netty源码分析之揭开reactor线程的面纱(三)
上两篇博文( netty源码分析之揭开reactor线程的面纱(一) , netty源码分析之揭开reactor线程的面纱(二) )已经描述了netty的reactor线程前两个步骤所处理的工作,在这里,我们用这张图片来回顾一下:
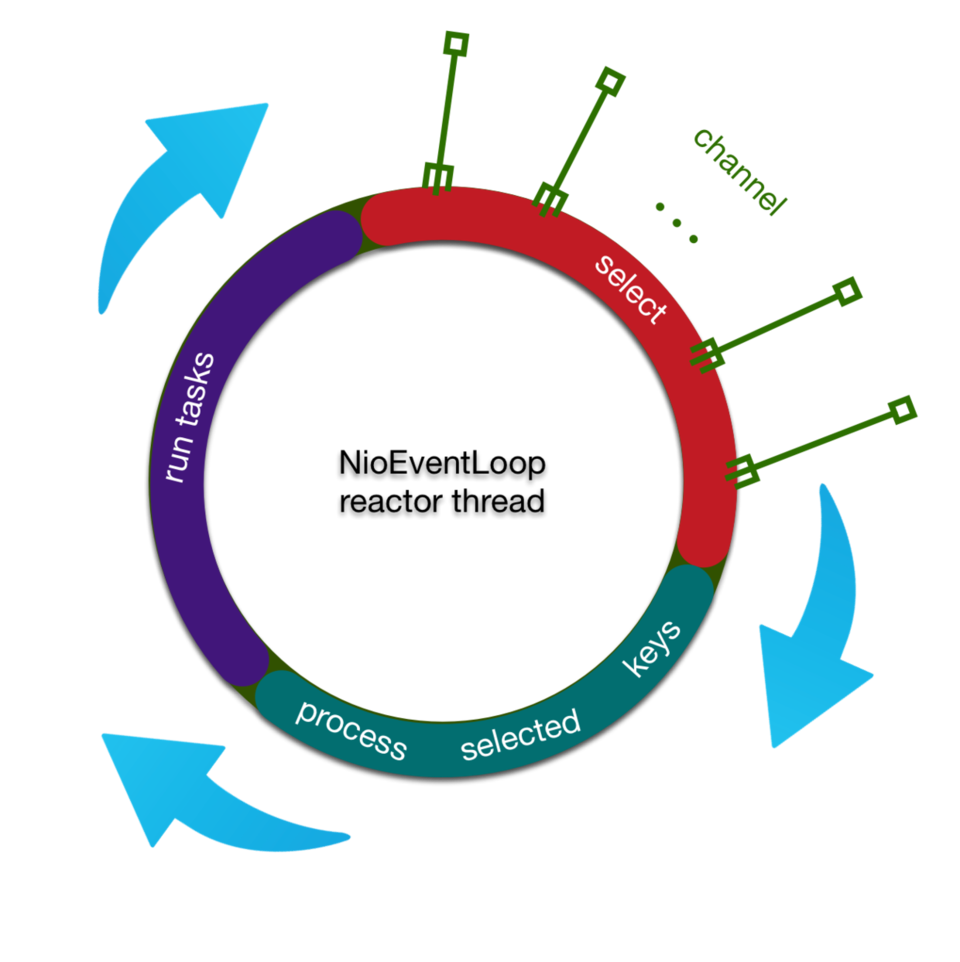
简单总结一下reactor线程三部曲
- 轮询出IO事件
- 处理IO事件
- 处理任务队列
今天,我们要进行的是三部曲中的最后一曲【处理任务队列】,也就是上面图中的紫色部分。
读完本篇文章,你将了解到netty的异步task机制,定时任务的处理逻辑,这些细节可以更好地帮助你写出netty应用
netty中的task的常见使用场景
我们取三种典型的task使用场景来分析
一. 用户自定义普通任务
ctx.channel().eventLoop().execute(new Runnable() {
@Override
public void run() {
//...
}
});
复制代码
我们跟进 execute 方法,看重点
@Override
public void execute(Runnable task) {
//...
addTask(task);
//...
