从Java极速入门Go
本文适合有Java开发经验且想学习Go的同学,是一篇非常适合入门Go语言的教程,本文只会涉及部分Go的核心内容,不适合想系统学习Go的同学,但也提供了系统学习的方式。
Go语言简介
下面是对Go的简单介绍,可以先了解一下,如果有哪些暂时无法理解的可以先跳过,学完【极速入门】之后回头来看就会恍然大悟。

简介
Go是一门语法非常简单的开源编程语言,目的是让程序开发变得更有生产效率。
Go是一门静态类型的编译型语言,通过在不同平台上的相应编译器来实现跨平台特性。
Go是一门广纳百家之长的语言,看起来像既像C++又像Delphi、Python,实则是吸收其他语言的优势,又针对其他语言的痛点进行设计。
它的并发机制使编写能够充分利用多线程的程序变得容易,其新颖的类型系统可实现灵活的模块化程序构建,是一门为大数据、微服务、高并发、云计算而生的通用语言。
与Java对比
- 面向对象。Go不完全是面向对象的语言,因为没有【对象】的概念与关键字而是提供了结构体struct关键字,并且没有类型层次结构,比如没有继承、多态、泛型的支持。但是允许面向对象的编程风格,比如可以在struct里定义对象的内容,还能结合接口灵活实现。
- 接口。Go中的【接口】不是必须明确标注被实现才能使用某对象,而是使用 duck typing 的方式提供了一种易于使用且更为通用的不同方法。结合上一点,所以Go语言在对于构建和使用对象时更加灵活
- 异常处理。无异常处理机制try catch,因为将异常耦合到业务代码中会导致代码更加复杂,并且倾向于定义出很多普通的错误。Go还可以利用函数多返回值来将可处理的异常作为一个返回值返回给调用者。
- 并发编程。Java中有很多针对多线程底层操作,如互斥,条件变量和内存屏障,这些过分强调低级细节,是的多线程编程难度较大。而Go中的【CSP并发模型】让开发人员不用关心这些细节,而是通过goruntime和在channel中传递消息的方式进行通信也能实现高效的并发程序
- 效率。程序执行速度远胜于Java,得益于Go是通过先编译链接后得到可执行文件的,而不是在运行时通过虚拟机解释运行。至于开发效率个人认为主要取决于对语言和相应框架使用的熟练程度。
- 部署。Go编译后生成的是一个可执行文件,除了glibc外没有任何外部依赖,完全不需要操行应用所需要的各种包、依赖关系,大大减轻了维护的负担
- 应用场景。Java的应用场景包括移动应用、应用服务器程序、客户端程序、嵌入式、大数据,可以说非常广,服务器到客户端、底层和应用层都能涵盖。Go则适合写服务器程序、大数据,以及基础设施程序如Docker、K8S,由于其语法简单、并发编程人性化、执行效率高所以在云计算领域中也是举足轻重的存在,但移动应用、嵌入式、客户端程序不是Go擅长的方向。
极速入门
环境搭建
Go语言安装
https://golang.org/dl/ 选择1.10.3版本下载
IDE安装
IntelliJ IDEA中下载Go插件或者直接下载 GoLand
如果你不习惯Windows的快捷键设置, IDEA-Mac-Keymap-On-Windows 将Mac上的Command键改成左Alt键或许可以帮到你。
HelloWorld
让我们正式来体验Go语言,以下所有代码你应该先想一下大致应该如何写,然后看应该如何写,最后自己再写一遍直至跑通,有任何问题及时去搜索理解。
首先还是得从hello world开始。现在IDE中创建一个项目,在项目根目录下创建一个名为 helloworld.go 的文件,输入以下代码:
package main //必须是main包才能定义出一个可执行的入口,main命名与文件名无关
import "fmt" //一个格式化输出的核心库
func main(){ //函数命名格式:func 函数名(参数) 返回值
fmt.Println("hello world!")
