DockOne微信分享(一九〇):Spring Cloud Kubernetes容器化实践
【编者的话】公司原有业务布署在虚拟机ECS、KVM上,脚本分散、日志分散、难于集中收集管理,监控不统一,CPU、内存、磁盘资源使用率低,运维效率极低,无法集中管理。通过导入Kubernetes平台打通DevOps全链路,实现统一集中运维管理,提升运维效率,提高资源利用率,提升整个研发团队协作效率。
原有运维系统缺点
- 原有业务布署在虚拟机ECS、KVM上,脚本分散、日志分散、难于集中收集管理,监控不统一,CPU、内存、磁盘资源使用率低,运维效率极低,无法集中管理。
- 新业务布署需要开通新的虚拟机,需要单独定制监控,各种Crontab,配置脚本,效率低下,CI/CD Jenkins配置繁琐。
Kubernetes容器化优势
- 利用Kubernetes容器平台namespaces对不同环境进行区分,建立不同dev、test、stage、prod环境,实现隔离。
- 通过容器化集中布署所有业务,实现一键布署所需环境业务。
- 统一集中监控报警所有容器服务异常状态。
- 统一集中收集所有服务日志至ELK集群,利用Kibana面板进行分类,方便开发查日志。
- 基于Kubernetes命令行二次开发,相关开发、测试人员直接操作容器。
- 基于RBAC对不同的环境授于不同的开发、测试访问Kubernetes权限,防止越权。
- 通过Jenkins统一CI/CD编译发布过程。
- 项目容器化后,整体服务器CPU、内存、磁盘、资源利用减少50%,运维效率提高60%,原来需要N个运维做的事,现在一个人即可搞定。
Kubernetes本身是一套分布式系统,要用好会遇到很多问题,不是说三天两头就能搞定,需要具备网络、Linux系统、存储,等各方面专业知识,在使用过程中我们也踩了不少坑,我们是基于二进制包的方式安装Kubernetes集群,我们Kubernetes集群版本为1.10,经过一段时间的实践,Kubernetes对于我们整个开发、测试、发布、运维流程帮助非常大,值得大力推广。
网络方案选择
- Flannel是 CoreOS 团队针对 Kubernetes 设计的一个覆盖网络(Overlay Network)工具,所有节点通过flanneld节点服务同步路由,使用简单、方便、稳定,是Kubernetes入门首选。
- Calico是基于BGP协议的路由方案,支持ACL,部署复杂,出现问题难排查。
- Weave是基于UDP承载容器之间的数据包,并且可以完全自定义整个集群的网络拓扑,国内使用较少。
- Open vSwitch是一个生产质量的多层虚拟交换机,它旨在通过编程扩展实现大规模网络自动化,同时仍支持标准管理接口和协议,OpenShift-kubernetes平台和混合云使用比较多。
我们对各个网络组件进行过调研对比,网络方案选择的是flanneld-hostgw+ipvs,在Kubernetes 1.9之前是不支持IPVS的,kube-proxy负责所有SVC规则的同步,使用的iptables,一个service会产生N条iptables记录。如果SVC增加到上万条,iptables-svc同步会很慢,得几分钟,使用IPVS之后,所有节点的SVC由IPVS LVS来负载,更快、更稳定,而且简单方便,使用门槛低。host-gw会在所有节同步路由表,每个容器都分配了一个IP地址,可用于与同一主机上的其他容器进行通信。对于通过网络进行通信,容器与主机的IP地址绑定。flanneld host-gw性能接近Calico,相对来说Falnneld配置布署比Calico简单很多。顺便提下flanneld-vxlan这种方式,需要通过UDP封包解包,效率较低,适用于一些私有云对网络封包有限制,禁止路由表添加等有限制的平台。
Flanneld通过为每个容器提供可用于容器到容器通信的IP来解决问题。它使用数据包封装来创建跨越整个群集的虚拟覆盖网络。更具体地说,Flanneld为每个主机提供一个IP子网(默认为/ 24),Docker守护程序可以从中为每个主机分配IP。
Flannel使用etcd来存储虚拟IP和主机地址之间的映射。一个Flanneld守护进程在每台主机上运行,并负责维护etcd信息和路由数据包。
在此提一下,在使用flannled使用过程中遇到过严重bug,即租约失效,flanneld会shutdown节点网络组件,节点网络直接崩掉,解决办法是设置永久租期: https://coreos.com/flannel/doc ... tions 。
传统业务迁移至Kubernetes遇到的问题和痛点,DevOps遇到的问题
使用Kubernetes会建立两套网络,服务之间调用通过service域名,默认网络、域名和现有物理网络是隔离的,开发,测试,运维无法像以前一样使用虚拟机,Postman IP+端口调试服务, 网络都不通,这些都是问题。
- Pod网络和物理网络不通,Windows办公电脑、Linux虚拟机上现有的业务和Kubernetes是隔离的。
- SVC网络和物理网络不通,Windows办公电脑、Linux虚拟机上现有的业务和Kubernetes是隔离的。
- SVC域名和物理网络不通,Windows办公电脑、Linux虚拟机上现有的业务和Kubernetes是隔离的。
- 原有Nginx配置太多的location路由规则,有的有几百层,不好迁移到ingress-nginx,ingress只支持简单的规则。
- SVC-NodePort访问,在所有Node上开启端口监听,占用Node节点端口资源,需要记住端口号。
- ingress-nginx http 80端口, 必需通过域名引入,http 80端口必需通过域名引入,原来简单nginx的location可以通过ingress引入。
- ingress-nginx tcp udp端口访问需要配置一个lb,很麻烦,要先规划好lb节点同样也需要访问lb端口。
- 原有业务不能停,继续运行,同时要能兼容Kubernetes环境,和Kubernetes集群内服务互相通讯调用,网络需要通。
传统虚拟机上布署服务我们只需要一个地址+端口直接访问调试各种服务,Kubernetes是否能做到不用改变用户使用习惯,无感知使用呢?答案是打通DevOps全链路,像虚拟机一样访部Kubernetes集群服务 , 我们打通Kubernetes网络和物理网络直通,物理网络的DNS域名调用Kubernetes DNS域名服务直接互访,所有服务互通。公司原有业务和现有Kubernetes集群无障碍互访。
