高并发的“大杀器”:异步化、并行化

高并发的大杀器:异步化
同步和异步,阻塞和非阻塞
同步和异步,阻塞和非阻塞,这几个词已经是老生常谈,但是还是有很多同学分不清楚,以为同步肯定就是阻塞,异步肯定就是非阻塞,其实他们并不是一回事。
同步和异步关注的是结果消息的通信机制:
- 同步:调用方需要主动等待结果的返回。
- 异步:不需要主动等待结果的返回,而是通过其他手段,比如状态通知,回调函数等。
阻塞和非阻塞主要关注的是等待结果返回调用方的状态:
- 阻塞:是指结果返回之前,当前线程被挂起,不做任何事。
- 非阻塞:是指结果在返回之前,线程可以做一些其他事,不会被挂起。
可以看见同步和异步,阻塞和非阻塞主要关注的点不同,有人会问同步还能非阻塞,异步还能阻塞?
当然是可以的,下面为了更好的说明它们的组合之间的意思,用几个简单的例子说明:
同步阻塞:同步阻塞基本也是编程中最常见的模型,打个比方你去商店买衣服,你去了之后发现衣服卖完了,那你就在店里面一直等,期间不做任何事(包括看手机),等着商家进货,直到有货为止,这个效率很低。
- 同步非阻塞:同步非阻塞在编程中可以抽象为一个轮询模式,你去了商店之后,发现衣服卖完了。
这个时候不需要傻傻的等着,你可以去其他地方比如奶茶店,买杯水,但是你还是需要时不时的去商店问老板新衣服到了吗。
- 异步阻塞:异步阻塞这个编程里面用的较少,有点类似你写了个线程池,submit 然后马上 future.get(),这样线程其实还是挂起的。
有点像你去商店买衣服,这个时候发现衣服没有了,这个时候你就给老板留个电话,说衣服到了就给我打电话,然后你就守着这个电话,一直等着它响什么事也不做。这样感觉的确有点傻,所以这个模式用得比较少。
- 异步非阻塞:这也是现在高并发编程的一个核心,也是今天主要讲的一个核心。
好比你去商店买衣服,衣服没了,你只需要给老板说这是我的电话,衣服到了就打。然后你就随心所欲的去玩,也不用操心衣服什么时候到,衣服一到,电话一响就可以去买衣服了。
同步阻塞 PK 异步非阻塞
上面已经看到了同步阻塞的效率是多么的低,如果使用同步阻塞的方式去买衣服,你有可能一天只能买一件衣服,其他什么事都不能干;如果用异步非阻塞的方式去买,买衣服只是你一天中进行的一个小事。
我们把这个映射到我们代码中,当我们的线程发生一次 RPC 调用或者 HTTP 调用,又或者其他的一些耗时的 IO 调用。
发起之后,如果是同步阻塞,我们的这个线程就会被阻塞挂起,直到结果返回,试想一下,如果 IO 调用很频繁那我们的 CPU 使用率会很低很低。
正所谓是物尽其用,既然 CPU 的使用率被 IO 调用搞得很低,那我们就可以使用异步非阻塞。
当发生 IO 调用时我并不马上关心结果,我只需要把回调函数写入这次 IO 调用,这个时候线程可以继续处理新的请求,当 IO 调用结束时,会调用回调函数。
而我们的线程始终处于忙碌之中,这样就能做更多的有意义的事了。这里首先要说明的是,异步化不是万能,异步化并不能缩短你整个链路调用时间长的问题,但是它能极大的提升你的最大 QPS。
一般我们的业务中有两处比较耗时:
- CPU:CPU 耗时指的是我们的一般的业务处理逻辑,比如一些数据的运算,对象的序列化。这些异步化是不能解决的,得需要靠一些算法的优化,或者一些高性能框架。
- IO Wait:IO 耗时就像我们上面说的,一般发生在网络调用,文件传输中等等,这个时候线程一般会挂起阻塞。而我们的异步化通常用于解决这部分的问题。
哪些可以异步化
上面说了异步化是用于解决 IO 阻塞的问题,而我们一般项目中可以使用异步化的情况如下:
- Servlet 异步化
- Spring MVC 异步化
- RPC 调用如(Dubbo,Thrift),HTTP 调用异步化
- 数据库调用,缓存调用异步化
下面我会从上面几个方面进行异步化的介绍。
Servlet 异步化
对于 Java 开发程序员来说 Servlet 并不陌生,在项目中不论你使用 Struts2,还是使用的 Spring MVC,本质上都是封装的 Servlet。
但是我们一般的开发都是使用的同步阻塞,模式如下:
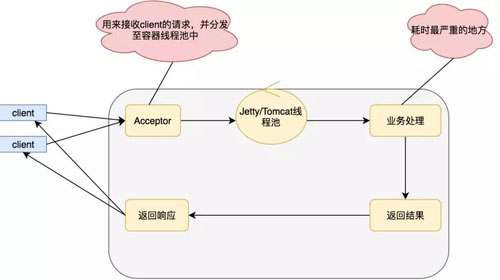
上面的模式优点在于编码简单,适合在项目启动初期,访问量较少,或者是 CPU 运算较多的项目。
缺点在于,业务逻辑线程和 Servlet 容器线程是同一个,一般的业务逻辑总得发生点 IO,比如查询数据库,比如产生 RPC 调用,这个时候就会发生阻塞。
而我们的 Servlet 容器线程肯定是有限的,当 Servlet 容器线程都被阻塞的时候我们的服务这个时候就会发生拒绝访问,线程不够我当然可以通过增加机器的一系列手段来解决这个问题。
但是俗话说得好靠人不如靠自己,靠别人替我分担请求,还不如我自己搞定。
所以在 Servlet 3.0 之后支持了异步化,我们采用异步化之后,模式变成如下:
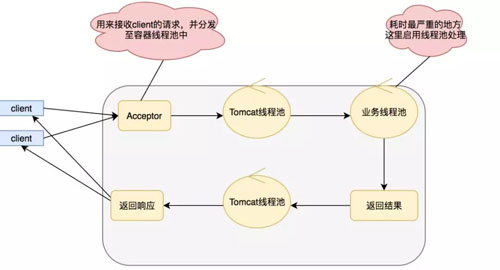
在这里我们采用新的线程处理业务逻辑,IO 调用的阻塞就不会影响我们的 Serlvet 了,实现异步 Serlvet 的代码也比较简单,如下:
