netty源码分析之揭开reactor线程的面纱(一)
netty最核心的就是reactor线程,对应项目中使用广泛的NioEventLoop,那么NioEventLoop里面到底在干些什么事?netty是如何保证事件循环的高效轮询和任务的及时执行?又是如何来优雅地fix掉jdk的nio bug?带着这些疑问,本篇文章将庖丁解牛,带你逐步了解netty reactor线程的真相[源码基于4.1.6.Final]
reactor 线程的启动
NioEventLoop的run方法是reactor线程的主体,在第一次添加任务的时候被启动
NioEventLoop 父类 SingleThreadEventExecutor 的execute方法
@Override
public void execute(Runnable task) {
...
boolean inEventLoop = inEventLoop();
if (inEventLoop) {
addTask(task);
} else {
startThread();
addTask(task);
...
}
...
}
复制代码
外部线程在往任务队列里面添加任务的时候执行 startThread() ,netty会判断reactor线程有没有被启动,如果没有被启动,那就启动线程再往任务队列里面添加任务
private void startThread() {
if (STATE_UPDATER.get(this) == ST_NOT_STARTED) {
if (STATE_UPDATER.compareAndSet(this, ST_NOT_STARTED, ST_STARTED)) {
doStartThread();
}
}
}
复制代码
SingleThreadEventExecutor 在执行 doStartThread 的时候,会调用内部执行器 executor 的execute方法,将调用NioEventLoop的run方法的过程封装成一个runnable塞到一个线程中去执行
private void doStartThread() {
...
executor.execute(new Runnable() {
@Override
public void run() {
thread = Thread.currentThread();
...
SingleThreadEventExecutor.this.run();
...
}
}
}
复制代码
该线程就是 executor 创建,对应netty的reactor线程实体。 executor 默认是 ThreadPerTaskExecutor
默认情况下, ThreadPerTaskExecutor 在每次执行 execute 方法的时候都会通过 DefaultThreadFactory 创建一个 FastThreadLocalThread 线程,而这个线程就是netty中的reactor线程实体
ThreadPerTaskExecutor
public void execute(Runnable command) {
threadFactory.newThread(command).start();
}
复制代码
关于为啥是 ThreadPerTaskExecutor 和 DefaultThreadFactory 的组合来new一个 FastThreadLocalThread ,这里就不再详细描述,通过下面几段代码来简单说明
标准的netty程序会调用到 NioEventLoopGroup 的父类 MultithreadEventExecutorGroup 的如下代码
protected MultithreadEventExecutorGroup(int nThreads, Executor executor,
EventExecutorChooserFactory chooserFactory, Object... args) {
if (executor == null) {
executor = new ThreadPerTaskExecutor(newDefaultThreadFactory());
}
}
复制代码
然后通过newChild的方式传递给 NioEventLoop
@Override
protected EventLoop newChild(Executor executor, Object... args) throws Exception {
return new NioEventLoop(this, executor, (SelectorProvider) args[0],
((SelectStrategyFactory) args[1]).newSelectStrategy(), (RejectedExecutionHandler) args[2]);
}
复制代码
关于reactor线程的创建和启动就先讲这么多,我们总结一下:netty的reactor线程在添加一个任务的时候被创建,该线程实体为 FastThreadLocalThread (这玩意以后会开篇文章重点讲讲),最后线程执行主体为 NioEventLoop 的 run 方法。
reactor 线程的执行
那么下面我们就重点剖析一下 NioEventLoop 的run方法
@Override
protected void run() {
for (;;) {
try {
switch (selectStrategy.calculateStrategy(selectNowSupplier, hasTasks())) {
case SelectStrategy.CONTINUE:
continue;
case SelectStrategy.SELECT:
select(wakenUp.getAndSet(false));
if (wakenUp.get()) {
selector.wakeup();
}
default:
// fallthrough
}
processSelectedKeys();
runAllTasks(...);
}
} catch (Throwable t) {
handleLoopException(t);
}
...
