Java并发编程(5)- J.U.C之AQS及其相关组件详解
J.U.C之AQS-介绍
Java并发包(JUC)中提供了很多并发工具,这其中,很多我们耳熟能详的并发工具,譬如ReentrangLock、Semaphore,而它们的实现都用到了一个共同的基类--AbstractQueuedSynchronizer(抽象队列同步器),简称AQS。
AQS是JDK提供的一套用于实现基于FIFO等待队列的阻塞锁和相关的同步器的一个同步框架,它使用一个int类型的volatile变量(命名为state)来维护同步状态,通过内置的FIFO队列来完成资源获取线程的排队工作。
AbstractQueuedSynchronizer中对state的操作是原子的,且不能被继承。所有的同步机制的实现均依赖于对改变量的原子操作。为了实现不同的同步机制,我们需要创建一个非共有的(non-public internal)扩展了AQS类的内部辅助类来实现相应的同步逻辑。
AbstractQueuedSynchronizer并不实现任何同步接口,它提供了一些可以被具体实现类直接调用的一些原子操作方法来重写相应的同步逻辑。AQS同时提供了独占模式(exclusive)和共享模式(shared)两种不同的同步逻辑。一般情况下,子类只需要根据需求实现其中一种模式,当然也有同时实现两种模式的同步类,如ReadWriteLock。
使用AQS能简单且高效地构造出应用广泛的大量的同步器,比如我们提到的ReentrantLock,Semaphore,其他的诸如ReentrantReadWriteLock,SynchronousQueue,FutureTask等等皆是基于AQS的。
当然,我们自己也能利用AQS非常轻松容易地构造出符合我们自己需求的同步器,由此可知AQS是Java并发包中最为核心的一个基类。
AbstractQueuedSynchronizer底层数据结构是一个双向链表,属于队列的一种实现:
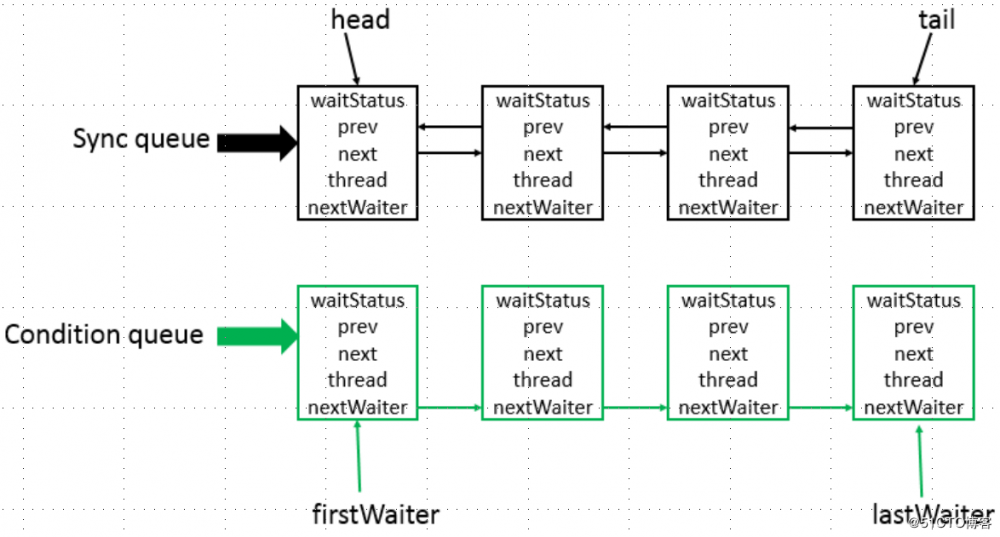
- sync queue:同步队列,其中head节点主要负责后面的调度
- Condition queue:单向链表,不是必须的,只有程序中使用到Condition的时候才会存在,可能会有多个Condition queue
关于AQS里的state状态:
我们提到了AbstractQueuedSynchronizer维护了一个volatile int类型的变量,命名为state,用于表示当前同步状态。volatile虽然不能保证操作的原子性,但是保证了当前变量state的可见性。state的访问方式有三种:
getState() setState() compareAndSetState()
这三种操作均是原子操作,其中compareAndSetState的实现依赖于Unsafe的compareAndSwapInt()方法。
关于自定义资源共享方式:
AQS支持两种资源共享方式:Exclusive(独占,只有一个线程能执行,如ReentrantLock)和Share(共享,多个线程可同时执行,如Semaphore/CountDownLatch)。这样方便使用者实现不同类型的同步组件,独占式如ReentrantLock,共享式如Semaphore,CountDownLatch,组合式的如ReentrantReadWriteLock。总之,AQS为使用提供了底层支撑,如何组装实现,使用者可以自由发挥。
关于同步器设计:
同步器的设计是基于模板方法模式的,一般的使用方式是这样:
- 使用者继承AbstractQueuedSynchronizer并重写指定的方法。(这些重写方法很简单,无非是对于共享资源state的获取和释放)
- 将AQS组合在自定义同步组件的实现中,并调用其模板方法,而这些模板方法会调用使用者重写的方法。这其实是模板方法模式的一个很经典的应用。
不同的自定义同步器争用共享资源的方式也不同。自定义同步器在实现时只需要实现共享资源state的获取与释放方式即可,至于具体线程等待队列的维护(如获取资源失败入队/唤醒出队等),AQS已经在底层实现好了。自定义同步器实现时主要实现以下几种方法:
protected boolean isHeldExclusively() // 该线程是否正在独占资源。只有用到condition才需要去实现它。 protected boolean tryAcquire(int) // 独占方式。尝试获取资源,成功则返回true,失败则返回false。 protected boolean tryRelease(int) // 独占方式。尝试释放资源,成功则返回true,失败则返回false。 protected int tryAcquireShared(int) // 共享方式。尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。 protected boolean tryReleaseShared(int) // 共享方式。尝试释放资源,如果释放后允许唤醒后续等待结点返回true,否则返回false。
如何使用:
首先,我们需要去继承AbstractQueuedSynchronizer这个类,然后我们根据我们的需求去重写相应的方法,比如要实现一个独占锁,那就去重写tryAcquire,tryRelease方法,要实现共享锁,就去重写tryAcquireShared,tryReleaseShared;最后,在我们的组件中调用AQS中的模板方法就可以了,而这些模板方法是会调用到我们之前重写的那些方法的。也就是说,我们只需要很小的工作量就可以实现自己的同步组件,重写的那些方法,仅仅是一些简单的对于共享资源state的获取和释放操作,至于像是获取资源失败,线程需要阻塞之类的操作,自然是AQS帮我们完成了。