}
复制代码
execute 方法调用 addTask 方法
protected void addTask(Runnable task) {
// ...
if (!offerTask(task)) {
reject(task);
}
}
复制代码
然后调用 offerTask 方法,如果offer失败,那就调用 reject 方法,通过默认的 RejectedExecutionHandler 直接抛出异常
final boolean offerTask(Runnable task) {
// ...
return taskQueue.offer(task);
}
复制代码
跟到 offerTask 方法,基本上task就落地了,netty内部使用一个 taskQueue 将task保存起来,那么这个 taskQueue 又是何方神圣?
我们查看 taskQueue 定义的地方和被初始化的地方
private final Queue<Runnable> taskQueue;
taskQueue = newTaskQueue(this.maxPendingTasks);
@Override
protected Queue<Runnable> newTaskQueue(int maxPendingTasks) {
// This event loop never calls takeTask()
return PlatformDependent.newMpscQueue(maxPendingTasks);
}
复制代码
我们发现 taskQueue 在NioEventLoop中默认是mpsc队列,mpsc队列,即多生产者单消费者队列,netty使用mpsc,方便的将外部线程的task聚集,在reactor线程内部用单线程来串行执行,我们可以借鉴netty的任务执行模式来处理类似多线程数据上报,定时聚合的应用
在本节讨论的任务场景中,所有代码的执行都是在reactor线程中的,所以,所有调用 inEventLoop() 的地方都返回true,既然都是在reactor线程中执行,那么其实这里的mpsc队列其实没有发挥真正的作用,mpsc大显身手的地方其实在第二种场景
二. 非当前reactor线程调用channel的各种方法
// non reactor thread channel.write(...) 复制代码
上面一种情况在push系统中比较常见,一般在业务线程里面,根据用户的标识,找到对应的channel引用,然后调用write类方法向该用户推送消息,就会进入到这种场景
关于channel.write()类方法的调用链,后面会单独拉出一篇文章来深入剖析,这里,我们只需要知道,最终write方法串至以下方法
AbstractChannelHandlerContext.java
private void write(Object msg, boolean flush, ChannelPromise promise) {
// ...
EventExecutor executor = next.executor();
if (executor.inEventLoop()) {
if (flush) {
next.invokeWriteAndFlush(m, promise);
} else {
next.invokeWrite(m, promise);
}
} else {
AbstractWriteTask task;
if (flush) {
task = WriteAndFlushTask.newInstance(next, m, promise);
} else {
task = WriteTask.newInstance(next, m, promise);
}
safeExecute(executor, task, promise, m);
}
}
复制代码
外部线程在调用 write 的时候, executor.inEventLoop() 会返回false,直接进入到else分支,将write封装成一个 WriteTask (这里仅仅是write而没有flush,因此 flush 参数为false), 然后调用 safeExecute 方法
private static void safeExecute(EventExecutor executor, Runnable runnable, ChannelPromise promise, Object msg) {
// ...
executor.execute(runnable);
// ...
}
复制代码
接下来的调用链就进入到第一种场景了,但是和第一种场景有个明显的区别就是,第一种场景的调用链的发起线程是reactor线程,第二种场景的调用链的发起线程是用户线程,用户线程可能会有很多个,显然多个线程并发写 taskQueue 可能出现线程同步问题,于是,这种场景下,netty的mpsc queue就有了用武之地
三. 用户自定义定时任务
ctx.channel().eventLoop().schedule(new Runnable() {
@Override
public void run() {
}
}, 60, TimeUnit.SECONDS);
复制代码
第三种场景就是定时任务逻辑了,用的最多的便是如上方法:在一定时间之后执行任务
我们跟进 schedule 方法
public ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit) {
//...
return schedule(new ScheduledFutureTask<Void>(
this, command, null, ScheduledFutureTask.deadlineNanos(unit.toNanos(delay))));
}
复制代码
通过 ScheduledFutureTask , 将用户自定义任务再次包装成一个netty内部的任务
<V> ScheduledFuture<V> schedule(final ScheduledFutureTask<V> task) {
// ...
scheduledTaskQueue().add(task);
// ...