@WebServlet(name = "WorkServlet",urlPatterns = "/work",asyncSupported =true)
public class WorkServlet extends HttpServlet{
private static final long serialVersionUID = 1L;
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
this.doPost(req, resp);
}
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
//设置ContentType,关闭缓存
resp.setContentType("text/plain;charset=UTF-8");
resp.setHeader("Cache-Control","private");
resp.setHeader("Pragma","no-cache");
final PrintWriter writer= resp.getWriter();
writer.println("老师检查作业了");
writer.flush();
List<String> zuoyes=new ArrayList<String>();
for (int i = 0; i < 10; i++) {
zuoyes.add("zuoye"+i);;
}
//开启异步请求
final AsyncContext ac=req.startAsync();
doZuoye(ac, zuoyes);
writer.println("老师布置作业");
writer.flush();
}
private void doZuoye(final AsyncContext ac, final List<String> zuoyes) {
ac.setTimeout(1*60*60*1000L);
ac.start(new Runnable() {
@Override
public void run() {
//通过response获得字符输出流
try {
PrintWriter writer=ac.getResponse().getWriter();
for (String zuoye:zuoyes) {
writer.println("/""+zuoye+"/"请求处理中");
Thread.sleep(1*1000L);
writer.flush();
}
ac.complete();
} catch (Exception e) {
e.printStackTrace();
}
}
});
}
}
实现 Serlvet 的关键在于 HTTP 采取了长连接,也就是当请求打过来的时候就算有返回也不会关闭,因为可能还会有数据,直到返回关闭指令。
AsyncContext ac=req.startAsync();用于获取异步上下文,后续我们通过这个异步上下文进行回调返回数据,有点像我们买衣服的时候,留给老板一个电话。
而这个上下文也是一个电话,当有衣服到的时候,也就是当有数据准备好的时候就可以打电话发送数据了。ac.complete();用来进行长链接的关闭。
Spring MVC 异步化
现在其实很少人来进行 Serlvet 编程,都是直接采用现成的一些框架,比如 Struts2,Spring MVC。下面介绍下使用 Spring MVC 如何进行异步化:
首先确认你的项目中的 Servlet 是 3.0 以上,其次 Spring MVC 4.0+:
<dependency> <groupId>javax.servlet</groupId> <artifactId>javax.servlet-api</artifactId> <version>3.1.0</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-webmvc</artifactId> <version>4.2.3.RELEASE</version> </dependency>
web.xml 头部声明,必须要 3.0,Filter 和 Serverlet 设置为异步:
<?xml version="1.0" encoding="UTF-8"?> <web-app version="3.0" xmlns="http://java.sun.com/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_3_0.xsd"> <filter> <filter-name>testFilter</filter-name> <filter-class>com.TestFilter</filter-class> <async-supported>true</async-supported> </filter> <servlet> <servlet-name>mvc-dispatcher</servlet-name> <servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class> ......... <async-supported>true</async-supported> </servlet>