具体实现的思路:
- 首先AQS内部维护了一个CLH队列,来管理锁
- 线程尝试获取锁,如果获取失败,则将等待信息等包装成一个Node结点,加入到同步队列Sync queue里
- 不断重新尝试获取锁(当前结点为head的直接后继才会尝试),如果获取失败,则会阻塞自己,直到被唤醒
- 当持有锁的线程释放锁的时候,会唤醒队列中的后继线程
设计思想:
对于使用者来讲,我们无需关心获取资源失败,线程排队,线程阻塞/唤醒等一系列复杂的实现,这些都在AQS中为我们处理好了。我们只需要负责好自己的那个环节就好,也就是获取/释放共享资源state的姿势。很经典的模板方法设计模式的应用,AQS为我们定义好顶级逻辑的骨架,并提取出公用的线程入队列/出队列,阻塞/唤醒等一系列复杂逻辑的实现,将部分简单的可由使用者决定的操作逻辑延迟到子类中去实现即可。
基于AQS的同步组件:
- CountDownLatch
- Semaphore
- CyclicBarrier
- ReentrantLock
- Condition
- FutureTask
AQS小结:
- 使用Node实现FIFO队列,可以用于构建锁或者其他同步装置的基础框架
- 利用了一个int类型表示状态,有一个state的成员变量,表示获取锁的线程数(0没有线程获取锁,1有线程获取锁,大于1表示重入锁的数量),和一个同步组件ReentrantLock。状态信息通过procted级别的getState,setState,compareAndSetState进行操作
- 使用方法是继承,然后复写AQS中的方法,基于模板方法模式
- 子类通过继承并通过实现它的方法管理其状态{acquire和release}的方法操作状态
- 可以同时实现排它锁和共享锁的模式(独占、共享)
CountDownLatch
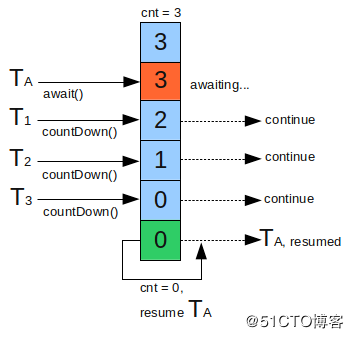
CountDownLatch是一个同步工具类,它允许一个或多个线程一直等待,直到其他线程执行完后再执行。例如,应用程序的主线程希望在负责启动框架服务的线程已经启动所有框架服务之后执行。
CountDownLatch是通过一个计数器来实现的,计数器的初始化值为线程的数量。每当一个线程完成了自己的任务后,计数器的值就相应得减1。当计数器到达0时,表示所有的线程都已完成任务,然后在闭锁上等待的线程就可以恢复执行任务。
CountDownLatch的构造函数源码如下:
/**
* Constructs a {@code CountDownLatch} initialized with the given count.
*
* @param count the number of times {@link #countDown} must be invoked
* before threads can pass through {@link #await}
* @throws IllegalArgumentException if {@code count} is negative
*/
public CountDownLatch(int count) {
if (count < 0) throw new IllegalArgumentException("count < 0");
this.sync = new Sync(count);
}
计数器count是闭锁需要等待的线程数量,只能被设置一次,且CountDownLatch没有提供任何机制去重新设置计数器count。
与CountDownLatch的第一次交互是主线程等待其他线程。主线程必须在启动其他线程后立即调用CountDownLatch.await()方法。这样主线程的操作就会在这个方法上阻塞,直到其他线程完成各自的任务。
其他N个线程必须引用CountDownLatch闭锁对象,因为它们需要通知CountDownLatch对象,它们各自完成了任务;这种通知机制是通过CountDownLatch.countDown()方法来完成的;每调用一次,count的值就减1,因此当N个线程都调用这个方法,count的值就等于0,然后主线程就可以通过await()方法,恢复执行自己的任务。
注:该计数器的操作是原子性的
CountDownLatch使用场景:
- 实现最大的并行性:有时我们想同时启动多个线程,实现最大程度的并行性。例如,我们想测试一个单例类。如果我们创建一个初始计数器为1的CountDownLatch,并让其他所有线程都在这个锁上等待,只需要调用一次countDown()方法就可以让其他所有等待的线程同时恢复执行。
- 开始执行前等待N个线程完成各自任务:例如应用程序启动类要确保在处理用户请求前,所有N个外部系统都已经启动和运行了。
- 死锁检测:一个非常方便的使用场景是你用N个线程去访问共享资源,在每个测试阶段线程数量不同,并尝试产生死锁。
使用示例
1.基本用法:
@Slf4j
public class CountDownLatchExample1 {
private final static int THREAD_COUNT = 200;
public static void main(String[] args) throws InterruptedException {
ExecutorService exec = Executors.newCachedThreadPool();
final CountDownLatch countDownLatch = new CountDownLatch(THREAD_COUNT);