配置一台Kubernetes Node节点机做路由转发,配置不需要太高,布署成路由器模式,所有外部访问Kubernetes集群流量都经该节点,本机IP:192.168.2.71。
vim /etc/sysctl.conf net.ipv4.ip_forward = 1
设置全网路由通告,交换机或者Linux、Windows主机加上静态路由,打通网络。
route add -net 172.20.0.0 netmask 255.255.0.0 gw 192.168.2.71 route add -net 172.21.0.0 netmask 255.255.0.0 gw 192.168.2.71
增加DNS服务器代理,外部服务需要访问Kubernetes service域名,首先需要解析域名,Kubernetes服务只对集群内部开放,此时需要外部能调用KubeDNS 53号端口,所有办公电脑,业务都来请求KubeDNS肯定撑不住,事实上确实是撑不住,我们做过测试,此时需要配置不同的域名进行分流策略,公网域名走公网DNS,内部.svc.cluster.local走KubeDNS。
1、建立DNS代理服务器,ingress建立一个nginx-ingress服务反代KubeDNS,ingress-nginx绑定到DNS节点运行,在节点上监听DNS 53端口。
[root@master1 kube-dns-proxy-1.10]# cat tcp-services-configmap.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: tcp-services
namespace: ingress-nginx
data:
53: "kube-system/kube-dns:53"
[root@master1 kube-dns-proxy-1.10]# cat udp-services-configmap.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: udp-services
namespace: ingress-nginx
data:
53: "kube-system/kube-dns:53"
[root@master1 kube-dns-proxy-1.10]# cat ingress-nginx-deploy.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: nginx-ingress-controller-dns
namespace: ingress-nginx
spec:
replicas: 1
selector:
matchLabels:
app: ingress-nginx-dns
template:
metadata:
labels:
app: ingress-nginx-dns
annotations:
prometheus.io/port: '10254'
prometheus.io/scrape: 'true'
spec:
hostNetwork: true
serviceAccountName: nginx-ingress-serviceaccount
containers:
- name: nginx-ingress-controller-dns
image: registry-k8s.novalocal/public/nginx-ingress-controller:0.12.0
args:
- /nginx-ingress-controller
- --default-backend-service=$(POD_NAMESPACE)/default-http-backend
# - --configmap=$(POD_NAMESPACE)/nginx-configuration
- --tcp-services-configmap=$(POD_NAMESPACE)/tcp-services
- --udp-services-configmap=$(POD_NAMESPACE)/udp-services
- --annotations-prefix=nginx.ingress.kubernetes.io
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
ports:
- name: http
containerPort: 80
#- name: https
# containerPort: 443
livenessProbe:
failureThreshold: 3
httpGet:
path: /healthz
port: 10254
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
readinessProbe:
failureThreshold: 3
httpGet:
path: /healthz
port: 10254
scheme: HTTP
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
nodeSelector:
node: dns
2、最简单快捷的方式是安装Dnsmasq,当然你也可以用Bind,PowerDNS,CoreDNS等改造,上游DNS配置为上一步骤增加nginx-ingress dns的地址,所有办公,业务电脑全部设置DNS为此机,dnsmasq.conf配置分流策略。
no-resolv server=/local/192.168.1.97 server=114.114.114.114
完成以上步骤后Kubernetes pod网络、service网络、 service域名和办公网络,现有ECS、虚拟机完美融合,无缝访问,容器网络问题完美搞定。
Windows访问Kubernetes service畅通无组,开发测试,完美无缝对接。
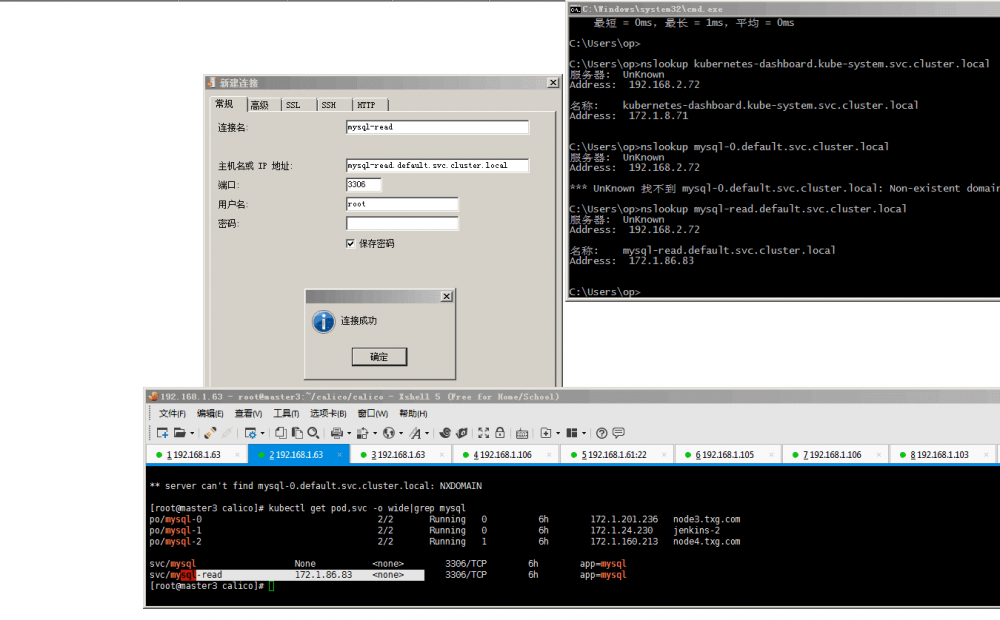
ingress-nginx服务入口接入