return task;
}
复制代码
到了这里,我们有点似曾相识,在非定时任务的处理中,netty通过一个mpsc队列将任务落地,这里,是否也有一个类似的队列来承载这类定时任务呢?带着这个疑问,我们继续向前
Queue<ScheduledFutureTask<?>> scheduledTaskQueue() {
if (scheduledTaskQueue == null) {
scheduledTaskQueue = new PriorityQueue<ScheduledFutureTask<?>>();
}
return scheduledTaskQueue;
}
复制代码
果不其然, scheduledTaskQueue() 方法,会返回一个优先级队列,然后调用 add 方法将定时任务加入到队列中去,但是,这里为什么要使用优先级队列,而不需要考虑多线程的并发?
因为我们现在讨论的场景,调用链的发起方是reactor线程,不会存在多线程并发这些问题
但是,万一有的用户在reactor之外执行定时任务呢?虽然这类场景很少见,但是netty作为一个无比健壮的高性能io框架,必须要考虑到这种情况。
对此,netty的处理是,如果是在外部线程调用schedule,netty将添加定时任务的逻辑封装成一个普通的task,这个task的任务是添加[添加定时任务]的任务,而不是添加定时任务,其实也就是第二种场景,这样,对 PriorityQueue 的访问就变成单线程,即只有reactor线程
完整的schedule方法
<V> ScheduledFuture<V> schedule(final ScheduledFutureTask<V> task) {
if (inEventLoop()) {
scheduledTaskQueue().add(task);
} else {
// 进入到场景二,进一步封装任务
execute(new Runnable() {
@Override
public void run() {
scheduledTaskQueue().add(task);
}
});
}
return task;
}
复制代码
在阅读源码细节的过程中,我们应该多问几个为什么?这样会有利于看源码的时候不至于犯困!比如这里,为什么定时任务要保存在优先级队列中,我们可以先不看源码,来思考一下优先级对列的特性
优先级队列按一定的顺序来排列内部元素,内部元素必须是可以比较的,联系到这里每个元素都是定时任务,那就说明定时任务是可以比较的,那么到底有哪些地方可以比较?
每个任务都有一个下一次执行的截止时间,截止时间是可以比较的,截止时间相同的情况下,任务添加的顺序也是可以比较的,就像这样,阅读源码的过程中,一定要多和自己对话,多问几个为什么
带着猜想,我们研究与一下 ScheduledFutureTask ,抽取出关键部分
final class ScheduledFutureTask<V> extends PromiseTask<V> implements ScheduledFuture<V> {
private static final AtomicLong nextTaskId = new AtomicLong();
private static final long START_TIME = System.nanoTime();
static long nanoTime() {
return System.nanoTime() - START_TIME;
}
private final long id = nextTaskId.getAndIncrement();
/* 0 - no repeat, >0 - repeat at fixed rate, <0 - repeat with fixed delay */
private final long periodNanos;
@Override
public int compareTo(Delayed o) {
//...