for (int i = 0; i < THREAD_COUNT; i++) {
final int threadNum = i;
exec.execute(() -> {
try {
test(threadNum);
} catch (InterruptedException e) {
log.error("", e);
} finally {
// 为防止出现异常,放在finally更保险一些
countDownLatch.countDown();
}
});
}
countDownLatch.await();
log.info("finish");
exec.shutdown();
}
private static void test(int threadNum) throws InterruptedException {
TimeUnit.MILLISECONDS.sleep(100);
log.info("{}", threadNum);
TimeUnit.MILLISECONDS.sleep(100);
}
}
2.比如有多个线程完成一个任务,但是这个任务只想给它一个指定的时间,超过这个任务就不继续等待了,完成多少算多少:
// 等待指定的时间 参数1:等待时间,参数2:时间单位 countDownLatch.await(10, TimeUnit.MILLISECONDS);
关于CountDownLatch的其他例子可以参考我另一篇文章:
- CountDownLatch类的使用
Semaphore
Semaphore(信号量)是用来控制同时访问特定资源的线程数量,它通过协调各个线程,以保证合理的使用公共资源。很多年以来,我都觉得从字面上很难理解Semaphore所表达的含义,只能把它比作是控制流量的红绿灯,比如XX马路要限制流量,只允许同时有一百辆车在这条路上行使,其他的都必须在路口等待,所以前一百辆车会看到绿灯,可以开进这条马路,后面的车会看到红灯,不能驶入XX马路,但是如果前一百辆中有五辆车已经离开了XX马路,那么后面就允许有5辆车驶入马路,这个例子里说的车就是线程,驶入马路就表示线程在执行,离开马路就表示线程执行完成,看见红灯就表示线程被阻塞,不能执行。
所以简单来说,Semaphore主要作用就是可以控制同一时间并发执行的线程数。Semaphore有两个构造函数,参数permits表示许可数,它最后传递给了AQS的state值。线程在运行时首先获取许可,如果成功,许可数就减1,线程运行,当线程运行结束就释放许可,许可数就加1。如果许可数为0,则获取失败,线程位于AQS的等待队列中,它会被其它释放许可的线程唤醒。在创建Semaphore对象的时候还可以指定它的公平性。一般常用非公平的信号量,非公平信号量是指在获取许可时先尝试获取许可,而不必关心是否已有需要获取许可的线程位于等待队列中,如果获取失败,才会入列。而公平的信号量在获取许可时首先要查看等待队列中是否已有线程,如果有则入列。
使用场景:
Semaphore可以用于做流量控制,特别公用资源有限的应用场景,比如数据库连接。假如有一个需求,要读取几万个文件的数据,因为都是IO密集型任务,我们可以启动几十个线程并发的读取,但是如果读到内存后,还需要存储到数据库中,而数据库的连接数只有10个,这时我们必须控制只有十个线程同时获取数据库连接保存数据,否则会报错无法获取数据库连接。这个时候,我们就可以使用Semaphore来做流控。
使用示例
1.每次获取1个许可示例:
public class SemaphoreExample1 {
private final static int THREAD_COUNT = 200;
public static void main(String[] args) {
ExecutorService exec = Executors.newCachedThreadPool();
final Semaphore semaphore = new Semaphore(10);
for (int i = 0; i < THREAD_COUNT; i++) {
final int threadNum = i;
exec.execute(() -> {
try {
// 获取一个许可
semaphore.acquire();
System.out.println(threadNum);
// 释放一个许可
semaphore.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
exec.shutdown();
}
}
在代码中,虽然有200个线程在执行,但是只允许10个并发的执行。Semaphore的构造方法 Semaphore(int permits) 接收一个整型的数字,表示可用的许可证数量。所以 Semaphore(10) 表示允许10个线程获取许可证,也就是最大并发数是10。Semaphore的用法也很简单,首先线程使用Semaphore的 acquire() 获取一个许可证,使用完之后调用 release() 归还许可证。还可以用 tryAcquire() 方法尝试获取许可证。
2.如何希望每次获取多个许可的话,只需要在 acquire() 方法的参数中进行指定即可,如下示例:
// 获取多个许可 semaphore.acquire(3); System.out.println(threadNum); // 释放多个许可 semaphore.release(3);