}
复制代码
我们抽取出主干,reactor线程做的事情其实很简单,用下面一幅图就可以说明
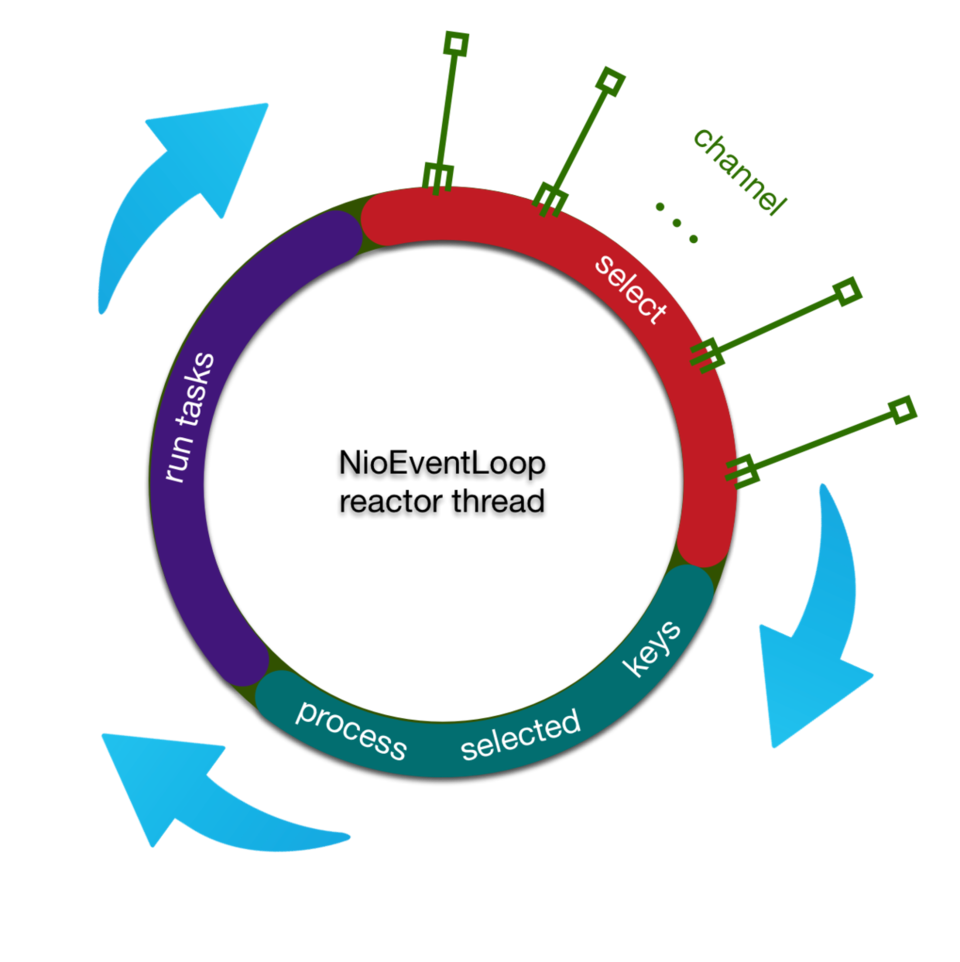
reactor线程大概做的事情分为对三个步骤不断循环
1.首先轮询注册到reactor线程对用的selector上的所有的channel的IO事件
select(wakenUp.getAndSet(false));
if (wakenUp.get()) {
selector.wakeup();
}
复制代码
2.处理产生网络IO事件的channel
processSelectedKeys(); 复制代码
3.处理任务队列
runAllTasks(...); 复制代码
下面对每个步骤详细说明
select操作
select(wakenUp.getAndSet(false));
if (wakenUp.get()) {
selector.wakeup();
}
复制代码
wakenUp 表示是否应该唤醒正在阻塞的select操作,可以看到netty在进行一次新的loop之前,都会将 wakeUp 被设置成false,标志新的一轮loop的开始,具体的select操作我们也拆分开来看
1.定时任务截止事时间快到了,中断本次轮询
int selectCnt = 0;
long currentTimeNanos = System.nanoTime();
long selectDeadLineNanos = currentTimeNanos + delayNanos(currentTimeNanos);
for (;;) {
long timeoutMillis = (selectDeadLineNanos - currentTimeNanos + 500000L) / 1000000L;
if (timeoutMillis <= 0) {
if (selectCnt == 0) {
selector.selectNow();
selectCnt = 1;
}
break;
}
....
