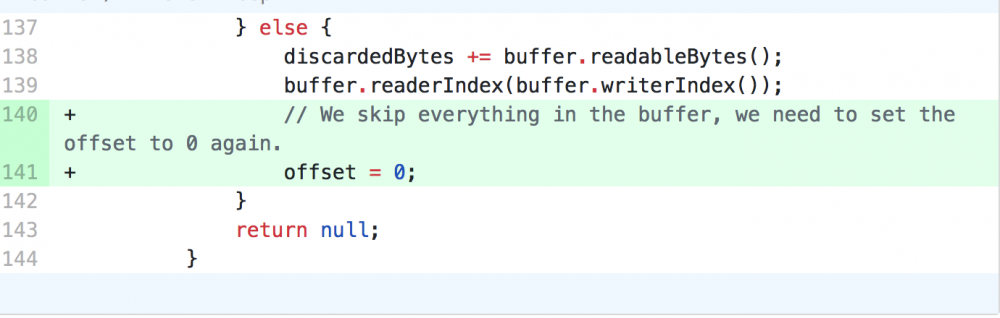
但是,在丢弃模式的 netty 代码,却没有将 offset 重置为 0。代码如下:
·····忽略
} else {
discardedBytes += buffer.readableBytes();
buffer.readerIndex(buffer.writerIndex());
// offset = 0;
}
注意:offset 的代码是我加的,本来是没有的。这将导致 findEndOfLine 方法的下标越界。
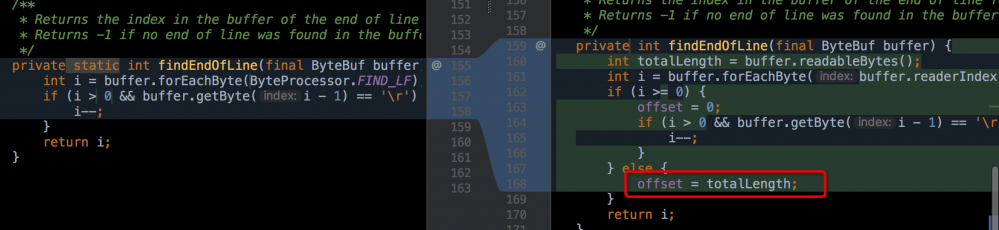
private int findEndOfLine(final ByteBuf buffer) {
int totalLength = buffer.readableBytes();
int i = buffer.forEachByte(buffer.readerIndex() + offset, totalLength - offset, ByteProcessor.FIND_LF);
if (i >= 0) {
offset = 0;
if (i > 0 && buffer.getByte(i - 1) == '/r') {
i--;
}
} else {
offset = totalLength;
}
return i;
}
这里,注意:每次读取不到换行符的时候,offset 都会设置为这次的读下标,而 decode 方法中,已经执行了 buffer.readerIndex(buffer.writerIndex()) 方法,更新了读下标,当执行 forEach 方法的时候(+ offset),就会出现下标越界!
具体的重现方法我已经提了 issue: issue#8256 地址
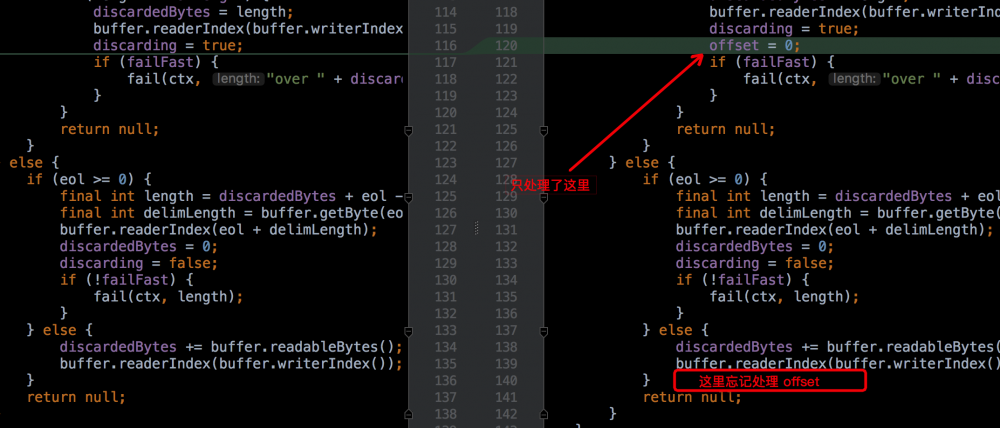
作者诺曼(苹果基础架构工程师)也进行了修改并提交了代码:
而这个 bug 的作者本来是想优化这个代码的,初始代码是没有这个 offset 优化的,结果写出来个 bug, = =!:
最后,最重要的一点是,这个 bug 是艿艿发现的!有关 Netty,Dubbo等一切 Java开源框架的疑问都可以找他!他的公众号:

总结
总结,此文虽然没什么技术含量,但是给我提了一个醒,强如 netty ,也会有 bug,因此要具有批判精神,即使再权威,我们也要有怀疑精神,去研究,去反向推导,才能有真正的收获。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