3.当并发很高,想要超过允许的并发数之后,就丢弃不处理的话,可以使用Semaphore里的 tryAcquire() 方法尝试获取许可,该方法返回boolean类型的值,我们可以通过判断这个值来抛弃超过并发数的请求。如下示例:
public class SemaphoreExample3 {
private final static int THREAD_COUNT = 200;
public static void main(String[] args) {
ExecutorService exec = Executors.newCachedThreadPool();
final Semaphore semaphore = new Semaphore(10);
for (int i = 0; i < THREAD_COUNT; i++) {
final int threadNum = i;
exec.execute(() -> {
try {
// 尝试获取一个许可,若没有获取到许可的线程就会被抛弃,而不是阻塞
if (semaphore.tryAcquire()) {
System.out.println(threadNum);
// 释放一个许可
semaphore.release();
}
} catch (Exception e) {
e.printStackTrace();
}
});
}
exec.shutdown();
}
}
Semaphore中尝试获取许可的相关方法:
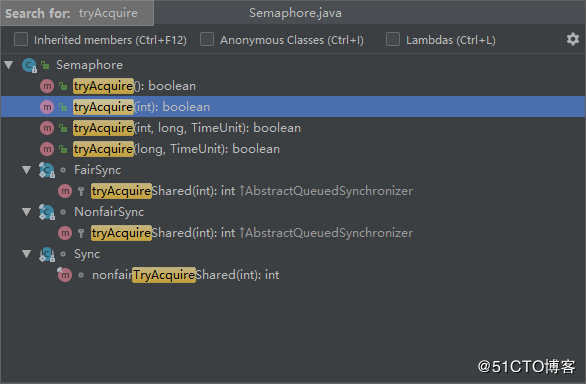
我们可以指定尝试获取许可的超时时间,例如我设置超时时间为1秒:
// 尝试获取一个许可,直到超过一秒
if (semaphore.tryAcquire(1, TimeUnit.SECONDS)) {
System.out.println(threadNum);
// 释放一个许可
semaphore.release();
}
除此之外,还可以尝试获取多个许可,并且指定超时时间:
// 尝试获取多个许可,直到超过一秒
if (semaphore.tryAcquire(3, 1, TimeUnit.SECONDS)) {
System.out.println(threadNum);
// 释放多个许可
semaphore.release(3);
}
Semaphore中其他一些常用的方法:
int availablePermits() // 返回此信号量中当前可用的许可证数。 int getQueueLength() // 返回正在等待获取许可证的线程数。 boolean hasQueuedThreads() // 是否有线程正在等待获取许可证。 void reducePermits(int reduction) // 减少reduction个许可证。是个protected方法。 Collection getQueuedThreads() // 返回所有等待获取许可证的线程集合。是个protected方法。
CyclicBarrier
CyclicBarrier 的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续干活。当某个线程调用了await方法之后,就会进入等待状态,并将计数器-1,直到所有线程调用await方法使计数器为0,才可以继续执行,由于计数器可以重复使用,所以我们又叫他循环屏障。CyclicBarrier默认的构造方法是CyclicBarrier(int parties),其参数表示屏障拦截的线程数量,每个线程调用await方法告诉CyclicBarrier我已经到达了屏障,然后当前线程被阻塞。
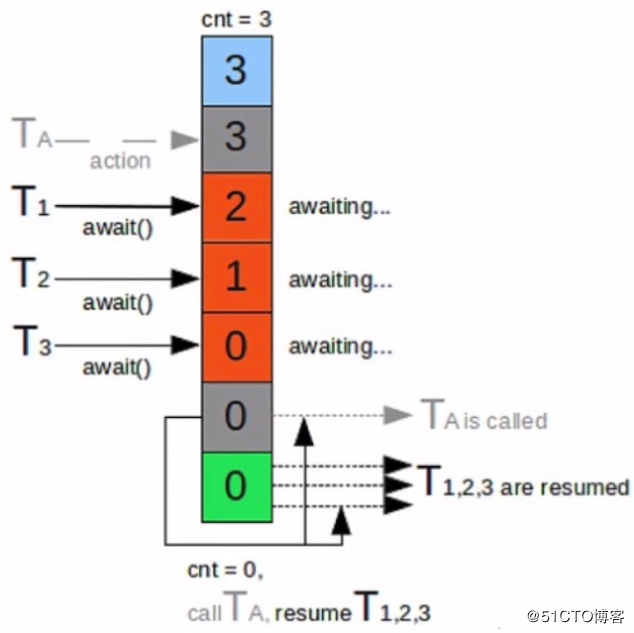
CyclicBarrier的应用场景:
CyclicBarrier可以用于多线程计算数据,最后合并计算结果的应用场景。比如我们用一个Excel保存了用户所有银行流水,每个Sheet保存一个帐户近一年的每笔银行流水,现在需要统计用户的日均银行流水,先用多线程处理每个sheet里的银行流水,都执行完之后,得到每个sheet的日均银行流水,最后,再用barrierAction用这些线程的计算结果,计算出整个Excel的日均银行流水。
CyclicBarrier和CountDownLatch的区别:
- CountDownLatch的计数器只能使用一次。而CyclicBarrier的计数器可以使用reset() 方法重置。所以CyclicBarrier能处理更为复杂的业务场景,比如如果计算发生错误,可以重置计数器,并让线程们重新执行一次。
- CountDownLatch主要用于实现一个或n个线程需要等待其他线程完成某项操作之后,才能继续往下执行,描述的是一个或n个线程等待其他线程的关系,而CyclicBarrier是多个线程相互等待,知道满足条件以后再一起往下执行。描述的是多个线程相互等待的场景
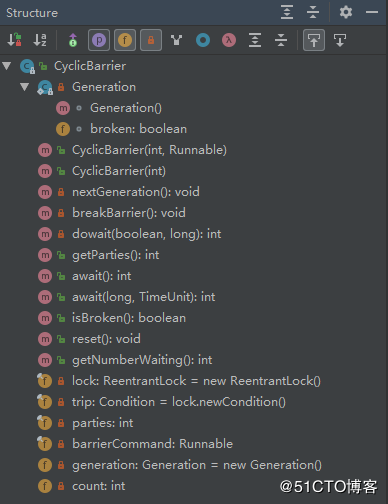
- CyclicBarrier还提供其他有用的方法,比如getNumberWaiting方法可以获得CyclicBarrier阻塞的线程数量。isBroken方法用来知道阻塞的线程是否被中断。
CyclicBarrier方法列表:
使用示例
1.基本使用:
@Slf4j
public class CyclicBarrierExample1 {
// 给定一个值,说明有多少个线程同步等待
private static CyclicBarrier barrier = new CyclicBarrier(5);
public static void main(String[] args) throws InterruptedException {