}
复制代码
我们可以看到,NioEventLoop中reactor线程的select操作也是一个for循环,在for循环第一步中,如果发现当前的定时任务队列中有任务的截止事件快到了(<=0.5ms),就跳出循环。此外,跳出之前如果发现目前为止还没有进行过select操作( if (selectCnt == 0) ),那么就调用一次 selectNow() ,该方法会立即返回,不会阻塞
这里说明一点,netty里面定时任务队列是按照延迟时间从小到大进行排序, delayNanos(currentTimeNanos) 方法即取出第一个定时任务的延迟时间
protected long delayNanos(long currentTimeNanos) {
ScheduledFutureTask<?> scheduledTask = peekScheduledTask();
if (scheduledTask == null) {
return SCHEDULE_PURGE_INTERVAL;
}
return scheduledTask.delayNanos(currentTimeNanos);
}
复制代码
关于netty的任务队列(包括普通任务,定时任务,tail task)相关的细节后面会另起一片文章,这里不过多展开
2.轮询过程中发现有任务加入,中断本次轮询
for (;;) {
// 1.定时任务截至事时间快到了,中断本次轮询
...
// 2.轮询过程中发现有任务加入,中断本次轮询
if (hasTasks() && wakenUp.compareAndSet(false, true)) {
selector.selectNow();
selectCnt = 1;
break;
}
....
}
复制代码
netty为了保证任务队列能够及时执行,在进行阻塞select操作的时候会判断任务队列是否为空,如果不为空,就执行一次非阻塞select操作,跳出循环
3.阻塞式select操作
for (;;) {
// 1.定时任务截至事时间快到了,中断本次轮询
...
// 2.轮询过程中发现有任务加入,中断本次轮询
...
// 3.阻塞式select操作
int selectedKeys = selector.select(timeoutMillis);
selectCnt ++;
if (selectedKeys != 0 || oldWakenUp || wakenUp.get() || hasTasks() || hasScheduledTasks()) {
break;
}
....
}
复制代码
执行到这一步,说明netty任务队列里面队列为空,并且所有定时任务延迟时间还未到(大于0.5ms),于是,在这里进行一次阻塞select操作,截止到第一个定时任务的截止时间
这里,我们可以问自己一个问题,如果第一个定时任务的延迟非常长,比如一个小时,那么有没有可能线程一直阻塞在select操作,当然有可能!But,只要在这段时间内,有新任务加入,该阻塞就会被释放
外部线程调用execute方法添加任务
@Override
public void execute(Runnable task) {
...
wakeup(inEventLoop); // inEventLoop为false
...
}
复制代码
调用wakeup方法唤醒selector阻塞
protected void wakeup(boolean inEventLoop) {
if (!inEventLoop && wakenUp.compareAndSet(false, true)) {
selector.wakeup();
}
}
复制代码
可以看到,在外部线程添加任务的时候,会调用wakeup方法来唤醒 selector.select(timeoutMillis)
阻塞select操作结束之后,netty又做了一系列的状态判断来决定是否中断本次轮询,中断本次轮询的条件有
selectedKeys != 0 hasTasks hasScheduledTasks() wakenUp.get()
4.解决jdk的nio bug
关于该bug的描述见 bugs.java.com/bugdatabase…
该bug会导致Selector一直空轮询,最终导致cpu 100%,nio server不可用,严格意义上来说,netty没有解决jdk的bug,而是通过一种方式来巧妙地避开了这个bug,具体做法如下
long currentTimeNanos = System.nanoTime();
for (;;) {
// 1.定时任务截止事时间快到了,中断本次轮询
...