使用 Spring MVC 封装了 Servlet 的 AsyncContext,使用起来比较简单。以前我们同步的模式的 Controller 是返回 ModelAndView。
而异步模式直接生成一个 DeferredResult(支持我们超时扩展)即可保存上下文,下面给出如何和我们 HttpClient 搭配的简单 demo:
@RequestMapping(value="/asynctask", method = RequestMethod.GET)
public DeferredResult<String> asyncTask() throws IOReactorException {
IOReactorConfig ioReactorConfig = IOReactorConfig.custom().setIoThreadCount(1).build();
ConnectingIOReactor ioReactor = new DefaultConnectingIOReactor(ioReactorConfig);
PoolingNHttpClientConnectionManager conManager = new PoolingNHttpClientConnectionManager(ioReactor);
conManager.setMaxTotal(100);
conManager.setDefaultMaxPerRoute(100);
CloseableHttpAsyncClient httpclient = HttpAsyncClients.custom().setConnectionManager(conManager).build();
// Start the client
httpclient.start();
//设置超时时间200ms
final DeferredResult<String> deferredResult = new DeferredResult<String>(200L);
deferredResult.onTimeout(new Runnable() {
@Override
public void run() {
System.out.println("异步调用执行超时!thread id is : " + Thread.currentThread().getId());
deferredResult.setResult("超时了");
}
});
System.out.println("/asynctask 调用!thread id is : " + Thread.currentThread().getId());
final HttpGet request2 = new HttpGet("http://www.apache.org/");
httpclient.execute(request2, new FutureCallback<HttpResponse>() {
public void completed(final HttpResponse response2) {
System.out.println(request2.getRequestLine() + "->" + response2.getStatusLine());
deferredResult.setResult(request2.getRequestLine() + "->" + response2.getStatusLine());
}
public void failed(final Exception ex) {
System.out.println(request2.getRequestLine() + "->" + ex);
}
public void cancelled() {
System.out.println(request2.getRequestLine() + " cancelled");
}
});
return deferredResult;
}
注意:在 Serlvet 异步化中有个问题是 Filter 的后置结果处理,没法使用,对于我们一些打点,结果统计直接使用 Serlvet 异步是没法用的。
在 Spring MVC 中就很好的解决了这个问题,Spring MVC 采用了一个比较取巧的方式通过请求转发,能让请求再次通过过滤器。
但是又引入了新的一个问题那就是过滤器会处理两次,这里可以通过 Spring MVC 源码中自身判断的方法。
我们可以在 Filter 中使用下面这句话来进行判断是不是属于 Spring MVC 转发过来的请求,从而不处理 Filter 的前置事件,只处理后置事件:
Object asyncManagerAttr = servletRequest.getAttribute(WEB_ASYNC_MANAGER_ATTRIBUTE); return asyncManagerAttr instanceof WebAsyncManager ;
