Java集合源码学习(3)LinkedList
ArrayList,数组是顺序存储结构,存储区间是连续的,占用内存严重,故空间复杂的很大。但数组的二分查找时间复杂度小,为O(1),数组的特点是寻址容易,插入和删除困难。 LinkedList使用链表作为存储结构,链表是线性存储结构,在内存上不是连续的一段空间,占用内存比较宽松,故空间复杂度很小,但时间复杂度很大,达O(N),链表的特点是寻址困难,插入和删除容易。
在JDK1.7之前,LinkedList是采用双向环形链表来实现的,在1.7及之后,Oracle将LinkedList做了优化,将环形链表改成了线性链表。
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
复制代码
LinkedList继承了AbstractSequentialList,实现了List,Deque,Cloneable,Serializable 接口
(1)继承和实现
继承AbstractSequentialList类,提供了相关的添加、删除、修改、遍历等功能。
实现List接口,提供了相关的添加、删除、修改、遍历等功能。 实现 Deque 接口,即能将LinkedList当作双端队列使用,可以用做队列或者栈。 实现了Cloneable接口,即覆盖了函数clone(),能被克隆。 实现java.io.Serializable接口,LinkedList支持序列化,能通过序列化传输。
(2)线程安全
LinkedList是非同步的,即线程不安全,如果有多个线程同时访问LinkedList,可能会抛出ConcurrentModificationException异常。
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
复制代码
(3)节点Node结构:
private static class Node<E> {
E item;//元素值
Node<E> next;//后置节点
Node<E> prev;//前置节点
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
复制代码
(4)addAll方法:
//addAll ,在尾部批量增加 复制代码
public boolean addAll(Collection<? extends E> c) { return addAll(size, c);//以size为插入下标,插入集合c中所有元素 } //以index为插入下标,插入集合c中所有元素 public boolean addAll(int index, Collection<? extends E> c) { checkPositionIndex(index);//检查越界 [0,size] 闭区间
Object[] a = c.toArray();//拿到目标集合数组
int numNew = a.length;//新增元素的数量
if (numNew == 0)//如果新增元素数量为0,则不增加,并返回false
return false;
Node<E> pred, succ; //index节点的前置节点,后置节点
if (index == size) { //在链表尾部追加数据
succ = null; //size节点(队尾)的后置节点一定是null
pred = last;//前置节点是队尾
} else {
succ = node(index);//取出index节点,作为后置节点
pred = succ.prev; //前置节点是,index节点的前一个节点
}
//链表批量增加,是靠for循环遍历原数组,依次执行插入节点操作。对比ArrayList是通过System.arraycopy完成批量增加的
for (Object o : a) {//遍历要添加的节点。
@SuppressWarnings("unchecked") E e = (E) o;
Node<E> newNode = new Node<>(pred, e, null);//以前置节点 和 元素值e,构建new一个新节点,