服务发布后最终对接的是用户,用户访问Kubernetes服务需要通过nginx或其它http服务器接入,对于服务接入我们同时使用两种不同的方案,取决于nginx location的复杂度,location规则简单的我们使用第一种方案,由于各种问题,location复杂我们使用第二种方案。
- client-------ingress-nginx-----upstream----podip,对于ingress-nginx官方使用的原始方案,先配置ingress规则路由,ingress对接不同的service-dns域名,ingress自动发现后端podip,通过upstream负载不同的后端podip,不同的域名路由到不同的Kubernetes后端podip,用户客户端访问流量会负载到不同的Pod上。
- client------nginx-------upstream------svc-----podip改造现有nginx兼容Kubernetes,对接Kubernetes service服务。对于nginx location规则过多,不能很好的兼容nginx-ingress导致使用Kubernetes非常困难,难以普及,在不变更现有nginx配置的情况下如何对接Kubernetes这是一个问题,经过前面网络打通的步骤我们所有网络的问题都已解决。现在只需改动很小部分即可兼容,由于Kubernetes podip是漂移的,IP总是会变的,nginx只能是对接SVC域名才能持久,但是nginx解析域名有个bug,只解析一次,如果在此期间删除了yaml,nginx会找不到后端svcip,所以这里要设置代理变量set $backend,设置resolver的DNS为代理DNS地址,设置解析域名时间和变量解决该问题。
location /tomcat/ {
resolver 192.168.1.97 valid=3600s;
set $backend "tomcat.dac-prod.svc.cluster.local";
error_log logs/dac_error.log error;
access_log logs/dac_access.log main;
proxy_set_header X-real-ip $remote_addr;
proxy_read_timeout 300;
proxy_connect_timeout 300;
proxy_redirect off;
client_max_body_size 100M;
proxy_pass http://${backend}:9090;
}
大家可能担心Eureka和Kubernetes service有冲突,Spring Cloud本身自带服务发现Eureka,组件之间的调用通过Eureka注册调用,其实你直接布署就行了,Eureka和Service没任何冲突,和普通Java应用一样用。
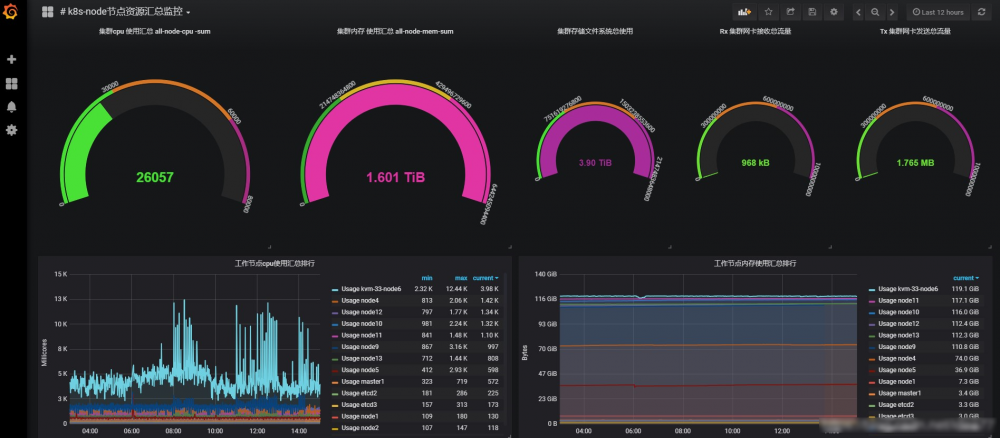
监控方案
目前使用的Kubernetes官方的Heapster,Monitoring-InfluxDB-Grafana +自定议脚本+自定义Grafana面板可以灵活报警。
监控面板按业务环境dev/test/stage/prod/对CPU/内存/网络等分类进行展示。
节点资源监控:
Pod CPU、内存、网络等监控:
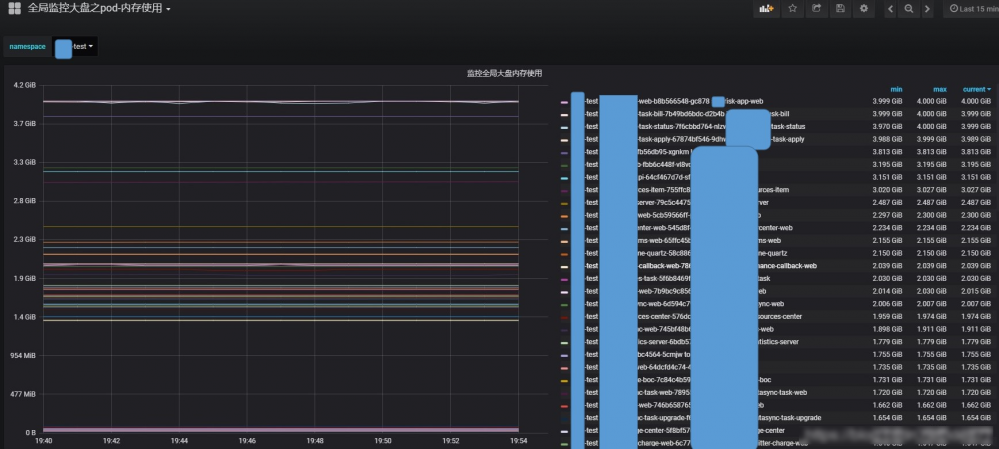
监控脚本,可以很灵活跟据设定参数进行钉钉报警,报告有问题的Pod、Node,自动处理有问题的服务。
#!/bin/bash
最大内存排除的node节点
exclude_node="node7|node1|node2|node3|master1"
exclude_pod="redis|kafka|mongo|zookeeper|Evicted|Completed"
node使用的最大报警内存%比
node_mem_max="100"
node最大使用cpu百分比
node_cpu_max="80"
pod使用的最大报警内存MB
pod_mem_max="4096"
pod_top="5"
pod_top_cpu="10"
pod的启动错误时间,单位为秒s
pod_error_m_time="120"
pyding="$HOME/k8s-dev/dingd-zabbix.python"
pod的内存以及cpu的使用状态
pod_mem=$(/usr/local/bin/kubectl top pod --all-namespaces |sort -n -k4 )
node的内存使用状态
node_status=$(/usr/local/bin/kubectl top node|egrep -v "${exclude_node}" |egrep -v "MEMORY%")
pod的运行状态
pod_status=$(/usr/local/bin/kubectl get pod --all-namespaces -o wide|grep -v NAMESPACE)
设定有问题的pod存取文件路径
alert_error_pod="/tmp/alert-error-pod.txt"
设定最大内存占用节点上pod的文件列表路径
alert_list="/tmp/alert-mem-list.txt"
监控cpu百分比文件输出路径
alert_node_cpu_list="/tmp/alert_node_cpu_list.txt"
取node内存的百分比数字值
node_pre_mem=$(echo "${node_mem}"|awk '{print $5}'|sed -e "s/%//g")
监控node的内存百分比,列出占用内存最高的应用并重启top5应用
node_mem_mon () {
echo "${node_status}" |awk '{print $1,$5}'|sed -e "s/%//g" |while read node_name node_mem_status;do
#echo $node_name $node_mem_status
if [ "${node_mem_status}" -gt "${node_mem_max}" ];then
>${alert_list}
#找到该节点上的所有的pod名
