关于Jackson默认丢失Bigdecimal精度问题分析
问题描述
最近在使用一个内部的RPC框架时,发现如果使用Object类型,实际类型为BigDecimal的时候,作为传输对象的时候,会出现丢失精度的问题;比如在序列化前为金额1.00,反序列化之后为1.0,本身值可能没有影响,但是在有些强依赖金额的地方,会出现问题;
问题分析
查看源码发现RPC框架默认使用的序列化框架为Jackson,那简单,看一下本地是否可以重现问题;
1.准备数据传输bean
public class Bean1 {
private String p1;
private BigDecimal p2;
...省略get/set...
}
public class Bean2 {
private String p1;
private Object p2;
...省略get/set...
}
为了更好的看出问题,分别准备了2个bean;
2.准备测试类
public class JKTest {
public static void main(String[] args) throws IOException {
ObjectMapper mapper = new ObjectMapper();
Bean1 bean1 = new Bean1("haha1", new BigDecimal("1.00"));
Bean2 bean2 = new Bean2("haha2", new BigDecimal("2.00"));
String bs1 = mapper.writeValueAsString(bean1);
String bs2 = mapper.writeValueAsString(bean2);
System.out.println(bs1);
System.out.println(bs2);
Bean1 b1 = mapper.readValue(bs1, Bean1.class);
System.out.println(b1.toString());
Bean2 b22 = mapper.readValue(bs2, Bean2.class);
System.out.println(b22.toString());
}
}
分别对Bean1和Bean2进行序列化和反序列化操作,然后查看结果;
3.显示结果
{"p1":"haha1","p2":1.00}
{"p1":"haha2","p2":2.00}
Bean1 [p1=haha1, p2=1.00]
Bean2 [p1=haha2, p2=2.0]
4.结果分析
结果可以发现两个问题:
1.在序列化的时候2个bean都没有问题;
2.重现了问题,Bean2在反序列化时,p2出现了精度丢失的问题;
5.源码分析
通过一步一步查看Jackson源码,最终定位到UntypedObjectDeserializer的Vanilla内部类中,反序列方法如下:
public Object deserialize(JsonParser p, DeserializationContext ctxt) throws IOException
{
switch (p.getCurrentTokenId()) {
case JsonTokenId.ID_START_OBJECT:
{
JsonToken t = p.nextToken();
if (t == JsonToken.END_OBJECT) {
return new LinkedHashMap<String,Object>(2);
}
}
case JsonTokenId.ID_FIELD_NAME:
return mapObject(p, ctxt);
case JsonTokenId.ID_START_ARRAY:
{
JsonToken t = p.nextToken();
if (t == JsonToken.END_ARRAY) { // and empty one too
if (ctxt.isEnabled(DeserializationFeature.USE_JAVA_ARRAY_FOR_JSON_ARRAY)) {
return NO_OBJECTS;
}
return new ArrayList<Object>(2);
}
}
if (ctxt.isEnabled(DeserializationFeature.USE_JAVA_ARRAY_FOR_JSON_ARRAY)) {
return mapArrayToArray(p, ctxt);
}
return mapArray(p, ctxt);
case JsonTokenId.ID_EMBEDDED_OBJECT:
return p.getEmbeddedObject();
case JsonTokenId.ID_STRING:
return p.getText();
case JsonTokenId.ID_NUMBER_INT:
if (ctxt.hasSomeOfFeatures(F_MASK_INT_COERCIONS)) {
return _coerceIntegral(p, ctxt);
}
return p.getNumberValue(); // should be optimal, whatever it is
case JsonTokenId.ID_NUMBER_FLOAT:
if (ctxt.isEnabled(DeserializationFeature.USE_BIG_DECIMAL_FOR_FLOATS)) {
return p.getDecimalValue();
}
return p.getNumberValue();
case JsonTokenId.ID_TRUE:
return Boolean.TRUE;
case JsonTokenId.ID_FALSE:
return Boolean.FALSE;
case JsonTokenId.ID_END_OBJECT:
// 28-Oct-2015, tatu: [databind#989] We may also be given END_OBJECT (similar to FIELD_NAME),
// if caller has advanced to the first token of Object, but for empty Object
return new LinkedHashMap<String,Object>(2);
case JsonTokenId.ID_NULL: // 08-Nov-2016, tatu: yes, occurs
return null;
//case JsonTokenId.ID_END_ARRAY: // invalid
default:
}
return ctxt.handleUnexpectedToken(Object.class, p);
}