if (pred == null) //如果前置节点是空,说明是头结点
first = newNode;
else//否则 前置节点的后置节点设置问新节点
pred.next = newNode;
pred = newNode;//步进,当前的节点为前置节点了,为下次添加节点做准备
}
if (succ == null) {//循环结束后,判断,如果后置节点是null。 说明此时是在队尾append的。
last = pred; //则设置尾节点
} else {
pred.next = succ; // 否则是在队中插入的节点 ,更新前置节点 后置节点
succ.prev = pred; //更新后置节点的前置节点
}
size += numNew; // 修改数量size
modCount++; //修改modCount
return true;
}
//根据index 查询出Node,
Node<E> node(int index) {
// assert isElementIndex(index);
//通过下标获取某个node 的时候,(增、查 ),会根据index处于前半段还是后半段 进行一个折半,以提升查询效率
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
private void checkPositionIndex(int index) {
if (!isPositionIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
private boolean isPositionIndex(int index) {
return index >= 0 && index <= size; //插入时的检查,下标可以是size [0,size]
}
复制代码
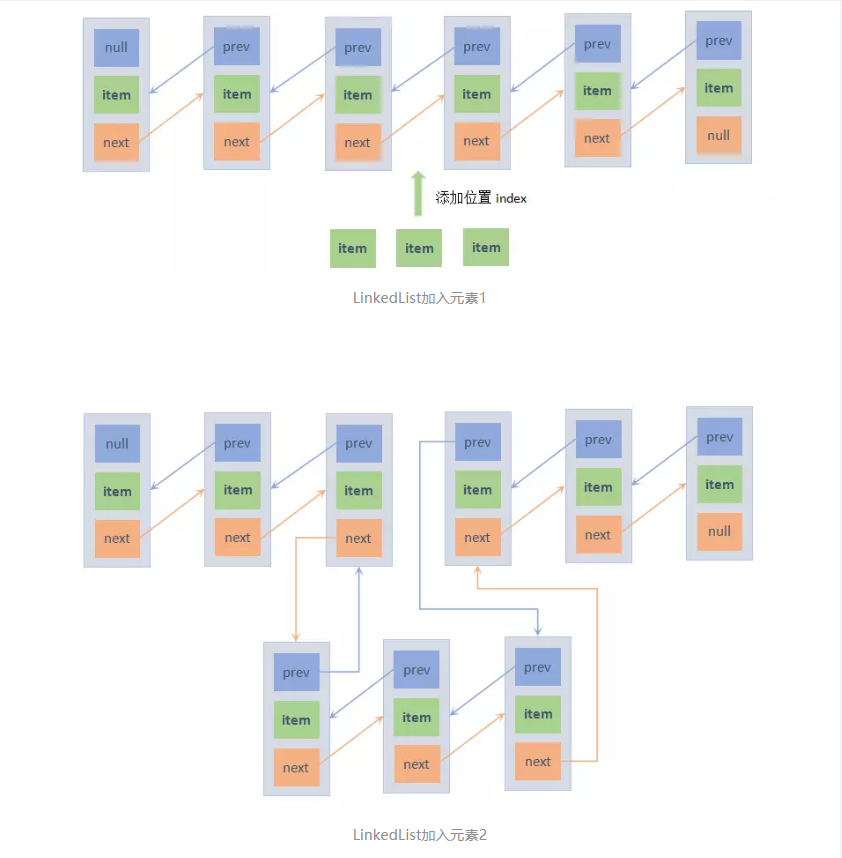
在构造方法中调用addAll方法,相当于是向一个空链表中添加集合c中的元素。 如果是在已有元素的链表中调用addAll方法来添加元素的话,就需要判断指定的添加位置index是否越界,如果越界会抛出异常;如果没有越界,根据添加的位置index,断开链表中index位置的节点前后的引用,加入新元素,重新连上断开位置的前后节点的引用。过程如下图:(此处用了xiaoyanger的图)
(5)toArray()方法:
public Object[] toArray() {
//new 一个新数组 然后遍历链表,将每个元素存在数组里,返回
Object[] result = new Object[size];
int i = 0;
for (Node<E> x = first; x != null; x = x.next)
result[i++] = x.item;
return result;
}
复制代码
这个方法的实现很简单。
(6)总结:
LinkedList 是双向列表。
链表批量增加,是靠for循环遍历原数组,依次执行插入节点操作。对比ArrayList是通过System.arraycopy完成批量增加的。增加一定会修改modCount。 通过下标获取某个node 的时候,(add select),会根据index处于前半段还是后半段 进行一个折半,以提升查询效率 删也一定会修改modCount。 按下标删,也是先根据index找到Node,然后去链表上unlink掉这个Node。 按元素删,会先去遍历链表寻找是否有该Node,如果有,去链表上unlink掉这个Node。 改也是先根据index找到Node,然后替换值。改不修改modCount。 查本身就是根据index找到Node。 所以它的CRUD(Create,Retrieve,Update,Delete)操作里,都涉及到根据index去找到Node的操作。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