全链路异步化
上面我们介绍了 Serlvet 的异步化,相信细心的同学都看出来似乎并没有解决根本的问题,我的 IO 阻塞依然存在,只是换了个位置而已。
当 IO 调用频繁同样会让业务线程池快速变满,虽然 Serlvet 容器线程不被阻塞,但是这个业务依然会变得不可用。
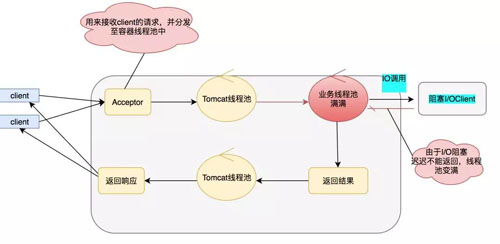
那么怎么才能解决上面的问题呢?答案就是全链路异步化,全链路异步追求的是没有阻塞,打满你的 CPU,把机器的性能压榨到极致。模型图如下:
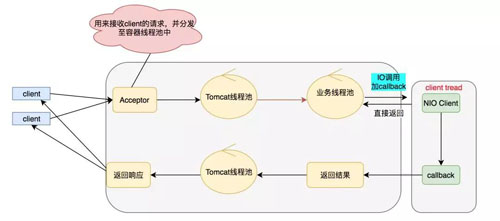
具体的 NIO Client 到底做了什么事呢,具体如下面模型:

上面就是我们全链路异步的图了(部分线程池可以优化)。全链路的核心在于只要我们遇到 IO 调用的时候,我们就可以使用 NIO,从而避免阻塞,也就解决了之前说的业务线程池被打满的尴尬场景。
远程调用异步化
我们一般远程调用使用 RPC 或者 HTTP:
- 对于 RPC 来说,一般 Thrift,HTTP,Motan 等支持都异步调用,其内部原理也都是采用事件驱动的 NIO 模型。
- 对于 HTTP 来说,一般的 Apache HTTP Client 和 Okhttp 也都提供了异步调用。
下面简单介绍下 HTTP 异步化调用是怎么做的。首先来看一个例子:
public class HTTPAsyncClientDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException, IOReactorException {
//具体参数含义下文会讲
//apache提供了ioReactor的参数配置,这里我们配置IO 线程为1
IOReactorConfig ioReactorConfig = IOReactorConfig.custom().setIoThreadCount(1).build();
//根据这个配置创建一个ioReactor
ConnectingIOReactor ioReactor = new DefaultConnectingIOReactor(ioReactorConfig);
//asyncHttpClient使用PoolingNHttpClientConnectionManager管理我们客户端连接
PoolingNHttpClientConnectionManager conManager = new PoolingNHttpClientConnectionManager(ioReactor);
//设置总共的连接的最大数量
conManager.setMaxTotal(100);
//设置每个路由的连接的最大数量
conManager.setDefaultMaxPerRoute(100);
//创建一个Client
CloseableHttpAsyncClient httpclient = HttpAsyncClients.custom().setConnectionManager(conManager).build();
// Start the client
httpclient.start();
// Execute request
final HttpGet request1 = new HttpGet("http://www.apache.org/");
Future<HttpResponse> future = httpclient.execute(request1, null);
// and wait until a response is received
HttpResponse response1 = future.get();
System.out.println(request1.getRequestLine() + "->" + response1.getStatusLine());
// One most likely would want to use a callback for operation result
final HttpGet request2 = new HttpGet("http://www.apache.org/");
httpclient.execute(request2, new FutureCallback<HttpResponse>() {
//Complete成功后会回调这个方法
public void completed(final HttpResponse response2) {
System.out.println(request2.getRequestLine() + "->" + response2.getStatusLine());
}
public void failed(final Exception ex) {
System.out.println(request2.getRequestLine() + "->" + ex);
}