// 2.轮询过程中发现有任务加入,中断本次轮询
...
// 3.阻塞式select操作
selector.select(timeoutMillis);
// 4.解决jdk的nio bug
long time = System.nanoTime();
if (time - TimeUnit.MILLISECONDS.toNanos(timeoutMillis) >= currentTimeNanos) {
selectCnt = 1;
} else if (SELECTOR_AUTO_REBUILD_THRESHOLD > 0 &&
selectCnt >= SELECTOR_AUTO_REBUILD_THRESHOLD) {
rebuildSelector();
selector = this.selector;
selector.selectNow();
selectCnt = 1;
break;
}
currentTimeNanos = time;
...
}
复制代码
netty 会在每次进行 selector.select(timeoutMillis) 之前记录一下开始时间 currentTimeNanos ,在select之后记录一下结束时间,判断select操作是否至少持续了 timeoutMillis 秒(这里将 time - TimeUnit.MILLISECONDS.toNanos(timeoutMillis) >= currentTimeNanos 改成 time - currentTimeNanos >= TimeUnit.MILLISECONDS.toNanos(timeoutMillis) 或许更好理解一些), 如果持续的时间大于等于timeoutMillis,说明就是一次有效的轮询,重置 selectCnt 标志,否则,表明该阻塞方法并没有阻塞这么长时间,可能触发了jdk的空轮询bug,当空轮询的次数超过一个阀值的时候,默认是512,就开始重建selector
空轮询阀值相关的设置代码如下
int selectorAutoRebuildThreshold = SystemPropertyUtil.getInt("io.netty.selectorAutoRebuildThreshold", 512);
if (selectorAutoRebuildThreshold < MIN_PREMATURE_SELECTOR_RETURNS) {
selectorAutoRebuildThreshold = 0;
}
SELECTOR_AUTO_REBUILD_THRESHOLD = selectorAutoRebuildThreshold;
复制代码
下面我们简单描述一下netty 通过 rebuildSelector 来fix空轮询bug的过程, rebuildSelector 的操作其实很简单:new一个新的selector,将之前注册到老的selector上的的channel重新转移到新的selector上。我们抽取完主要代码之后的骨架如下
public void rebuildSelector() {
final Selector oldSelector = selector;
final Selector newSelector;
newSelector = openSelector();
int nChannels = 0;
try {
for (;;) {
for (SelectionKey key: oldSelector.keys()) {
Object a = key.attachment();
if (!key.isValid() || key.channel().keyFor(newSelector) != null) {
continue;
}
int interestOps = key.interestOps();
key.cancel();
SelectionKey newKey = key.channel().register(newSelector, interestOps, a);
if (a instanceof AbstractNioChannel) {
((AbstractNioChannel) a).selectionKey = newKey;
}
nChannels ++;
}
break;
}
} catch (ConcurrentModificationException e) {
// Probably due to concurrent modification of the key set.
continue;
}
selector = newSelector;
oldSelector.close();
}
复制代码
首先,通过 openSelector() 方法创建一个新的selector,然后执行一个死循环,只要执行过程中出现过一次并发修改selectionKeys异常,就重新开始转移
具体的转移步骤为
- 拿到有效的key
- 取消该key在旧的selector上的事件注册
- 将该key对应的channel注册到新的selector上
- 重新绑定channel和新的key的关系
转移完成之后,就可以将原有的selector废弃,后面所有的轮询都是在新的selector进行
最后,我们总结reactor线程select步骤做的事情:不断地轮询是否有IO事件发生,并且在轮询的过程中不断检查是否有定时任务和普通任务,保证了netty的任务队列中的任务得到有效执行,轮询过程顺带用一个计数器避开了了jdk空轮询的bug,过程清晰明了
由于篇幅原因,下面两个过程将分别放到一篇文章中去讲述,尽请期待
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