ExecutorService exec = Executors.newCachedThreadPool();
for (int i = 0; i < 10; i++) {
final int num = i;
// 延迟1秒,方便观察
Thread.sleep(1000);
exec.execute(() -> {
try {
CyclicBarrierExample1.race(num);
} catch (Exception e) {
log.error("", e);
}
});
}
exec.shutdown();
}
private static void race(int num) throws Exception {
Thread.sleep(1000);
log.info("{} is ready", num);
// 阻塞线程
barrier.await();
log.info("{} continue", num);
}
}
以防await无限阻塞进程,我们可以设置await的超时时间,修改race方法代码如下:
private static void race(int num) throws Exception {
Thread.sleep(1000);
log.info("{} is ready", num);
try {
// 由于设置了超时时间后阻塞的线程可能会被中断,抛出BarrierException异常,如果想继续往下执行,需要加上try-catch
barrier.await(2000, TimeUnit.MILLISECONDS);
} catch (InterruptedException | TimeoutException | BrokenBarrierException e) {
// isBroken方法用来知道阻塞的线程是否被中断
log.warn("exception occurred {} {}. isBroken : {}", e.getClass().getName(), e.getMessage(), barrier.isBroken());
}
log.info("{} continue", num);
}
如果希望当所有线程到达屏障后就执行一个runnable的话,可以使用 CyclicBarrier(int parties, Runnable barrierAction) 构造函数传递一个runnable实例。如下示例:
/**
* 当线程全部到达屏障时,优先执行这里传入的runnable
*/
private static CyclicBarrier barrier = new CyclicBarrier(5, () -> log.info("callback is running"));
ReentrantLock
在Java里一共有两类锁,一类是synchornized同步锁,还有一种是JUC里提供的锁Lock,Lock是个接口,其核心实现类就是ReentrantLock。
synchornized与ReentrantLock的区别对比如下表:
| 对比维度 | synchornized | ReentrantLock |
|---|---|---|
| 可重入性(线程进入锁的时候计数器就自增1,计数器下降为0则会释放锁) | 可重入 | 可重入 |
| 锁的实现 | JVM实现,很难操作源码 | JDK实现,可以观察其源码 |
| 性能 | 在引入偏向锁、轻量级锁/自旋锁后性能大大提升,官方建议无特殊要求时尽量使用synchornized,并且新版本的一些jdk源码都由之前的ReentrantLock改成了synchornized | 与优化后的synchornized相差不大 |
| 功能区别 | 方便简洁,由编译器负责加锁和释放锁 | 需手工操作锁的加锁和释放 |
| 锁粒度 | 粗粒度,不灵活 | 细粒度,可灵活控制 |
| 可否指定公平锁 | 不可以 | 可以 |
| 可否放弃锁 | 不可以 | 可以 |
ReentrantLock实现:
- 采用自旋锁,循环调用CAS操作来实现加锁,避免了使线程进入内核态的阻塞状态。想尽办法避免线程进入内核态的阻塞状态,是我们分析和理解锁设计的关键钥匙。
ReentrantLock独有的功能:
lock.lockInterruptibly()
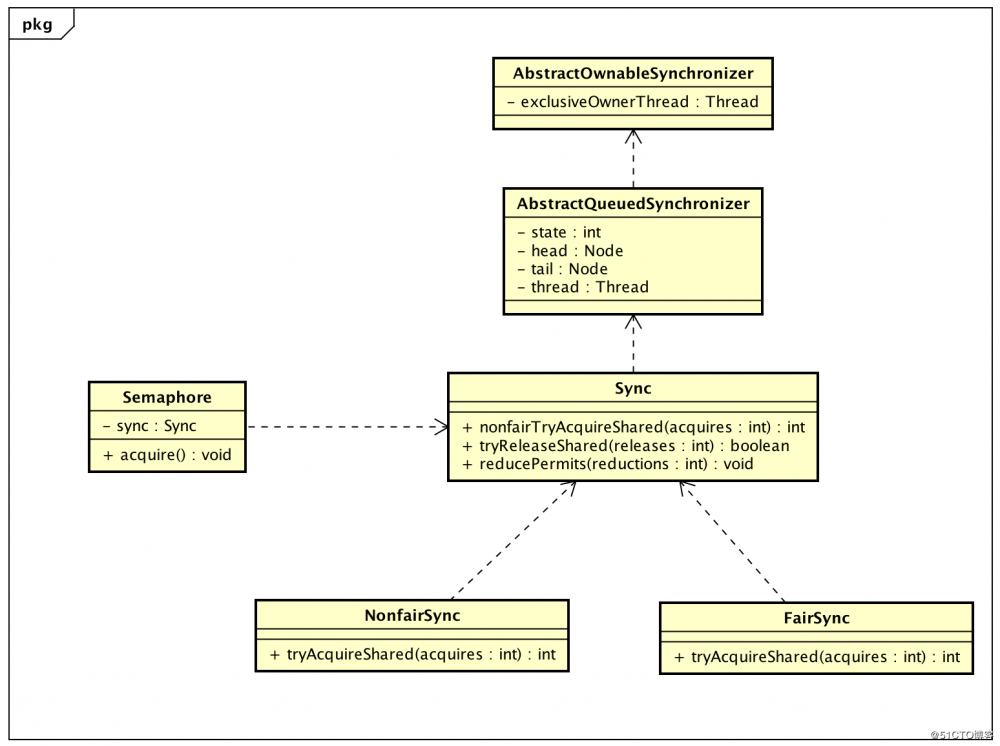
在ReentrantLock中,对于公平和非公平的定义是通过对同步器AQS的扩展加以实现的,也就是在tryAcquire的实现上做了语义的控制。
这里提到一个锁获取的公平性问题,如果在绝对时间上,先对锁进行获取的请求一定被先满足,那么这个锁是公平的,反之,是不公平的,也就是说等待时间最长的线程最有机会获取锁,也可以说锁的获取是有序的。ReentrantLock这个锁提供了一个构造函数,能够控制这个锁是否是公平的。
而锁的名字也是说明了这个锁具备了重复进入的可能,也就是说能够让当前线程多次的进行对锁的获取操作,这样的最大次数限制是 Integer.MAX_VALUE ,约21亿次左右。
事实上公平的锁机制往往没有非公平的效率高,因为公平的获取锁没有考虑到操作系统对线程的调度因素,这样造成JVM对于等待中的线程调度次序和操作系统对线程的调度之间的不匹配。对于锁的快速且重复的获取过程中,连续获取的概率是非常高的,而公平锁会压制这种情况,虽然公平性得以保障,但是响应比却下降了,但是并不是任何场景都是以TPS作为唯一指标的,因为公平锁能够减少“饥饿”发生的概率,等待越久的请求越是能够得到优先满足。
要放弃synchronized?