public void cancelled() {
System.out.println(request2.getRequestLine() + " cancelled");
}
});
}
}
下面给出 httpAsync 的整个类图:
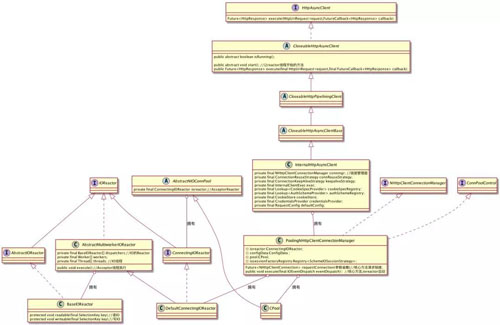
对于我们的 HTTPAysncClient 最后使用的是 InternalHttpAsyncClient,在 InternalHttpAsyncClient 中有个 ConnectionManager,这个就是我们管理连接的管理器。
而在 httpAsync 中只有一个实现那就是 PoolingNHttpClientConnectionManager。
这个连接管理器中有两个我们比较关心的,一个是 Reactor,一个是 Cpool:
- Reactor:所有的 Reactor 这里都是实现了 IOReactor 接口。在 PoolingNHttpClientConnectionManager 中会有拥有一个 Reactor,那就是 DefaultConnectingIOReactor,这个 DefaultConnectingIOReactor,负责处理 Acceptor。
在 DefaultConnectingIOReactor 有个 excutor 方法,生成 IOReactor 也就是我们图中的 BaseIOReactor,进行 IO 的操作。这个模型就是我们上面的 1.2.2 的模型。
- CPool:在 PoolingNHttpClientConnectionManager 中有个 CPool,主要是负责控制我们连接,我们上面所说的 maxTotal 和 defaultMaxPerRoute,都是由其进行控制。
如果每个路由有满了,它会断开最老的一个链接;如果总共的 total 满了,它会放入 leased 队列,释放空间的时候就会将其重新连接。
数据库调用异步化
对于数据库调用一般的框架并没有提供异步化的方法,这里推荐自己封装或者使用网上开源的。
异步化并不是高并发的银弹,但是有了异步化的确能提高你机器的 QPS,吞吐量等等。
上述讲的一些模型如果能合理的做一些优化,然后进行应用,相信能对你的服务有很大的帮助。
高并发大杀器:并行化
想必热爱游戏的同学小时候都幻想过要是自己会分身之术,就能一边打游戏一边上课了。
可惜现实中并没有这个技术,你要么只有老老实实的上课,要么就只有逃课去打游戏了。
虽然在现实中我们无法实现分身这样的技术,但是我们可以在计算机世界中实现这样的愿望。
计算机中的分身术
计算机中的分身术不是天生就有了。在 1971 年,英特尔推出的全球第一颗通用型微处理器 4004,由 2300 个晶体管构成。
当时,公司的联合创始人之一戈登摩尔就提出大名鼎鼎的“摩尔定律”——每过 18 个月,芯片上可以集成的晶体管数目将增加一倍。
最初的主频 740KHz(每秒运行 74 万次),现在过了快 50 年了,大家去买电脑的时候会发现现在的主频都能达到 4.0GHZ了(每秒 40 亿次)。
但是主频越高带来的收益却是越来越小:
- 据测算,主频每增加 1G,功耗将上升 25 瓦,而在芯片功耗超过 150 瓦后,现有的风冷散热系统将无法满足散热的需要。有部分 CPU 都可以用来煎鸡蛋了。
- 流水线过长,使得单位频率效能低下,越大的主频其实整体性能反而不如小的主频。
- 戈登摩尔认为摩尔定律未来 10-20 年会失效。
在单核主频遇到瓶颈的情况下,多核 CPU 应运而生,不仅提升了性能,并且降低了功耗。
所以多核 CPU 逐渐成为现在市场的主流,这样让我们的多线程编程也更加的容易。
说到了多核 CPU 就一定要说 GPU,大家可能对这个比较陌生,但是一说到显卡就肯定不陌生,笔者搞过一段时间的 CUDA 编程,我才意识到这个才是真正的并行计算。
大家都知道图片像素点吧,比如 1920*1080 的图片有 210 万个像素点,如果想要把一张图片的每个像素点都进行转换一下,那在我们 Java 里面可能就要循环遍历 210 万次。
就算我们用多线程 8 核 CPU,那也得循环几十万次。但是如果使用 Cuda,最多可以 365535*512 = 100661760(一亿)个线程并行执行,就这种级别的图片那也是马上处理完成。
但是 Cuda 一般适合于图片这种,有大量的像素点需要同时处理,但是指令集很少所以逻辑不能太复杂。
应用中的并行
一说起让你的服务高性能的手段,那么异步化,并行化这些肯定会第一时间在你脑海中显现出来,并行化可以用来配合异步化,也可以用来单独做优化。
我们可以想想有这么一个需求,在你下外卖订单的时候,这笔订单可能还需要查用户信息,折扣信息,商家信息,菜品信息等。
用同步的方式调用,如下图所示:
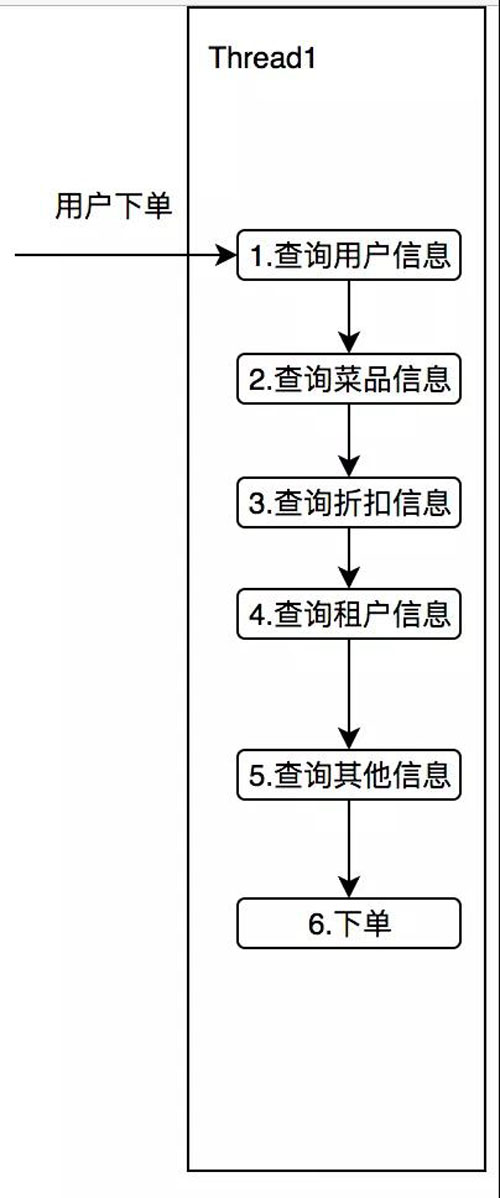
设想一下这 5 个查询服务,平均每次消耗 50ms,那么本次调用至少是 250ms,我们细想一下,这五个服务其实并没有任何的依赖,谁先获取谁后获取都可以。
那么我们可以想想,是否可以用多重影分身之术,同时获取这五个服务的信息呢?