find_pod=$(echo "${pod_status}"|egrep ${node_name}|awk '{print $2}')
#找到所有节点倒排序使用最大的内存的pod列表
for i in $(echo "${find_pod}");do
echo "${pod_mem}"|grep $i >>${alert_list}
done
date_time=`date +'%F-%T'`
echo -e "/n${node_name}最大内存超过 %${node_mem_max} 以下pod应用将被重启 ------------------/n"
cat ${alert_list}|sort -n -k 4|tail -${pod_top}
python ${pyding} "`echo -e "/n ${date_time} ${node_name}当前内存为${node_mem_status}%,最大内存超过 %${node_mem_max} 以下pod应用将被重启 ------------------/n" ;cat ${alert_list}|sort -n -k 4|egrep -v "$exclude_pod"|tail -${pod_top}` "
cat ${alert_list}|sort -n -k 4|egrep -v "$exclude_pod"|tail -${pod_top}|egrep -v "应用将被重启" | awk '{print "/usr/local/bin/kubectl delete pod "$2" -n "$1" " | "/bin/bash"}'
fi
done
}
钉钉报警图:

Kubernetes集群yaml容器编排管理
Kubernetes通过yaml对容器进行管理,yaml配置编排文件是管理整个容器生命周期重要的一部份,管理好yaml非常重要。我开发了一套类似于Helm的模板的脚本框架,用于所有环境的yaml初始化工作 ,自己写脚本的好处就是可以灵活控制,比如哪个组件要挂载存储,共享卷,要配置私有hosts等,我可以一次性定制好,初始化时只需要init-yaml直接批量搞定,不需要每个yml单独去修改,之后就是kubectl create 直接用。
容器编排yaml文件按空间环境dev、test、stage、prod进行模板base分类,复制一套yaml模板即可生成其它各环境,容器编排按业务类型模块配置conf app-list。
[root@master1 config]# ls public-dev_app_list.conf public-test-base.yml public-dev-base.yml sms-test_app_list.conf public-pretest_app_list.conf sms-test-base.yml public-pretest-base.yml wbyh-dev_app_list.conf public-stage_app_list.conf wbyh-dev-base.yml public-stage-base.yml wbyh-stage_app_list.conf public-test_app_list.conf wbyh-stage-base.yml
通过Kubernetes核心排编脚本进行init-yml初始化对应环境,生成所有Pod的yaml排编文件,每套环境可以生成环境对应的MySQL、Redis、Kafka、MongoDB等,直接启动即可调用。
[root@master1 k8s-dev]# ./k8s wbyh-stage init-yml
/root/k8s-dev/config
[root@master1 k8s-dev]# tree
wbyh-stage/
├── app
│ ├── dac-api-center
│ │ └── dac-api-center.yml
│ ├── dac-app-web
│ │ └── dac-app-web.yml
│ ├── dac-config-server
│ │ └── dac-config-server.yml
│ ├── dac-eureka-server
│ │ └── dac-eureka-server.yml
│ ├── dac-task
│ │ └── dac-task.yml
│ ├── dac-task-apply
│ │ └── dac-task-apply.yml
│ ├── dac-task-h5
│ │ └── dac-task-h5.yml
│ ├── dac-web
│ │ └── dac-web.yml
│ ├── dac-message-center
│ │ └── dac-message-center.yml
│ ├── dac-quartz-jfdata
│ │ └── dac-quartz-jfdata.yml
│ ├── dac-quartz-mach
│ │ └── dac-quartz-mach.yml
│ ├── dac-quartz-dac
│ │ └── dac-quartz-dac.yml
│ ├── dac-resources-center
│ │ └── dac-resources-center.yml
│ ├── dac-resources-item
│ │ └── dac-resources-item.yml
│ ├── dac-usercenter-web
│ │ └── dac-usercenter-web.yml
│ └── tomcat
│ └── tomcat.yml
└── stateful-sets
├── kafka
│ ├── 10kafka-config-0420yml
│ ├── 10kafka-config.yml
│ ├── 20dns.yml
│ └── 50kafka.yml
├── mongo
│ └── mongo-statefulset.yml
├── redis
│ ├── primary.yml
│ └── redis-configmap.yml
└── zookeeper
├── 10zookeeper-config.yml
├── 30service.yml
└── 50pzoo.yml
22 directories, 26 files
通过Kubernetes脚本调用kubectl可以直接批量创建该空间下所有服务。