在Bean2中的p2是一个Object类型,所以Jackson中给定的反序列化类为UntypedObjectDeserializer,这个比较容易理解;然后根据具体的数据类型,调用不用的读取方法;因为json这种序列化方式,除了数据,本身并没有存放具体的数据类型,所有这里Jackson认定2.00为一个ID_NUMBER_FLOAT类型,在这个case下面有2个选择,默认是直接调用getNumberValue()方法,这种情况会丢失精度,返回结果为2.0;或者开启使用USE_BIG_DECIMAL_FOR_FLOATS特性,问题解决也很简单,使用此特性即可;
6.使用USE_BIG_DECIMAL_FOR_FLOATS特性
ObjectMapper mapper = new ObjectMapper(); mapper.enable(DeserializationFeature.USE_BIG_DECIMAL_FOR_FLOATS);
再次测试,可以发现结果如下:
{"p1":"haha1","p2":1.00}
{"p1":"haha2","p2":2.00}
Bean1 [p1=haha1, p2=1.00]
Bean2 [p1=haha2, p2=2.00]
7.反序列扩展
Jackson本身提供了对序列化和反序列扩展的功能,对应特殊的Bean可以自己定义反序列类,比如针对Bean2,可以实现Bean2Deserializer,然后在ObjectMapper进行注册
ObjectMapper mapper = new ObjectMapper();
SimpleModule desModule = new SimpleModule("testModule");
desModule.addDeserializer(Bean2.class, new Bean2Deserializer(Bean2.class));
mapper.registerModule(desModule);
扩展
Json本身并没有存放数据类型,只有数据本身,那应该类Json的序列化方式应该都存在此问题;
1.FastJson分析
准备测试代码如下:
public class FJTest {
public static void main(String[] args) {
Bean1 bean1 = new Bean1("haha1", new BigDecimal("1.00"));
Bean2 bean2 = new Bean2("haha2", new BigDecimal("2.00"));
String jsonString1 = JSON.toJSONString(bean1);
String jsonString2 = JSON.toJSONString(bean2);
System.out.println(jsonString1);
System.out.println(jsonString2);
Bean1 bean11 = JSON.parseObject(jsonString1, Bean1.class);
Bean2 bean22 = JSON.parseObject(jsonString2, Bean2.class);
System.out.println(bean11.toString());
System.out.println(bean22.toString());
}
}
结果如下:
{"p1":"haha1","p2":1.00}
{"p1":"haha2","p2":2.00}
Bean1 [p1=haha1, p2=1.00]
Bean2 [p1=haha2, p2=2.00]
可以发现FastJson并不存在此问题,查看源码,定位到DefaultJSONParser的parse方法,部分代码如下:
public Object parse(Object fieldName) {
final JSONLexer lexer = this.lexer;
switch (lexer.token()) {
case SET:
lexer.nextToken();
HashSet<Object> set = new HashSet<Object>();
parseArray(set, fieldName);
return set;
case TREE_SET:
lexer.nextToken();
TreeSet<Object> treeSet = new TreeSet<Object>();
parseArray(treeSet, fieldName);
return treeSet;
case LBRACKET:
JSONArray array = new JSONArray();
parseArray(array, fieldName);
if (lexer.isEnabled(Feature.UseObjectArray)) {
return array.toArray();
}
return array;
case LBRACE:
JSONObject object = new JSONObject(lexer.isEnabled(Feature.OrderedField));
return parseObject(object, fieldName);
case LITERAL_INT:
Number intValue = lexer.integerValue();
lexer.nextToken();
return intValue;
case LITERAL_FLOAT:
Object value = lexer.decimalValue(lexer.isEnabled(Feature.UseBigDecimal));
lexer.nextToken();
return value;
case LITERAL_STRING:
String stringLiteral = lexer.stringVal();
lexer.nextToken(JSONToken.COMMA);
if (lexer.isEnabled(Feature.AllowISO8601DateFormat)) {
JSONScanner iso8601Lexer = new JSONScanner(stringLiteral);
try {
if (iso8601Lexer.scanISO8601DateIfMatch()) {
return iso8601Lexer.getCalendar().getTime();
}
} finally {
iso8601Lexer.close();
}
}
return stringLiteral;
case NULL:
lexer.nextToken();
return null;
case UNDEFINED:
lexer.nextToken();
return null;
case TRUE:
lexer.nextToken();
return Boolean.TRUE;
case FALSE:
lexer.nextToken();
return Boolean.FALSE;
...省略...