}
通过IDE的运行按钮或者在命令行中输入 go run helloworld.go 运行它
SimpleSpider
接下来介绍一个简单的爬虫来体验一部分Go语言的特性。不用马上动手实现它,而是从它开始简单看看Go的语法,Go的并发编程模型,等系统学习之后再来试试能不能实现。
这个爬虫的工作原理如下:首先准备一些想要抓取的网页Url作为种子传给Engine,由Engine负责流程控制,Engine会把Url传给Worker中的Fetcher来下载具体的HTML文件,然后发送给Url对应的Parser解析函数得到想要抓取的信息以及当前页面上可以继续当做种子再次抓取的Url,最后将Url与对应的Parser传给Engine继续抓取。
其中支持并发的Worker与单个Engine传递与接收数据使用的是go runtime与channel实现,可以来感受一下前所未有的并发编程体验。Worker数量越多,爬虫效率越高。
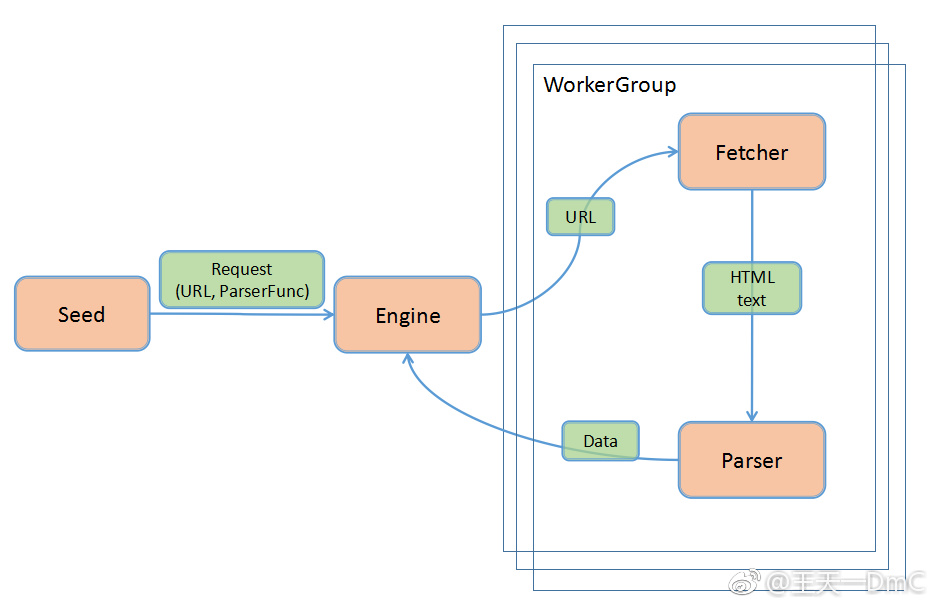
先在根目录下将不同模块的文件夹创建出来,有engine, fetcher, parser三个,然后在根目录把入口程序spider.go写好:
func main() {
engine.SimpleEngine{ // engine是我们需要实现的一个程序包,创建engine包中的SimpleEngine结构
WorkerCount: 100, // worker开启数量
}.Run(engine.Request{ // 被调用的Run方法需要被定义在该结构体的内部
Url: "http://www.zhenai.com/zhenghun", //第一个参数是用于被抓取的网页的URL
ParserFunc: parser.ParseCityList, //第二个参数是对于不同Url编写的不同的解析器
})
}
在engine文件夹中新建types.go将Request结构体定义:
type Request struct {
Url string
ParserFunc func([]byte) ParseResult // 解析函数,不同的Url可能对应不同的解析函数,传入HTML的字节数组
// 传出HTML中解析出来的可以继续当成种子的Request和HTML中的有效信息
}
type ParseResult struct {
Requests []Request //从HTML中解析出来的种子
Items []interface{} //任意类型的数组结构
}
接下来了解一下goruntime与channel。goroutine是Go里的一种轻量级线程——协程。相对线程,协程的优势就在于它非常轻量级,进行上下文切换的代价非常的小,通过go关键字传入一个方法就能开启一个协程。
channel是一种带有类型的变量类型,你可以通过它用channel操作符 <- 在不同的协程之间来发送或者接收值。默认情况下,发送和接收操作在另一端准备好之前都会阻塞。这使得 Go 程可以在没有显式的锁或竞态变量的情况下进行同步,从而大大降低了并发编程的难度,提升了开发效率。
接下来看engine中的核心代码:
type SimpleEngine struct { // 创建engine结构体用以在创建时接受参数,但这并不是构造函数,Go中没有构造函数与析构函数
WorkerCount int
}
// 为SimpleEngine结构体定义Run方法。SimpleEngine为该方法的值接受者。
// 由于方法经常需要修改它的接收者,指针接收者比值接收者更常用;参数是可变长的类型,用来传入多个种子
func (e SimpleEngine) Run(seeds ...Request) {
in := make(chan Request) // 创建种子输入channel,其中可以传递的数据为Request,worker将从这里取,engine将种子往这里放
out := make(chan ParseResult) // 种子输出channel,其中可以传递的数据为ParseResult,worker将解析结果传到这里交给engine
// 开启若干个worker协程,等待种子被放入
for i := 0; i < e.WorkerCount; i++ {
go func() {
for {
// 开始时所有worker都被阻塞,等待种子被传入
r := <-in // 创建r变量,初始值从输入channel中获取
// 收到某个种子,开始解析
result, e := worker(r)
if e != nil {
continue
}
// 将任务执行结果传回engine,但是这里如果直接写out <- result会无法执行,因为有循环等待产生,原因:
// 想要执行这行代码必须需要有engine在执行①开始等待才行,但是engine执行这行代码的前提完成②的输入
// 也就是需要有空闲的worker在等待接受in,然而此时worker正在执行本行命令
go func() {out <- result}()
}
}()
}
// 传入种子到输入channel
for _, request := range seeds {
in <- request
}
for { // 循环结构只有for关键字,这里是当成while(true)使用,让engine一直运行,等待worker返回的数据
① parseResult := <- out
// 现在是打印得到的数据,以后将改为保存到数据库
for _, item := range parseResult.Items { // 相当于foreach,第一个返回值是index,第二个是object,_代表不使用
log.Printf("Got item %v/n", item)
}
// 存储后将后续种子发送给输入channel
for _, r := range parseResult.Requests {
② in <- r
}
}
}
func worker(r Request) (ParseResult, error) {
log.Printf("Fetching %s", r.Url)
// 下载html内容
body, e := fetcher.Fetch(r.Url)
if e != nil {
log.Printf("Fetcher error with url: %s. %v", r.Url, e)
return ParseResult{}, e
}
// 根据request里提供的解析方法解析当前html内容成为result放入队列
return r.ParserFunc(body), nil
}
核心代码就是以上,但还需要实现负责下载的fetcher和负责解析的parser,完整代码可查看 https://github.com/xbox1994/GoCrawler 中的crawler_standalone学习
依赖包安装
由于GFW的关系,当你在安装某个依赖包时,可能被挡住,推荐按以下的顺序来尝试安装go的依赖包(xxx代表包的地址) 1. go get xxx 2. 使用gopm安装,先下载gopm: go get -v -u github.com/gpmgo/gopm ,然后 gopm get -g -v xxx 3. 去对应的github主页上, git clone 下来并放到GOROOT或GOPATH目录的src文件夹下,并将下载的文件夹命名为包的地址
Beego
Beego是国人开发的一款Go web框架,这里查看相关 简介
它的功能全面、结构清晰、上手容易、有一定社区活跃度但代码质量不高,适合快速开发。
接下来请按照官网 quickstart 的例子来快速体验一把。
在这个例子中要注意的是,Go的方法参数传递只有值传递,没有引用传递,也就是如果传递一个任意类型的变量给某个方法,那么这个变量将被复制一份传给函数内部,所以在函数内部对这个变量进行操作则是对原变量的副本进行操作,如果想直接操作原变量的内容,使用&将地址传进去即可。
系统学习推荐
本文仅仅是用到了小部分Go的语法和功能特性来尝试带领你入门,还有很多值得了解的比如数组的切片、duck typing 接口、反射,希望你看完之后一定不要止步于此,一切都才刚刚开始,下一步就是开始进行系统的学习了。
这个 知乎回答 可能对你有所帮助,但很不幸给的链接很多都需要翻墙。
参考
https://coding.imooc.com/learn/list/180.html
https://golang.org/doc/faq
https://www.zhihu.com/question/21409296
https://beego.me/quickstart
https://tour.go-zh.org正文到此结束
- 本文标签: key 同步 Go语言 微服务 云 质量 线程 多线程 Docker 开源 FAQ 回答 windows 数据库 大数据 HTML文件 锁 下载 模型 编译 人性 IDE parse 并发编程 python 高并发 服务器 tar 数据 解析 开发 ACE id root UI 参数 http 希望 web https 安装 HTML 插件 src 工作原理 java git map 代码 list lib IO 并发 目录 struct cat GitHub
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