[root@master1 k8s-dev]# ./k8s wbyh-stage create_all /root/k8s-dev/config configmap "dac-eureka-server-filebeat-config" created service "dac-eureka-server" created deployment.extensions "dac-eureka-server" created configmap "dac-config-server-filebeat-config" created service "dac-config-server" created deployment.extensions "dac-config-server" created configmap "tomcat-filebeat-config" created service "tomcat" created deployment.extensions "tomcat" created
所有代码存入GitLab做版本管理,即基础设施即代码。
add svn-jar-version ll item commit 29dc05530d839c826130eef81541ce96a155107b Author: idea77 <idea77@qq.com> Date: Thu Sep 20 16:11:00 2018 +0800 mod ossfs to /Rollback/oss commit 880bcd9483a6ee1f5ca440fef017b30ba7cd14fe Author: idea77 <idea77@qq.com> Date: Wed Sep 19 16:57:43 2018 +0800
存储方案
目前公司一部份应用挂载的卷为NFS,读写要求不高的可以配置NFS, 一部份要求比较高的用的Ceph,如MySQL、Kafka之类的就需要Ceph支撑,对于需要持久化的DB类型存储的管理用StorageClass存储类对接管理,很方便自动建立存储卷PV-PVC对接,共享卷类型可以直接挂载卷。
NFS配置需要在每个Node节点安装NFS-Utils,配置yml,注意CentOS 7低版本3.10内核的nfs-server有bug,导致服务器重启,升到4.0以上内核解决问题。
- name: tomcat-img
nfs:
path: /home/k8s-nfs-data/dac-test-tomcat-img
server: 192.168.8.30
Ceph Kubernetes Node节点安装ceph-commo,配置StorageClass。
ceph-class.yaml apiVersion: storage.k8s.io/v1beta1 kind: StorageClass metadata: name: ceph-db provisioner: kubernetes.io/rbd parameters: monitors: 192.168.1.31:6789 adminId: admin adminSecretName: ceph-secret adminSecretNamespace: kube-system pool: rbd userId: admin userSecretName: ceph-secret
Jenkins CI/CD编译发布阶段
Jenkins CI/CD控制台完成整个jar包编译,Dockerfile编译、docker push、Kubernetes deployment镜像滚动升级功能。
Jenkins Manage and Assign Roles授权不同的开发、测试组不同的用户权限,隔离不同的项目编译发布权限。
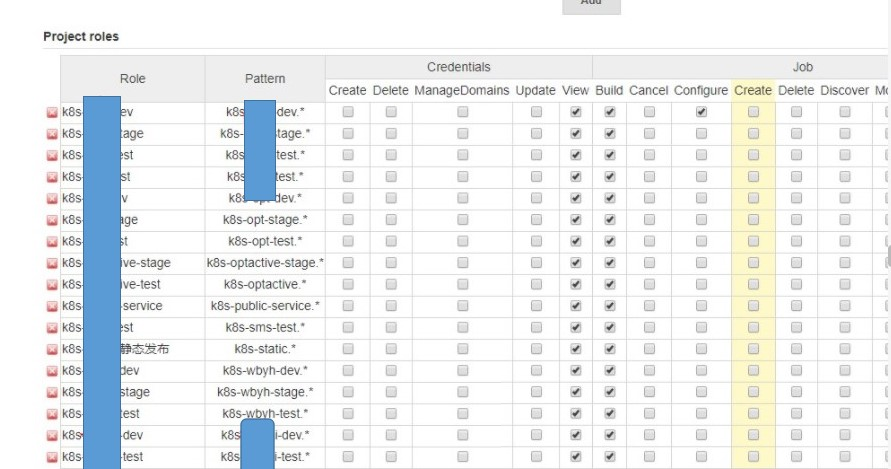
目前没有完全用上流水线服务,完全流水线需要构建不报错,一报错也就无法完成,不是很灵活,构建jar包和发布docker-image是分开的,需要跟据公司业务来。
编译阶段我们做了钉钉通知,每个项目拉了自己的群,编译jar包是否成功整个组都有通知,同样update也是一样发布是不成功都有提示,群内可见。

目前我们Kubernetes容器启动分为两种架构:
- 容器发布后启动基础JDK镜像,Wget去http服务器下载对应目录编译好的jar包,然后启动,即无镜像模式,适合频繁发布类型的业务,push jar to oss有一部份业务是跑虚拟机,需要jar包,oss可以做共享。
- 容器发布按照标准的方式打image update-imae模式,适合出错及时回滚的业务,即编译dockerfile-push-docke-image-update-deployment。
build-$namespace通过空间变量名拟写对应脚本,基本是做一个通用模板base,复制生成对应项目的build.sh供Jenkins传参调用,每套环境有自己的基础镜像base,基础镜像就是打入JDK等一些私有的配置,编译的时候在基础镜像上加上jar包。
if [[ $MY_POD_NAMESPACE =~ -dev ]];then
#定义启动基础镜相
base_image="registry-k8s.novalocal/public/yh-centos7-jdk-1.8"
#定义APP镜像仓库地址
image_path="registry-k8s.novalocal/xl_public/$MY_POD_NAMESPACE/${APP}"
elif [[ $MY_POD_NAMESPACE =~ "-test" ]];then
#定义启动基础镜相
base_image="registry-k8s.novalocal/public/yh-centos7-jdk-1.8"
#定义APP镜像仓库地址
image_path="registry-k8s.novalocal/xl_public/$MY_POD_NAMESPACE/${APP}:${date_time}"
elif [[ $MY_POD_NAMESPACE =~ -stage ]];then
#定义启动基础镜相
base_image="registry-k8s.novalocal/xl_public/wbyh-base/centos7-jdk-1.8"