}
// 精简过的代码
@Override
public void run() {
}
复制代码
这里,我们一眼就找到了 compareTo 方法, cmd+u 跳转到实现的接口,发现就是 Comparable 接口
public int compareTo(Delayed o) {
if (this == o) {
return 0;
}
ScheduledFutureTask<?> that = (ScheduledFutureTask<?>) o;
long d = deadlineNanos() - that.deadlineNanos();
if (d < 0) {
return -1;
} else if (d > 0) {
return 1;
} else if (id < that.id) {
return -1;
} else if (id == that.id) {
throw new Error();
} else {
return 1;
}
}
复制代码
进入到方法体内部,我们发现,两个定时任务的比较,确实是先比较任务的截止时间,截止时间相同的情况下,再比较id,即任务添加的顺序,如果id再相同的话,就抛Error
这样,在执行定时任务的时候,就能保证最近截止时间的任务先执行
下面,我们再来看下netty是如何来保证各种定时任务的执行的,netty里面的定时任务分以下三种
1.若干时间后执行一次 2.每隔一段时间执行一次 3.每次执行结束,隔一定时间再执行一次
netty使用一个 periodNanos 来区分这三种情况,正如netty的注释那样
/* 0 - no repeat, >0 - repeat at fixed rate, <0 - repeat with fixed delay */ private final long periodNanos; 复制代码
了解这些背景之后,我们来看下netty是如何来处理这三种不同类型的定时任务的
public void run() {
if (periodNanos == 0) {
V result = task.call();
setSuccessInternal(result);
} else {
task.call();
long p = periodNanos;
if (p > 0) {
deadlineNanos += p;
} else {
deadlineNanos = nanoTime() - p;
}
scheduledTaskQueue.add(this);
}
}
}
复制代码
if (periodNanos == 0) 对应 若干时间后执行一次 的定时任务类型,执行完了该任务就结束了。
否则,进入到else代码块,先执行任务,然后再区分是哪种类型的任务, periodNanos 大于0,表示是以固定频率执行某个任务,和任务的持续时间无关,然后,设置该任务的下一次截止时间为本次的截止时间加上间隔时间 periodNanos ,否则,就是每次任务执行完毕之后,间隔多长时间之后再次执行,截止时间为当前时间加上间隔时间, -p 就表示加上一个正的间隔时间,最后,将当前任务对象再次加入到队列,实现任务的定时执行
netty内部的任务添加机制了解地差不多之后,我们就可以查看reactor第三部曲是如何来调度这些任务的
reactor线程task的调度
首先,我们将目光转向最外层的外观代码
runAllTasks(long timeoutNanos); 复制代码
顾名思义,这行代码表示了尽量在一定的时间内,将所有的任务都取出来run一遍。 timeoutNanos 表示该方法最多执行这么长时间,netty为什么要这么做?我们可以想一想,reactor线程如果在此停留的时间过长,那么将积攒许多的IO事件无法处理(见reactor线程的前面两个步骤),最终导致大量客户端请求阻塞,因此,默认情况下,netty将控制内部队列的执行时间
好,我们继续跟进
protected boolean runAllTasks(long timeoutNanos) {
fetchFromScheduledTaskQueue();
Runnable task = pollTask();
//...
final long deadline = ScheduledFutureTask.nanoTime() + timeoutNanos;
long runTasks = 0;
long lastExecutionTime;
for (;;) {
safeExecute(task);
runTasks ++;
if ((runTasks & 0x3F) == 0) {
lastExecutionTime = ScheduledFutureTask.nanoTime();
if (lastExecutionTime >= deadline) {
break;
}
}
task = pollTask();
if (task == null) {
lastExecutionTime = ScheduledFutureTask.nanoTime();
break;
}
}
afterRunningAllTasks();
this.lastExecutionTime = lastExecutionTime;
return true;
}
复制代码
这段代码便是reactor执行task的所有逻辑,可以拆解成下面几个步骤
- 从scheduledTaskQueue转移定时任务到taskQueue(mpsc queue)
- 计算本次任务循环的截止时间
- 执行任务
- 收尾
按照这个步骤,我们一步步来分析下
从scheduledTaskQueue转移定时任务到taskQueue(mpsc queue)
首先调用 fetchFromScheduledTaskQueue() 方法,将到期的定时任务转移到mpsc queue里面
private boolean fetchFromScheduledTaskQueue() {
long nanoTime = AbstractScheduledEventExecutor.nanoTime();
Runnable scheduledTask = pollScheduledTask(nanoTime);
while (scheduledTask != null) {
if (!taskQueue.offer(scheduledTask)) {
// No space left in the task queue add it back to the scheduledTaskQueue so we pick it up again.