优化如下:
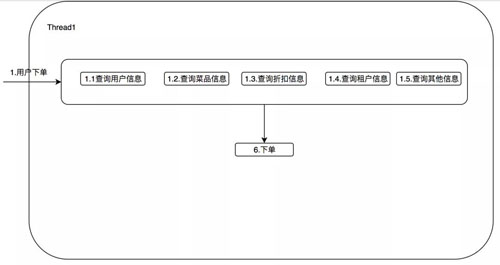
将这五个查询服务并行查询,在理想情况下可以优化至 50ms。当然说起来简单,我们真正如何落地呢?
CountDownLatch/Phaser
CountDownLatch 和 Phaser 是 JDK 提供的同步工具类。Phaser 是 1.7 版本之后提供的工具类。而 CountDownLatch 是 1.5 版本之后提供的工具类。
这里简单介绍一下 CountDownLatch,可以将其看成是一个计数器,await()方法可以阻塞至超时或者计数器减至 0,其他线程当完成自己目标的时候可以减少 1,利用这个机制我们可以用来做并发。
可以用如下的代码实现我们上面的下订单的需求:
public class CountDownTask {
private static final int CORE_POOL_SIZE = 4;
private static final int MAX_POOL_SIZE = 12;
private static final long KEEP_ALIVE_TIME = 5L;
private final static int QUEUE_SIZE = 1600;
protected final static ExecutorService THREAD_POOL = new ThreadPoolExecutor(CORE_POOL_SIZE, MAX_POOL_SIZE,
KEEP_ALIVE_TIME, TimeUnit.SECONDS, new LinkedBlockingQueue<>(QUEUE_SIZE));
public static void main(String[] args) throws InterruptedException {
// 新建一个为5的计数器
CountDownLatch countDownLatch = new CountDownLatch(5);
OrderInfo orderInfo = new OrderInfo();
THREAD_POOL.execute(() -> {
System.out.println("当前任务Customer,线程名字为:" + Thread.currentThread().getName());
orderInfo.setCustomerInfo(new CustomerInfo());
countDownLatch.countDown();
});
THREAD_POOL.execute(() -> {
System.out.println("当前任务Discount,线程名字为:" + Thread.currentThread().getName());
orderInfo.setDiscountInfo(new DiscountInfo());
countDownLatch.countDown();
});
THREAD_POOL.execute(() -> {
System.out.println("当前任务Food,线程名字为:" + Thread.currentThread().getName());
orderInfo.setFoodListInfo(new FoodListInfo());
countDownLatch.countDown();
});
THREAD_POOL.execute(() -> {
System.out.println("当前任务Tenant,线程名字为:" + Thread.currentThread().getName());
orderInfo.setTenantInfo(new TenantInfo());
countDownLatch.countDown();
});
THREAD_POOL.execute(() -> {
System.out.println("当前任务OtherInfo,线程名字为:" + Thread.currentThread().getName());
orderInfo.setOtherInfo(new OtherInfo());
countDownLatch.countDown();
});
countDownLatch.await(1, TimeUnit.SECONDS);
System.out.println("主线程:"+ Thread.currentThread().getName());
}
}
建立一个线程池(具体配置根据具体业务,具体机器配置),进行并发的执行我们的任务(生成用户信息,菜品信息等),最后利用 await 方法阻塞等待结果成功返回。
CompletableFuture
相信各位同学已经发现,CountDownLatch 虽然能实现我们需要满足的功能但是其仍然有个问题是,我们的业务代码需要耦合 CountDownLatch 的代码。
比如在我们获取用户信息之后,我们会执行 countDownLatch.countDown(),很明显我们的业务代码显然不应该关心这一部分逻辑,并且在开发的过程中万一写漏了,那我们的 await 方法将只会被各种异常唤醒。
所以在 JDK 1.8 中提供了一个类 CompletableFuture,它是一个多功能的非阻塞的 Future。(什么是 Future:用来代表异步结果,并且提供了检查计算完成,等待完成,检索结果完成等方法。)
我们将每个任务的计算完成的结果都用 CompletableFuture 来表示,利用 CompletableFuture.allOf 汇聚成一个大的 CompletableFuture,那么利用 get()方法就可以阻塞。
public class CompletableFutureParallel {
private static final int CORE_POOL_SIZE = 4;
private static final int MAX_POOL_SIZE = 12;
private static final long KEEP_ALIVE_TIME = 5L;
private final static int QUEUE_SIZE = 1600;