#定义idc镜相仓库路径
image_path="registry.cn-hangzhou-idc.com/xl_dac/wbyh-stage-${APP}:${date_time}"
vpc_image_path="registry-vpc.cn-hangzhou-idc.com/wbyh-stage-${APP}:${date_time}"
fi
#初始化dockerfile
init_dockerfile () {
#生成Dockerfile
cd /Rollback/build-docker/
echo "" >$MY_POD_NAMESPACE/${APP}/Dockerfile
#生成基础镜像地址
echo -e "${base_image}" >>${MY_POD_NAMESPACE}/${APP}/Dockerfile
#生成docker作者
echo -e "MAINTAINER idea77@qq.com" >>${MY_POD_NAMESPACE}/${APP}/Dockerfile
echo -e "USER root" >>${MY_POD_NAMESPACE}/${APP}/Dockerfile
#获取启动脚本
/cp -f start-sh/${MY_POD_NAMESPACE}-sh/${APP}.sh $MY_POD_NAMESPACE/${APP}/
echo -e "ADD ./${APP}.sh /home/deploy/" >>${MY_POD_NAMESPACE}/${APP}/Dockerfile
#添加 jar包到/home/deploy/
echo -e "${add_jar}" >>${MY_POD_NAMESPACE}/${APP}/Dockerfile
#暴露端口
echo -e "EXPOSE 9090" >>${MY_POD_NAMESPACE}/${APP}/Dockerfile
#添加docker入口启动文件
/cp -f start-sh/templates/docker-entrypoint.sh $MY_POD_NAMESPACE/${APP}/
echo -e "ADD ./docker-entrypoint.sh /docker-entrypoint.sh" >>$MY_POD_NAMESPACE/$APP/Dockerfile
echo -e "RUN chown -R deploy:deploy /home/deploy && chown -R deploy:deploy /docker-entrypoint.sh && ls -t --full /home/deploy " >>$MY_POD_NAMESPACE/$APP/Dockerfile
echo -e "USER deploy" >>$MY_POD_NAMESPACE/$APP/Dockerfile
echo -e 'ENTRYPOINT ["/docker-entrypoint.sh"]' >>$MY_POD_NAMESPACE/$APP/Dockerfile
if [[ ${MY_POD_NAMESPACE} =~ -prod ]];then
docker images |grep xl_prod|grep ${APP}|awk '{print $1":"$2}'|xargs docker rmi -f
else
docker images |grep min-test|grep ${APP}|awk '{print $1":"$2}'|xargs docker rmi -f
fi
name="${MY_POD_NAMESPACE},build ${image_path}-${svn_version}"
cd /Rollback/build-docker/$MY_POD_NAMESPACE/$APP/
docker build --no-cache -t ${image_path}-${svn_version} .
check
if [[ $MY_POD_NAMESPACE =~ -stage ]];then
#vpc专有镜相地址修改到yml文件
sed -i "s@registry-vpc.cn-hangzhou-idc.com/xl_public/(.*/)@${vpc_image_path}-${svn_version}@g" /home/deploy/k8s-dev/${MY_POD_NAMESPACE}/app/$APP/$APP.yml
elif [[ $MY_POD_NAMESPACE =~ -test ]];then
sed -i "s@registry-k8s.novalocal/xl_public//(.*/)@${image_path}-${svn_version}@g" /home/deploy/k8s-dev/${MY_POD_NAMESPACE}/app/$APP/$APP.yml
fi
name="push ${APP}"
docker push ${image_path}-${svn_version}
check
}
Jenkins触发:
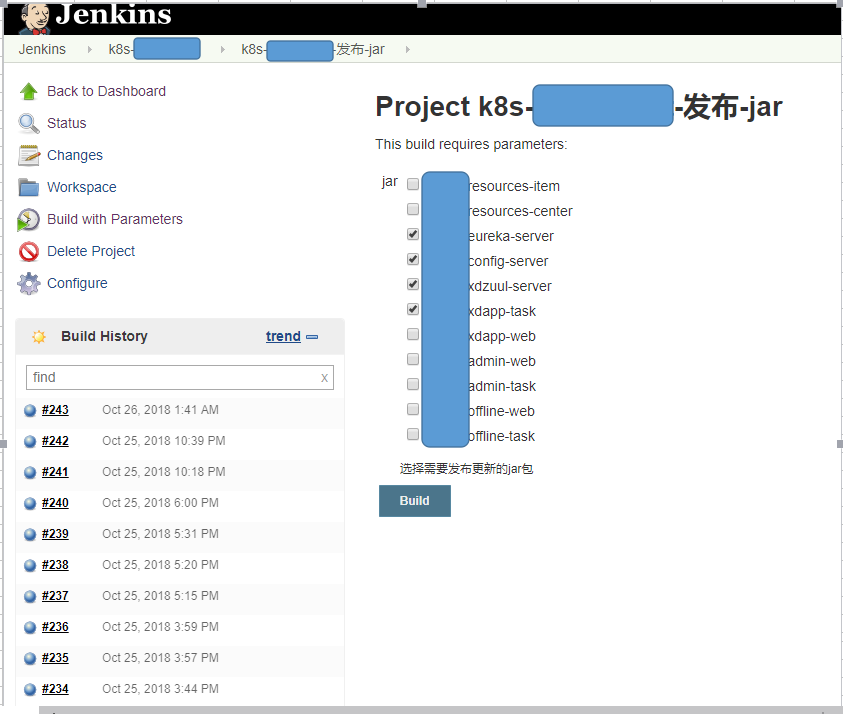
build-----push------updae-deployment-----image,整个过程是流水线形式,一次性连续完成,完成后通过机器人通知到各业务组,中间有任何问题,机器人会告诉我们在哪个阶段出错,很方便排查问题,镜像的版本号根据Git或SVN的版本号来获取,然后加上当前时间戳,在jar包编译阶段版本号会写入特定文件,Jenkins会跟据当前编译的版本生成对应的Docker镜像版本。
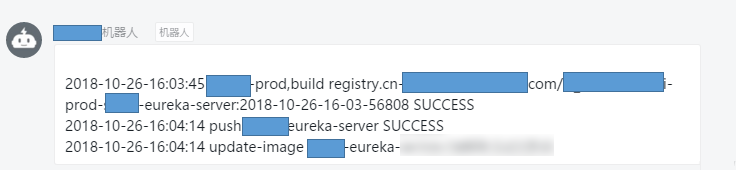
Kubernetes日志方案
普通虚拟机日志分散,难管理,需要登陆虚拟机一个个查看,利用Kubernetes Pod多容器策略可以很方便帮我们收集管理日志,日志方案有几种。
- 应用打到docker stdout前台输出,Docker输出到/var/lib/containers,通过Filebeat、Fluentd、DaemonSet组件收集,这种对于小量日志还可以,大量日志性能很差,写入很慢。