从上边的介绍,看上去ReentrantLock不仅拥有synchronized的所有功能,而且有一些功能synchronized无法实现的特性。性能方面,ReentrantLock也不比synchronized差,那么到底我们要不要放弃使用synchronized呢?答案是不要这样做。
J.U.C包中的锁定类是用于高级情况和高级用户的工具,除非说你对Lock的高级特性有特别清楚的了解以及有明确的需要,或这有明确的证据表明同步已经成为可伸缩性的瓶颈的时候,否则我们还是继续使用synchronized。相比较这些高级的锁定类,synchronized还是有一些优势的,比如synchronized不可能忘记释放锁。还有当JVM使用synchronized管理锁定请求和释放时,JVM在生成线程转储时能够包括锁定信息,这些信息对调试非常有价值,它们可以标识死锁以及其他异常行为的来源。
如何选择锁:
- 若业务逻辑需使用到锁的高级功能去实现,那么就可以选择ReentrantLock
- 需要细粒度操作锁时,选择ReentrantLock
- 对ReentrantLock的机制很了解,有足够经验能够避免死锁的出现的开发者,可以选择ReentrantLock,不建议对锁机制不是很熟悉的开发者使用ReentrantLock
- 对锁的需求较简单,使用synchornized
- 初级开发者建议使用synchornized
使用示例
基本使用:
@Slf4j
public class LockExample2 {
/**
* 请求总数
*/
public static int clientTotal = 5000;
/**
* 同时并发执行的线程数量
*/
public static int threadTotal = 200;
/**
* 计数
*/
private static int count = 0;
/**
* 锁对象,默认是使用非公平锁,可以传入true和false来决定使用公平所还是非公平锁
*/
private final static Lock LOCK = new ReentrantLock();
public static void main(String[] args) throws InterruptedException {
ExecutorService executorService = Executors.newCachedThreadPool();
Semaphore semaphore = new Semaphore(threadTotal);
CountDownLatch countDownLatch = new CountDownLatch(clientTotal);
for (int i = 0; i < clientTotal; i++) {
executorService.execute(() -> {
try {
// 从信号量获取执行许可,若并发达到设定的数量,那么就不会获取到许可,将会阻塞当前线程,直到能够获取到执行许可为止
semaphore.acquire();
LockExample2.add();
// 释放当前线程
semaphore.release();
} catch (InterruptedException e) {
log.error("", e);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
log.info("count: {}", count);
}
private static void add() {
// 加锁
LOCK.lock();
try {
count++;
} finally {
// 解锁
LOCK.unlock();
}
}
}
在ReentrantLock 中, lock() 方法是一个无条件的锁,与synchronize意思差不多,但是另一个方法 tryLock() 方法只有在成功获取了锁的情况下才会返回true,如果别的线程当前正持有锁,则会立即返回false。如果为这个方法加上timeout参数,则会在等待timeout的时间才会返回false或者在获取到锁的时候返回true。
其他常用方法:
boolean isHeldByCurrentThread(); // 当前线程是否保持锁定 boolean isLocked() // 是否存在任意线程持有锁资源 void lockInterruptbly() // 如果当前线程未被中断,则获取锁定;如果已中断,则抛出异常(InterruptedException) int getHoldCount() // 查询当前线程保持此锁定的个数,即调用lock()方法的次数 int getQueueLength() // 返回正等待获取此锁定的预估线程数 int getWaitQueueLength(Condition condition) // 返回与此锁定相关的约定condition的线程预估数 boolean hasQueuedThread(Thread thread) // 当前线程是否在等待获取锁资源 boolean hasQueuedThreads() // 是否有线程在等待获取锁资源 boolean hasWaiters(Condition condition) // 是否存在指定Condition的线程正在等待锁资源 boolean isFair() // 是否使用的是公平锁
Condition
Condition是一个多线程间协调通信的工具类,使得某个,或者某些线程一起等待某个条件(Condition),只有当该条件具备( signal 或者 signalAll方法被调用)时 ,这些等待线程才会被唤醒,从而重新争夺锁。
Condition可以非常灵活的操作线程的唤醒,下面是一个线程等待与唤醒的例子,其中用1、2、3、4序号标出了日志输出顺序:
@Slf4j
public class LockExample6 {
public static void main(String[] args) {
// 构建ReentrantLock实例
ReentrantLock reentrantLock = new ReentrantLock();
// 从reentrantLock实例里获取condition实例
Condition condition = reentrantLock.newCondition();
// 线程1
new Thread(() -> {
try {
// 线程1调用了lock方法,这时线程1就会加入到了AQS的等待队里面去
reentrantLock.lock();
log.info("wait signal"); // 1 等待信号
// 调用await方法后,线程1就会从AQS队列里移除,这里其实就已经释放了锁,然后线程1会马上进入到condition队列里面去,等待一个信号
condition.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
log.info("get signal"); // 4 得到信号
// 线程1释放锁,整个过程执行完毕
reentrantLock.unlock();
}).start();
// 线程2
new Thread(() -> {
// 由于线程1中调用了await释放了锁的关系,所以线程2就会被唤醒获取到锁,加入到AQS等待队列中
reentrantLock.lock();
log.info("get lock"); // 2 获取锁
try {
// 睡眠3秒
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 调用signalAll发送信号的方法,此时condition等待队列里线程1所在的节点元素就会被取出,然后重新放到AQS等待队列里(注意此时线程1还没有被唤醒)
condition.signalAll();
log.info("send signal ~ "); // 3 发送信号
// 线程2释放锁,这时候AQS队列中只剩下线程1,然后AQS会按照从头到尾的顺序唤醒线程,于是线程1开始执行
reentrantLock.unlock();
}).start();
}
}
可以看到,整个协调通信的过程是靠线程所在的节点在AQS的等待队列和condition的等待队列中来回移动实现的。condition作为一个条件类很好的维护了一个等待信号的队列,并在signal 或者 signalAll方法被调用后,将等待的线程节点重新放回AQS的等待队列中,从而实现唤醒线程的操作。
