Shading-jdbc源码分析-sql词法解析
前有芋艿大佬已经发过相关分析的文章,自己觉的源码总归要看一下,然后看了就要记录下来(记性很差...),所以就有了这篇文章(以后还要继续更:smile:) ,希望我们都能在看过文章后能够有不一样的收获。
声明:本文基于1.5.M1版本
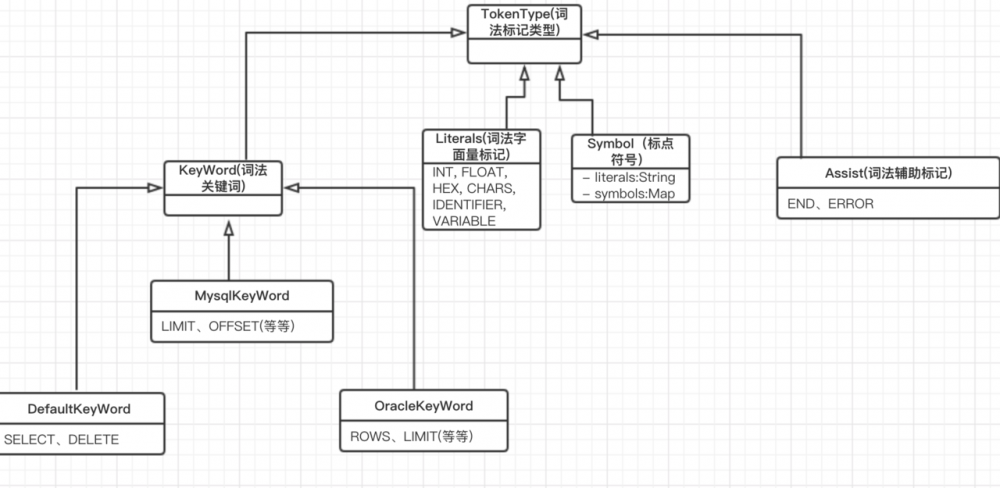
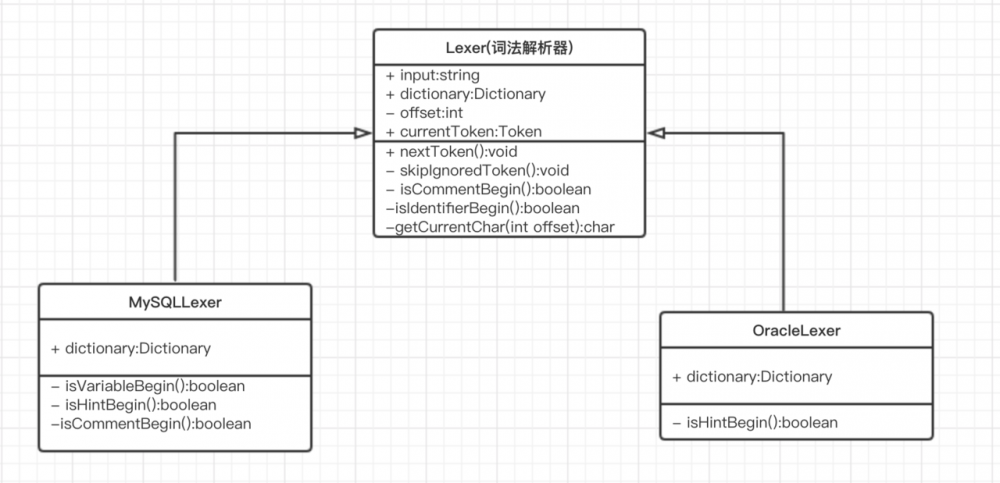
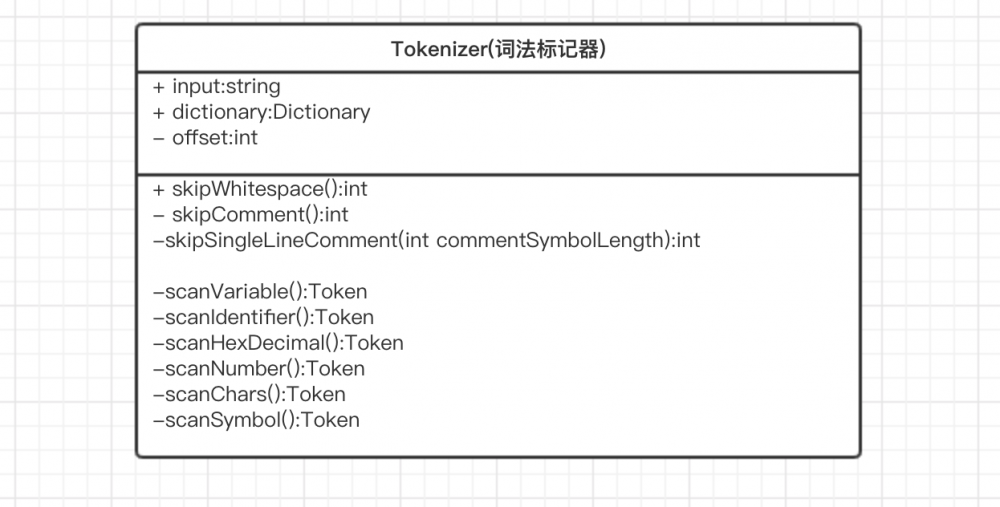
相关的UML类图

解析:
首先我们来看下解析sql的过程中用到的类做一个解释:
- TokenType:衍生了多个子类,用来标记sql拆分过程中,每个被拆分的词的类型(比如select属于KeyWord,";"属于Symbol)
- Lexer:sql具体的解析类,通过调用nextToken()方法分析sql每个词的类型;
- Tokenizer:具体的标记类,标记具体的词,配合Lexer的nextToken()方法使用
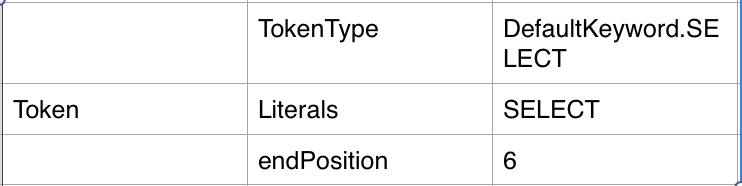
- Token:标记后的结果,type:具体的词类型、literals:具体的词、endPosition:这个词在sql中的最后位置(index)
@Test
public void assertNextTokenForOrderBy() {
Lexer lexer = new Lexer("SELECT * FROM ORDER ORDER /t BY XX DESC", dictionary);
//lexer.nextToken();
LexerAssert.assertNextToken(lexer, DefaultKeyword.SELECT, "SELECT");
//lexer.nextToken();
LexerAssert.assertNextToken(lexer, Symbol.STAR, "*");
//lexer.nextToken();
LexerAssert.assertNextToken(lexer, DefaultKeyword.FROM, "FROM");
//lexer.nextToken();
LexerAssert.assertNextToken(lexer, Literals.IDENTIFIER, "ORDER");
//lexer.nextToken();
LexerAssert.assertNextToken(lexer, DefaultKeyword.ORDER, "ORDER");
//lexer.nextToken();
LexerAssert.assertNextToken(lexer, DefaultKeyword.BY, "BY");
//lexer.nextToken();
LexerAssert.assertNextToken(lexer, Literals.IDENTIFIER, "XX");
//lexer.nextToken();
LexerAssert.assertNextToken(lexer, DefaultKeyword.DESC, "DESC");
//lexer.nextToken();
LexerAssert.assertNextToken(lexer, Assist.END, "");
}
复制代码
上面是项目中的一段测试用例,我们以这个用例来分析。
- 第一次调用nextToken()
/**
* 分析下一个词法标记.