scheduledTaskQueue().add((ScheduledFutureTask<?>) scheduledTask);
return false;
}
scheduledTask = pollScheduledTask(nanoTime);
}
return true;
}
复制代码
可以看到,netty在把任务从scheduledTaskQueue转移到taskQueue的时候还是非常小心的,当taskQueue无法offer的时候,需要把从scheduledTaskQueue里面取出来的任务重新添加回去
从scheduledTaskQueue从拉取一个定时任务的逻辑如下,传入的参数 nanoTime 为当前时间(其实是当前纳秒减去 ScheduledFutureTask 类被加载的纳秒个数)
protected final Runnable pollScheduledTask(long nanoTime) {
assert inEventLoop();
Queue<ScheduledFutureTask<?>> scheduledTaskQueue = this.scheduledTaskQueue;
ScheduledFutureTask<?> scheduledTask = scheduledTaskQueue == null ? null : scheduledTaskQueue.peek();
if (scheduledTask == null) {
return null;
}
if (scheduledTask.deadlineNanos() <= nanoTime) {
scheduledTaskQueue.remove();
return scheduledTask;
}
return null;
}
复制代码
可以看到,每次 pollScheduledTask 的时候,只有在当前任务的截止时间已经到了,才会取出来
计算本次任务循环的截止时间
Runnable task = pollTask();
//...
final long deadline = ScheduledFutureTask.nanoTime() + timeoutNanos;
long runTasks = 0;
long lastExecutionTime;
复制代码
这一步将取出第一个任务,用reactor线程传入的超时时间 timeoutNanos 来计算出当前任务循环的deadline,并且使用了 runTasks , lastExecutionTime 来时刻记录任务的状态
循环执行任务
for (;;) {
safeExecute(task);
runTasks ++;
if ((runTasks & 0x3F) == 0) {
lastExecutionTime = ScheduledFutureTask.nanoTime();
if (lastExecutionTime >= deadline) {
break;
}
}
task = pollTask();
if (task == null) {
lastExecutionTime = ScheduledFutureTask.nanoTime();
break;
}
}
复制代码
这一步便是netty里面执行所有任务的核心代码了。 首先调用 safeExecute 来确保任务安全执行,忽略任何异常
protected static void safeExecute(Runnable task) {
try {
task.run();
} catch (Throwable t) {
logger.warn("A task raised an exception. Task: {}", task, t);
}
}
复制代码
然后将已运行任务 runTasks 加一,每隔 0x3F 任务,即每执行完64个任务之后,判断当前时间是否超过本次reactor任务循环的截止时间了,如果超过,那就break掉,如果没有超过,那就继续执行。可以看到,netty对性能的优化考虑地相当的周到,假设netty任务队列里面如果有海量小任务,如果每次都要执行完任务都要判断一下是否到截止时间,那么效率是比较低下的
收尾
afterRunningAllTasks(); this.lastExecutionTime = lastExecutionTime; 复制代码
收尾工作很简单,调用一下 afterRunningAllTasks 方法
@Override
protected void afterRunningAllTasks() {
runAllTasksFrom(tailTasks);
}
复制代码
NioEventLoop 可以通过父类 SingleTheadEventLoop 的 executeAfterEventLoopIteration 方法向 tailTasks 中添加收尾任务,比如,你想统计一下一次执行一次任务循环花了多长时间就可以调用此方法
public final void executeAfterEventLoopIteration(Runnable task) {
// ...
if (!tailTasks.offer(task)) {
reject(task);
}
//...
}
复制代码
this.lastExecutionTime = lastExecutionTime; 简单记录一下任务执行的时间,搜了一下该field的引用,发现这个field并没有使用过,只是每次不停地赋值,赋值,赋值...,改天再去向netty官方提个issue...
reactor线程第三曲到了这里基本上就给你讲完了,如果你读到这觉得很轻松,那么恭喜你,你对netty的task机制已经非常比较熟悉了,也恭喜一下我,把这些机制给你将清楚了。我们最后再来一次总结,以tips的方式
- 当前reactor线程调用当前eventLoop执行任务,直接执行,否则,添加到任务队列稍后执行
- netty内部的任务分为普通任务和定时任务,分别落地到MpscQueue和PriorityQueue
- netty每次执行任务循环之前,会将已经到期的定时任务从PriorityQueue转移到MpscQueue
- netty每隔64个任务检查一下是否该退出任务循环
如果你想系统地学Netty,我的小册 《Netty 入门与实战:仿写微信 IM 即时通讯系统》 可以帮助你,如果你想系统学习Netty原理,那么你一定不要错过我的Netty源码分析系列视频: coding.imooc.com/class/230.h…
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