ReentrantReadWriteLock
ReentrantReadWriteLock是Lock的另一种实现方式,我们已经知道了ReentrantLock是一个排他锁,同一时间只允许一个线程访问,而ReentrantReadWriteLock允许多个读线程同时访问,但不允许写线程和读线程、写线程和写线程同时访问。在没有任何读写锁的时候才能取得写入的锁,可用于实现悲观读取。相对于排他锁,提高了并发性。在实际应用中,大部分情况下对共享数据(如缓存)的访问都是读操作远多于写操作,这时ReentrantReadWriteLock能够提供比排他锁更好的并发性和吞吐量,所以读写锁适用于读多写少的情况。但读多写少的场景下可能会令写入线程遭遇饥饿,即写入线程迟迟无法获取到锁资源而处于等待状态。
与互斥锁相比,使用读写锁能否提升性能则取决于读写操作期间读取数据相对于修改数据的频率,以及数据的争用——即在同一时间试图对该数据执行读取或写入操作的线程数。
读写锁内部维护了两个锁,一个用于读操作,一个用于写操作。所有 ReadWriteLock实现都必须保证 writeLock操作的内存同步效果也要保持与相关 readLock的联系。也就是说,成功获取读锁的线程会看到写入锁之前版本所做的所有更新。
ReentrantReadWriteLock支持以下功能:
1.非公平模式(默认):连续竞争的非公平锁可能无限期地推迟一个或多个reader或writer线程,但吞吐量通常要高于公平锁。 2.公平模式:线程利用一个近似到达顺序的策略来争夺进入。当释放当前保持的锁时,可以为等待时间最长的单个writer线程分配写入锁,如果有一组等待时间大于所有正在等待的writer线程的reader,将为该组分配读者锁。试图获得公平写入锁的非重入的线程将会阻塞,除非读取锁和写入锁都自由(这意味着没有等待线程)。 3.支持可重入。读线程在获取了读锁后还可以获取读锁;写线程在获取了写锁之后既可以再次获取写锁又可以获取读锁 4.还允许从写入锁降级为读取锁,其实现方式是:先获取写入锁,然后获取读取锁,最后释放写入锁。但是,从读取锁升级到写入锁是不允许的 5.读取锁和写入锁都支持锁获取期间的中断 6.Condition支持。仅写入锁提供了一个 Conditon 实现;读取锁不支持 Conditon ,readLock().newCondition() 会抛出 UnsupportedOperationException。 7.监测:此类支持一些确定是读取锁还是写入锁的方法。这些方法设计用于监视系统状态,而不是同步控制。
例如我现在有一个类,里面有一个map集合,我们都知道操作map时都是读多写少的,所以我希望在对其读写的时候能够进行一些线程安全的保护,这时我们就可以使用到ReentrantReadWriteLock。示例代码如下:
public class LockExample3 {
private final Map<String, Data> map = new TreeMap<>();
private final ReentrantReadWriteLock readWriteLock = new ReentrantReadWriteLock();
private final Lock readLock = readWriteLock.readLock();
private final Lock writeLock = readWriteLock.writeLock();
public Data get(String key) {
// 读锁
readLock.lock();
try {
return map.get(key);
} finally {
readLock.unlock();
}
}
public Set<String> getAllKeys() {
// 读锁
readLock.lock();
try {
return map.keySet();
} finally {
readLock.unlock();
}
}
public Data put(String key, Data value) {
// 在没有任何读写锁的时候才会进行写入操作
writeLock.lock();
try {
return map.put(key, value);
} finally {
writeLock.unlock();
}
}
class Data {
}
}
StempedLock
StampedLock是Java8引入的一种新的锁机制,简单的理解,可以认为它是读写锁的一个改进版本,读写锁虽然分离了读和写的功能,使得读与读之间可以完全并发,但是读和写之间依然是冲突的,读锁会完全阻塞写锁,它使用的依然是悲观的锁策略。如果有大量的读线程,它也有可能引起写线程的饥饿。而StampedLock则提供了一种乐观的读策略,这种乐观策略的锁非常类似于无锁的操作,使得乐观锁完全不会阻塞写线程。
StempedLock控制锁有三种形式,分别是写,读,和乐观读,重点在乐观锁。一个StempedLock,状态是由版本和模式两个部分组成。锁获取的方法返回的是一个数字作为票据(Stempe),他用相应的锁状态来表示并控制相关的访问,数字0表示没有写锁被授权访问,在读锁上分为悲观读和乐观读。
所谓的乐观读模式,也就是若读的操作很多,写的操作很少的情况下,你可以乐观地认为,写入与读取同时发生几率很少,因此不悲观地使用完全的读取锁定,程序可以查看读取资料之后,是否遭到写入执行的变更,再采取后续的措施(重新读取变更信息,或者抛出异常) ,这一个小小改进,可大幅度提高程序的吞吐量
适用场景:
乐观读取模式仅用于短时间读取操作时经常能够降低竞争和提高吞吐量。当然,它的使用在本质上是脆弱的。乐观读取的区域应该只包括字段,并且在validation之后用局部变量持有它们从而在后续使用。乐观模式下读取的字段值很可能是非常不一致的,所以它应该只用于那些你熟悉如何展示数据,从而你可以不断检查一致性和调用方法validate
优化点:
1.乐观读不阻塞悲观读和写操作,有利于获得写锁 2.队列头结点采用有限次数SPINS次自旋(增加开销),增加获得锁几率(因为闯入的线程会竞争锁),有效够降低上下文切换 3.读模式的集合通过一个公共节点被聚集在一起(cowait链),当队列尾节点为RMODE,通过CAS方法将该节点node添加至尾节点的cowait链中,node成为cowait中的顶元素,cowait构成了一个LIFO队列。 4.不支持锁重入,如果只悲观读锁和写锁,效率没有ReentrantReadWriteLock高。
基本使用示例:
public class LockExample5 {
private final static StampedLock LOCK = new StampedLock();
private static void add() {
// 加写锁
long stamp = LOCK.writeLock();
try {
count++;
} finally {
// 解锁需要传入加锁时返回的stamp
LOCK.unlock(stamp);
}
}
}
其实在StempedLock的源码中,提供了一段示例代码,但没有相应的注释,所以这里对该示例代码给出一些注释。如下:
class Point {
private double x, y;
private final StampedLock sl = new StampedLock();
void move(double deltaX, double deltaY) { // an exclusively locked method
long stamp = sl.writeLock();
try {
x += deltaX;
y += deltaY;
} finally {
sl.unlockWrite(stamp);
}
}
// 乐观读锁案例
double distanceFromOrigin() { // A read-only method
long stamp = sl.tryOptimisticRead(); //获得一个乐观读锁
double currentX = x, currentY = y; //将两个字段读入本地局部变量
if (!sl.validate(stamp)) { //检查发出乐观读锁后同时是否有其他写锁发生?