- Pod挂载host-path把日志打到宿主机,宿主机启动Filebeat、Fluentd、DaemonSet收集,无法判断来自哪个容器,哪个Pod和namespace空间。
- Pod的yml中定义两个container,同时启动一个附加的Filebeat,两个container挂载一个共享卷来收集日志。
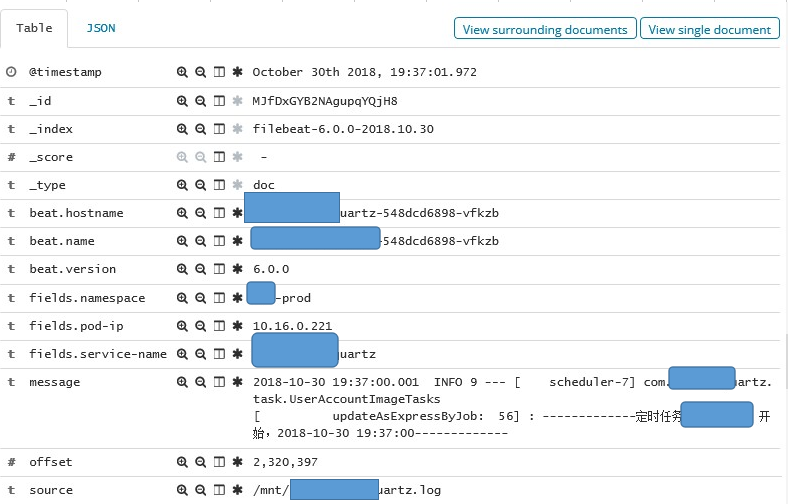
我们用第三种方案,通过一个附加容器Filebeat来收集所有日志,filebeat–kakfa–logstash–es,自定义编译Filebeat容器镜像,为Filebeat打上podip空间service名等标签,方便识别来自哪个容器,哪个namespace,配置config-map以及yaml。
filebeat----kafkacluster-----logstash----es
apiVersion: v1
kind: ConfigMap
metadata:
namespace: dac-prod
name: dac-config-server-filebeat-config
data:
filebeat.yml: |
filebeat.prospectors:
- input_type: log
fields:
namespace: dac-prod
service-name: dac-config-server
#pod-ip:
paths:
- "/mnt/*.log"
multiline:
pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2} [0-9]{2}:[0-9]{2}:[0-9]{2}.[0-9]{3}'
negate: true
match: after
#output.elasticsearch:
output.kafka:
hosts: ["10.31.222.108:9092", "10.31.222.109:9092", "10.31.222.110:9092"]
topic: applog
required_acks: 1
compression: gzip
# Available log levels are: critical, error, warning, info, debug
logging.level: info
---
apiVersion: v1
kind: Service
metadata:
name: dac-config-server
namespace: dac-prod
spec:
ports:
- port: 9090
name: http
selector:
app: dac-config-server
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: dac-config-server
namespace: dac-prod
labels:
app: dac-config-server
spec:
replicas: 1
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
type: RollingUpdate
selector:
matchLabels:
app: dac-config-server
template:
metadata:
labels:
app: dac-config-server
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- dac-config-server
topologyKey: "kubernetes.io/hostname"
imagePullSecrets:
- name: myregistrykey
containers:
- image: registry-vpc.cn-hangzhou-idc.com/dac-prod-dac-config-server:v1
name: dac-config-server
imagePullPolicy: Always
resources:
limits:
cpu: 4000m
memory: 4096Mi
requests:
cpu: 150m
memory: 1024Mi
env:
- name: APP
value: dac-config-server
#public
- name: JAVA_OPTS
value: "-Xms4g -Xmx4g"
- name: CONTAINER_CORE_LIMIT
value: "4"
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: MY_POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
readinessProbe:
tcpSocket:
port: 9090
initialDelaySeconds: 60
timeoutSeconds: 3
livenessProbe:
tcpSocket:
port: 9090
initialDelaySeconds: 60
timeoutSeconds: 3
ports:
- name: http
containerPort: 9090
volumeMounts:
#- name: opt-data
#mountPath: /home/deploy
- name: logs
mountPath: /home/deploy/logs
- name: host-time
mountPath: /etc/localtime
readOnly: true
- image: registry-vpc.cn-hangzhou-idc.com/dac_prod/filebeat:6.0.0
name: filebeat
imagePullPolicy: Always
env:
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
volumeMounts:
- name: logs
mountPath: /mnt
- name: filebeat-conf
mountPath: /etc/filebeat
- name: host-time
mountPath: /etc/localtime