protected final static ExecutorService THREAD_POOL = new ThreadPoolExecutor(CORE_POOL_SIZE, MAX_POOL_SIZE,
KEEP_ALIVE_TIME, TimeUnit.SECONDS, new LinkedBlockingQueue<>(QUEUE_SIZE));
public static void main(String[] args) throws InterruptedException, ExecutionException, TimeoutException {
OrderInfo orderInfo = new OrderInfo();
//CompletableFuture 的List
List<CompletableFuture> futures = new ArrayList<>();
futures.add(CompletableFuture.runAsync(() -> {
System.out.println("当前任务Customer,线程名字为:" + Thread.currentThread().getName());
orderInfo.setCustomerInfo(new CustomerInfo());
}, THREAD_POOL));
futures.add(CompletableFuture.runAsync(() -> {
System.out.println("当前任务Discount,线程名字为:" + Thread.currentThread().getName());
orderInfo.setDiscountInfo(new DiscountInfo());
}, THREAD_POOL));
futures.add( CompletableFuture.runAsync(() -> {
System.out.println("当前任务Food,线程名字为:" + Thread.currentThread().getName());
orderInfo.setFoodListInfo(new FoodListInfo());
}, THREAD_POOL));
futures.add(CompletableFuture.runAsync(() -> {
System.out.println("当前任务Other,线程名字为:" + Thread.currentThread().getName());
orderInfo.setOtherInfo(new OtherInfo());
}, THREAD_POOL));
CompletableFuture allDoneFuture = CompletableFuture.allOf(futures.toArray(new CompletableFuture[futures.size()]));
allDoneFuture.get(10, TimeUnit.SECONDS);
System.out.println(orderInfo);
}
}
可以看见我们使用 CompletableFuture 能很快的完成需求,当然这还不够。
Fork/Join
我们上面用 CompletableFuture 完成了对多组任务并行执行,但是它依然是依赖我们的线程池。
在我们的线程池中使用的是阻塞队列,也就是当我们某个线程执行完任务的时候需要通过这个阻塞队列进行,那么肯定会发生竞争,所以在 JDK 1.7 中提供了 ForkJoinTask 和 ForkJoinPool。
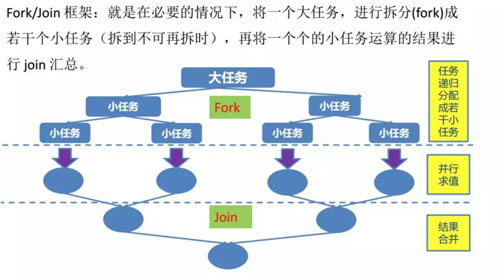
ForkJoinPool 中每个线程都有自己的工作队列,并且采用 Work-Steal 算法防止线程饥饿。
Worker 线程用 LIFO 的方法取出任务,但是会用 FIFO 的方法去偷取别人队列的任务,这样就减少了锁的冲突。
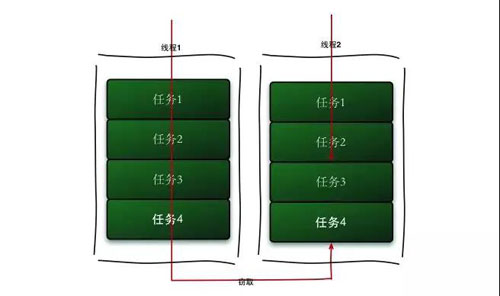
网上这个框架的例子很多,我们看看如何使用代码完成我们上面的下订单需求:
public class OrderTask extends RecursiveTask<OrderInfo> {
@Override
protected OrderInfo compute() {
System.out.println("执行"+ this.getClass().getSimpleName() + "线程名字为:" + Thread.currentThread().getName());
// 定义其他五种并行TasK
CustomerTask customerTask = new CustomerTask();
TenantTask tenantTask = new TenantTask();
DiscountTask discountTask = new DiscountTask();
FoodTask foodTask = new FoodTask();
OtherTask otherTask = new OtherTask();
invokeAll(customerTask, tenantTask, discountTask, foodTask, otherTask);
OrderInfo orderInfo = new OrderInfo(customerTask.join(), tenantTask.join(), discountTask.join(), foodTask.join(), otherTask.join());
return orderInfo;
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool(Runtime.getRuntime().availableProcessors() -1 );
System.out.println(forkJoinPool.invoke(new OrderTask()));
}
}
class CustomerTask extends RecursiveTask<CustomerInfo>{
@Override
protected CustomerInfo compute() {