*/
public final void nextToken() {
skipIgnoredToken();
if (isVariableBegin()) {
currentToken = new Tokenizer(input, dictionary, offset).scanVariable();
} else if (isNCharBegin()) {
currentToken = new Tokenizer(input, dictionary, ++offset).scanChars();
} else if (isIdentifierBegin()) {
currentToken = new Tokenizer(input, dictionary, offset).scanIdentifier();
} else if (isHexDecimalBegin()) {
currentToken = new Tokenizer(input, dictionary, offset).scanHexDecimal();
} else if (isNumberBegin()) {
currentToken = new Tokenizer(input, dictionary, offset).scanNumber();
} else if (isSymbolBegin()) {
currentToken = new Tokenizer(input, dictionary, offset).scanSymbol();
} else if (isCharsBegin()) {
currentToken = new Tokenizer(input, dictionary, offset).scanChars();
} else if (isEnd()) {
currentToken = new Token(Assist.END, "", offset);
} else {
currentToken = new Token(Assist.ERROR, "", offset);
}
offset = currentToken.getEndPosition();
}
复制代码
- 先走skipIgnoredToken();
- 跳过空格
- 跳过以/*!开头的(Mysql是这样)的字符,对于不同数据库。isHintBegin实现了不同的处理
- 跳过注释
private void skipIgnoredToken() {
offset = new Tokenizer(input, dictionary, offset).skipWhitespace();
while (isHintBegin()) {
offset = new Tokenizer(input, dictionary, offset).skipHint();
offset = new Tokenizer(input, dictionary, offset).skipWhitespace();
}
while (isCommentBegin()) {
offset = new Tokenizer(input, dictionary, offset).skipComment();
offset = new Tokenizer(input, dictionary, offset).skipWhitespace();
}
}
复制代码
这里我们以跳过空格为例来展开说明:
从传入的offset标志位开始,循环判断sql语句中对应位置的字符是不是空格,直到不是空格就退出,返回最新位置的offset
/**
* 跳过空格.
*
* @return 跳过空格后的偏移量
*/
public int skipWhitespace() {
int length = 0;
while (CharType.isWhitespace(charAt(offset + length))) {
length++;
}
return offset + length;
}
private char charAt(final int index) {
return index >= input.length() ? (char) CharType.EOI : input.charAt(index);
}
/**
* 判断是否为空格.
*
* @param ch 待判断的字符
* @return 是否为空格
*/
public static boolean isWhitespace(final char ch) {
return ch <= 32 && EOI != ch || 160 == ch || ch >= 0x7F && ch <= 0xA0;
}
复制代码
- 第二步 从最新位置的offset开始,继续判断是否是变量,这里以mysql为例,开始的单词是‘SELECT’,所以进入第三步
/**
这是mysql的实现
**/
@Override
protected boolean isVariableBegin() {
return '@' == getCurrentChar(0);
}
复制代码
- 第三步 判断是否是NChar,false,进入第四步
private boolean isNCharBegin() {
return isSupportNChars() && 'N' == getCurrentChar(0) && '/'' == getCurrentChar(1);
}
复制代码
- 第四步 判断是否是标识符 true
- 扫描标识符
- 循环判断当前的标识符是不是字符,直到不是字符
- 截取这个字符串
- 判断是否是双关词汇(group、order)
- 如果4符合,则进一步做特殊处理
- 构造Token返回
private boolean isIdentifierBegin() {
return isIdentifierBegin(getCurrentChar(0));
}
private boolean isIdentifierBegin(final char ch) {
return CharType.isAlphabet(ch) || '`' == ch || '_' == ch || '$' == ch;
}
/**
* 判断是否为字母.
*
* @param ch 待判断的字符
* @return 是否为字母
*/
public static boolean isAlphabet(final char ch) {
return ch >= 'A' && ch <= 'Z' || ch >= 'a' && ch <= 'z';
}
复制代码
/**
* 扫描标识符.
*
* @return 标识符标记
*/
public Token scanIdentifier() {
if ('`' == charAt(offset)) {
int length = getLengthUntilTerminatedChar('`');
return new Token(Literals.IDENTIFIER, input.substring(offset, offset + length), offset + length);
}
int length = 0;
while (isIdentifierChar(charAt(offset + length))) {
length++;
}
String literals = input.substring(offset, offset + length);
if (isAmbiguousIdentifier(literals)) {
return new Token(processAmbiguousIdentifier(offset + length, literals), literals, offset + length);
}
return new Token(dictionary.findTokenType(literals, Literals.IDENTIFIER), literals, offset + length);
}
复制代码
- 返回最终的Token,赋值给currentToken,更新offset,此时的Token内容如下。第一个 “SELECT” 就解析出来了,后面的单词继续调用nextToken(),方法差不多,区别就是词法的类型不一样,走的判断可能逻辑会不同,后面有兴趣的可以自己跟着代码去看看。
最后
小尾巴走一波,欢迎关注我的公众号,不定期分享编程、投资、生活方面的感悟:)

正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