stamp = sl.readLock(); //如果没有,我们再次获得一个读悲观锁
try {
currentX = x; // 将两个字段读入本地局部变量
currentY = y; // 将两个字段读入本地局部变量
} finally {
sl.unlockRead(stamp);
}
}
return Math.sqrt(currentX * currentX + currentY * currentY);
}
// 悲观读锁案例
void moveIfAtOrigin(double newX, double newY) { // upgrade
// Could instead start with optimistic, not read mode
long stamp = sl.readLock();
try {
while (x == 0.0 && y == 0.0) { //循环,检查当前状态是否符合
long ws = sl.tryConvertToWriteLock(stamp); //将读锁转为写锁
if (ws != 0L) { //这是确认转为写锁是否成功
stamp = ws; //如果成功 替换票据
x = newX; //进行状态改变
y = newY; //进行状态改变
break;
} else { //如果不能成功转换为写锁
sl.unlockRead(stamp); //我们显式释放读锁
stamp = sl.writeLock(); //显式直接进行写锁 然后再通过循环再试
}
}
} finally {
sl.unlock(stamp); //释放读锁或写锁
}
}
}
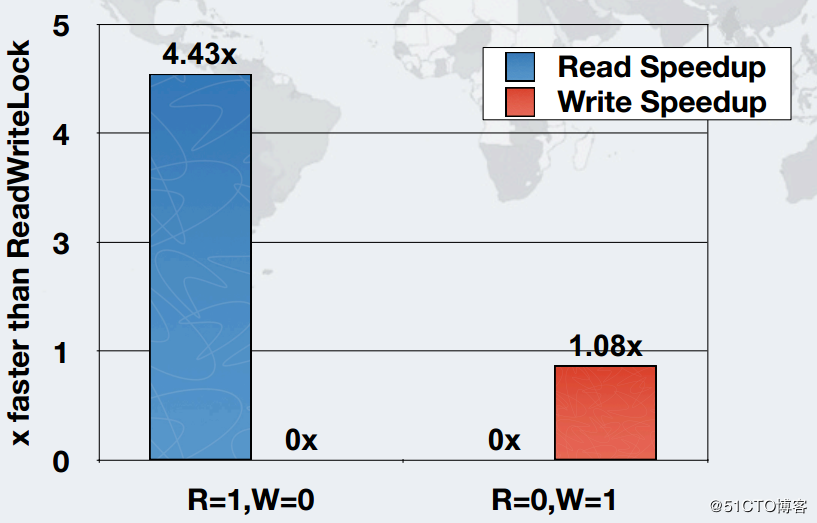
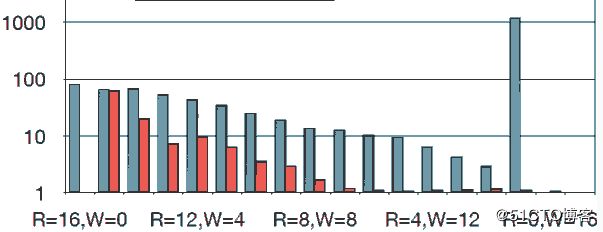
下图是和ReadWritLock相比,在一个线程情况下,是读速度其4倍左右,写是1倍:
下图是六个线程情况下,读性能是其几十倍,写性能也是近10倍左右:
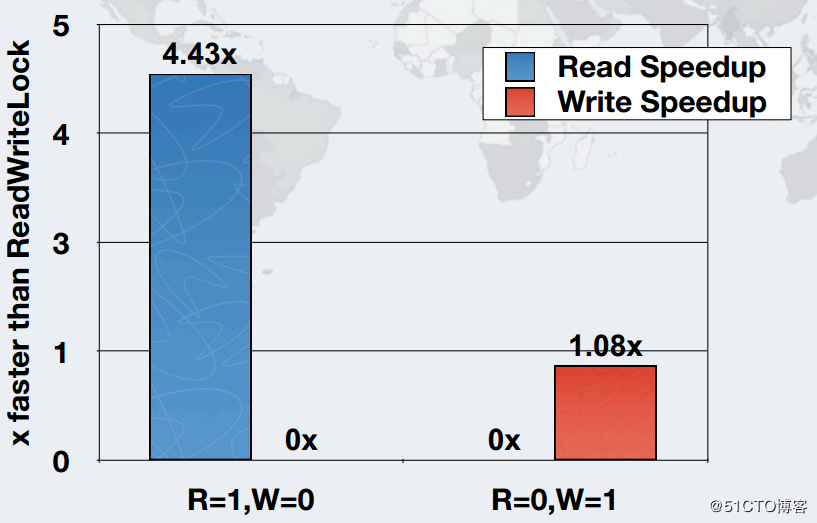
下图是吞吐量提高:
StampedLock 小结:
StampedLock 对吞吐量有巨大的改进,特别是在读线程越来越多的场景下。但StampedLock有一个复杂的API,对于加锁操作,很容易误用其他方法。StampedLock 可以说是Lock的一个很好的补充,吞吐量以及性能上的提升足以打动很多人了,但并不是说要替代之前Lock的东西,毕竟它还是有些应用场景的,起码API比StampedLock容易入手
总结关于锁的几个类:
- synchronized:JVM实现,不但可以通过一些监控工具监控,而且在出现未知异常的时候JVM也会自动帮我们释放锁
- ReentrantLock、ReentrantRead/WriteLock、StempedLock 他们都是对象层面的锁定,要想保证锁一定被释放,要放到finally里面,才会更安全一些。StempedLock对性能有很大的改进,特别是在读线程越来越多的情况下。
如何使用:
- 在只有少量竞争者的时候,synchronized是一个很好的锁的实现
- 竞争者不少,但是增长量是可以预估的,ReentrantLock是一个很好的锁的通用实现(适合使用场景的才是最好的,不是越高级越好)
部分参考:
https://blog.csdn.net/luoyuyou/article/details/30259877
http://www.importnew.com/14941.html正文到此结束
- 本文标签: 数据 时间 value 总结 http executor 线程同步 Semaphore db 线程 调试 需求 key final ask cache 排他锁 CyclicBarrier node 数据库 代码 Excel 锁 统计 Service 本质 并发 tab 银行 开发者 SDN 实例 volatile src Action 一致性 缓存 源码 swap UI 多线程 HTML 并发编程 dist queue id CountDownLatch 测试 tar map API CTO 开发 client message 希望 synchronized 编译 安全 管理 设计模式 操作系统 example 文章 Collection 构造方法 java https cat NSA 注释 参数 同步 ACE IO JVM rmi struct 进程
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