}
类似jackson的方式,根据不同的类型做不同的数据处理,同样2.00也被认为是float类型,同样需要检测是否开启Feature.UseBigDecimal特性,只不过FastJson默认开启了此功能;
2.Protostuff分析
下面再来看一个非Json类序列化方式,看protostuff是如果处理此种问题的;
准备测试代码如下:
@SuppressWarnings("unchecked")
public class PBTest {
public static void main(String[] args) {
Bean1 bean1 = new Bean1("haha1", new BigDecimal("1.00"));
Bean2 bean2 = new Bean2("haha2", new BigDecimal("2.00"));
LinkedBuffer buffer1 = LinkedBuffer.allocate(LinkedBuffer.DEFAULT_BUFFER_SIZE);
Schema schema1 = RuntimeSchema.createFrom(bean1.getClass());
byte[] bytes1 = ProtostuffIOUtil.toByteArray(bean1, schema1, buffer1);
Bean1 bean11 = new Bean1();
ProtostuffIOUtil.mergeFrom(bytes1, bean11, schema1);
System.out.println(bean11.toString());
LinkedBuffer buffer2 = LinkedBuffer.allocate(LinkedBuffer.DEFAULT_BUFFER_SIZE);
Schema schema2 = RuntimeSchema.createFrom(bean2.getClass());
byte[] bytes2 = ProtostuffIOUtil.toByteArray(bean2, schema2, buffer2);
Bean2 bean22 = new Bean2();
ProtostuffIOUtil.mergeFrom(bytes2, bean22, schema2);
System.out.println(bean22.toString());
}
}
结果如下:
Bean1 [p1=haha1, p2=1.00] Bean2 [p1=haha2, p2=2.00]
可以发现Protostuff也不存在此问题,原因是因为Protostuff在序列化的时候就将类型等信息存放在二进制中,不同的类型给定了不同的标识,RuntimeFieldFactory列出了所有标识:
public abstract class RuntimeFieldFactory<V> implements Delegate<V>
{
static final int ID_BOOL = 1, ID_BYTE = 2, ID_CHAR = 3, ID_SHORT = 4,
ID_INT32 = 5, ID_INT64 = 6, ID_FLOAT = 7,
ID_DOUBLE = 8,
ID_STRING = 9,
ID_BYTES = 10,
ID_BYTE_ARRAY = 11,
ID_BIGDECIMAL = 12,
ID_BIGINTEGER = 13,
ID_DATE = 14,
ID_ARRAY = 15, // 1-15 is encoded as 1 byte on protobuf and
// protostuff format
ID_OBJECT = 16, ID_ARRAY_MAPPED = 17, ID_CLASS = 18,
ID_CLASS_MAPPED = 19, ID_CLASS_ARRAY = 20,
ID_CLASS_ARRAY_MAPPED = 21,
ID_ENUM_SET = 22, ID_ENUM_MAP = 23, ID_ENUM = 24,
ID_COLLECTION = 25, ID_MAP = 26,
ID_POLYMORPHIC_COLLECTION = 28, ID_POLYMORPHIC_MAP = 29,
ID_DELEGATE = 30,
ID_ARRAY_DELEGATE = 32, ID_ARRAY_SCALAR = 33, ID_ARRAY_ENUM = 34,
ID_ARRAY_POJO = 35,
ID_THROWABLE = 52,
// pojo fields limited to 126 if not explicitly using @Tag
// annotations
ID_POJO = 127;
......
}
序列化的时候是已如下格式来存储数据的,如下图所示:
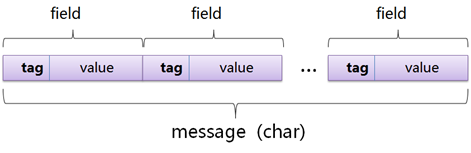
tag里面包含了字段的位置标识,比如第一个字段,第二个字段…,以及类型信息,可以看一下两个bean序列化之后的二进制信息:
104 97 104 97 49和104 97 104 97 50分别是:haha1和haha2;49 46 48 48和50 46 48 48分别是1.00和2.00;
Bean2存储的数据量明细比Bean1大,因为Bean2中的p2作为Object存储,需要存储Object的起始标识和结束标识,还需要保存具体的类型信息;
更多可以参考: https://my.oschina.net/OutOfMemory/blog/800226
总结
类Json序列化方式本身没有保存数据的类型,所以在反序列时有些类型不能区分,只能通过设置特性的方式来解决,但是json格式有更好的可读性;直接序列化为二进制的方式可读性差点,但是可以将很多信息保存进去,更加完善;
示例代码地址
https://github.com/ksfzhaohui/blog
https://gitee.com/OutOfMemory/blog正文到此结束
- 本文标签: 2015 id https GitHub list ACE Collection git 数据 value IO tag db UI 丢失精度 http mapper HashSet tab map json ask ORM BigInteger 源码 cat parse src bean ArrayList 测试 tar App schema scala HashMap PHP CTO 总结 Features token java js 代码 final
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