System.out.println("执行"+ this.getClass().getSimpleName() + "线程名字为:" + Thread.currentThread().getName());
return new CustomerInfo();
}
}
class TenantTask extends RecursiveTask<TenantInfo>{
@Override
protected TenantInfo compute() {
System.out.println("执行"+ this.getClass().getSimpleName() + "线程名字为:" + Thread.currentThread().getName());
return new TenantInfo();
}
}
class DiscountTask extends RecursiveTask<DiscountInfo>{
@Override
protected DiscountInfo compute() {
System.out.println("执行"+ this.getClass().getSimpleName() + "线程名字为:" + Thread.currentThread().getName());
return new DiscountInfo();
}
}
class FoodTask extends RecursiveTask<FoodListInfo>{
@Override
protected FoodListInfo compute() {
System.out.println("执行"+ this.getClass().getSimpleName() + "线程名字为:" + Thread.currentThread().getName());
return new FoodListInfo();
}
}
class OtherTask extends RecursiveTask<OtherInfo>{
@Override
protected OtherInfo compute() {
System.out.println("执行"+ this.getClass().getSimpleName() + "线程名字为:" + Thread.currentThread().getName());
return new OtherInfo();
}
}
我们定义一个 Order Task 并且定义五个获取信息的任务,在 Compute 中分别 Fork 执行这五个任务,最后在将这五个任务的结果通过 Join 获得,最后完成我们的并行化的需求。
parallelStream
在 JDK 1.8 中提供了并行流的 API,当我们使用集合的时候能很好的进行并行处理。
下面举了一个简单的例子从 1 加到 100:
public class ParallelStream {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<Integer>();
for (int i = 1; i <= 100; i++) {
list.add(i);
}
LongAdder sum = new LongAdder();
list.parallelStream().forEach(integer -> {
// System.out.println("当前线程" + Thread.currentThread().getName());
sum.add(integer);
});
System.out.println(sum);
}
}
parallelStream 中底层使用的那一套也是 Fork/Join 的那一套,默认的并发程度是可用 CPU 数 -1。
分片
可以想象有这么一个需求,每天定时对 ID 在某个范围之间的用户发券,比如这个范围之间的用户有几百万,如果给一台机器发的话,可能全部发完需要很久的时间。
所以分布式调度框架比如:elastic-job 都提供了分片的功能,比如你用 50 台机器,那么 id%50 = 0 的在第 0 台机器上;=1 的在第 1 台机器上发券,那么我们的执行时间其实就分摊到了不同的机器上了。
并行化注意事项
线程安全:在 parallelStream 中我们列举的代码中使用的是 LongAdder,并没有直接使用我们的 Integer 和 Long,这个是因为在多线程环境下 Integer 和 Long 线程不安全。所以线程安全我们需要特别注意。
合理参数配置:可以看见我们需要配置的参数比较多,比如我们的线程池的大小,等待队列大小,并行度大小以及我们的等待超时时间等等。
我们都需要根据自己的业务不断的调优防止出现队列不够用或者超时时间不合理等等。
上面介绍了什么是并行化,并行化的各种历史,在 Java 中如何实现并行化,以及并行化的注意事项。希望大家对并行化有个比较全面的认识。
最后给大家提个两个小问题:
- 在我们并行化当中有某个任务如果某个任务出现了异常应该怎么办?
- 在我们并行化当中有某个任务的信息并不是强依赖,也就是如果出现了问题这部分信息我们也可以不需要,当并行化的时候,这种任务出现了异常应该怎么办?

正文到此结束
- 本文标签: cat API CTO 参数 同步 core 处理器 长连接 CountDownLatch tab 管理 CEO 快的 dubbo src queue Struts2 ArrayList 源码 线程 IDE 空间 list 开源 client 线程池 IO 本质 并发 web 数据库 数据 创始人 value setTimeout build Job NIO 模型 类图 apache tar UI 时间 XML final schema ACE 图片 高并发 stream java 配置 需求 遍历 锁 Connection http executor 分布式 QPS spring https map 代码 程序员 并发编程 ThreadPoolExecutor ask cache id Reactor servlet 安全 多线程 App 开发 Developer 统计 Service 希望 缓存 db
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