readOnly: true
nodeSelector:
node: public
volumes:
- name: logs
emptyDir: {}
- name: filebeat-conf
configMap:
name: dac-config-server-filebeat-config
#- name: opt-data
#nfs:
#path: /home/k8s-nfs-data/public-dev-base
#server: 10.10.1.30
- name: host-time
hostPath:
path: /etc/localtime
Filebeat收集日志打上关键字标签,namespace,svc,podip等。
Kibana集中日志展示,建立Dashboard分类,用户可以按namespce分类不同环境,过滤选择查看不同模块的应用日志。
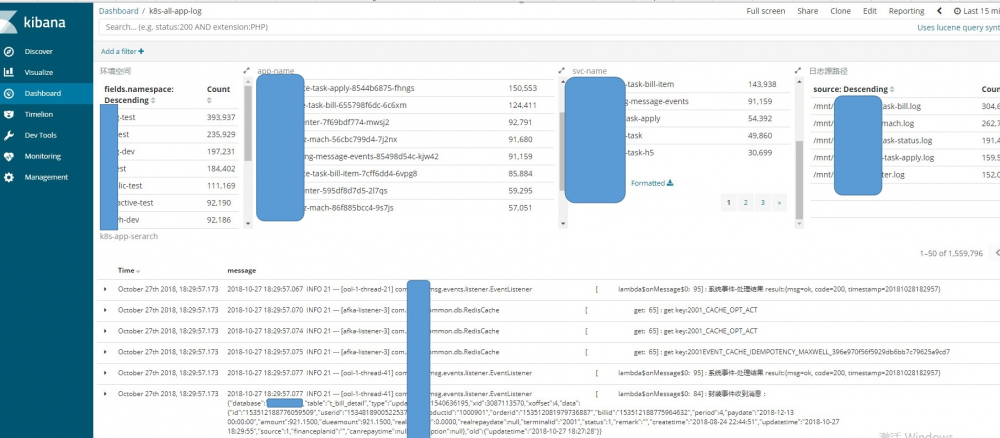
Kibana dashboard界面包含了不同空间不同应用的日志列表。
RBAC+二次开发Kubernetes脚本
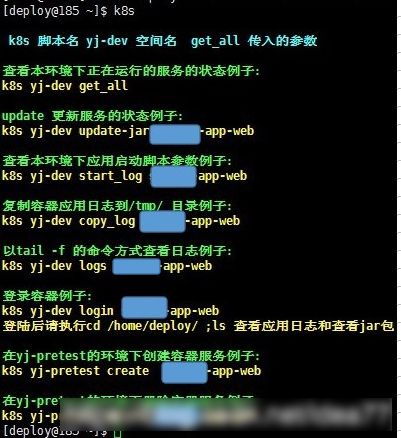
简化kubectl 命令,提供给研发团队使用。实际上这里功能和Jenkins以及Kibana上是重复的,但是必需考虑到所有团队成员的使用感受,有人喜欢命令行,有人喜欢界面,简单好用就够。我打个比方,比如看日志,有人可能喜欢用命令行tail -f看日志,用grep过滤等,有人喜欢用Kibana看,那怎么办?于是就有了两种方案,喜欢用图形界面用Jenkins或Kibana,想用命令可以用命令操作,满足你一切需求。统一集中通过指定的机器提供给开发、测试、运维、使用,方便调试、排障。通过统一的入口可以直接对容器进行服务创建、扩容、重启、登陆、查看日志、查看Java启动参数等,方便整个团队沟通。
在这里我们通过Kubernetes RBAC授权身份认证,生成不同的证书configkey,授于不同项目组不同的管理权限,不同的项目组只有自己项目的权限。权限做了细分,不同研发、测试团队互不干扰。
[deploy@185 app]# k8s dac-test get_all NAME READY STATUS RESTARTS AGE IP NODE accountant-3536198527-dtrc9 2/2 Running 0 21h 172.20.1.5 node3.k8s.novalocal analyzer-1843296997-vz9nc 2/2 Running 0 21h 172.20.87.15 node5.k8s.novalocal api-1260757537-gxrp2 2/2 Running 0 21h 172.20.71.6 k8s-monitor.novalocal calculator-1151720239-pr69x 2/2 Running 0 21h 172.20.1.12 node3.k8s.novalocal consul-0 1/1 Running 0 21h 172.20.87.3 node5.k8s.novalocal dispatcher-2608806384-kp433 2/2 Running 0 21h 172.20.4.6 lb1.k8s.novalocal geo-1318383076-c7th2 2/2 Running 0 5m 172.20.94.6 node6.k8s.novalocal greeter-79754259-s3bs2 2/2 Running 0 21h 172.20.19.5 jenkins-master.k8s.novalocal kafka-0 1/1 Running 0 21h 172.20.1.4 node3.k8s.novalocal mqtt-0 1/1 Running 0 21h 172.20.94.15 node6.k8s.novalocal mysql-0 2/2 Running 0 21h 172.20.47.7 elk-k8sdata.novalocal pusher-2834145138-lfs21 2/2 Running 0 21h 172.20.19.6 jenkins-master.k8s.novalocal recovery-261893050-70s3w 2/2 Running 0 21h 172.20.32.13 node4.k8s.novalocal redis-0 1/1 Running 0 21h 172.20.4.5 lb1.k8s.novalocal robot-1929938921-6lz6f 2/2 Running 0 21h 172.20.47.8 elk-k8sdata.novalocal scheduler-3437011440-rsnj6 2/2 Running 0 21h 172.20.5.10 db.k8s.novalocal valuation-2088176974-5kwbr 2/2 Running 0 21h 172.20.94.20 node6.k8s.novalocal zookeeper-0 1/1 Running 0 21h 172.20.4.4 lb1.k8s.novalocal
注意,如何操作用户自己有权限的空间,必需填写default-namespace.conf 注意,当gitlab master分支有合并的时候,目前我们ci自动会构建编译最新的jar版本,推送至nexus仓库,k8s容器里的jar包可以指定更新 k8s init-yml #初始化生成用户自己本人的yml文件 k8s get_all #查看用户自己本人空间下的所有运行的容器 k8s create_all #创建用户自己本人所有服务 k8s delall_app #删除本人空间下所有app服务,除基础服务mysql、 consul、 kafka、 redis、 zookeeper、mqtt 以外的所有服务 k8s apply api #修改了用户自己本人yml配置文件,应用配置生效 k8s create api #用户自己本人空间下创建一个api服务 k8s delete api #用户自己本人空间下删除一个api服务 k8s scale api 2 #用户自己本人空间下把api服务扩容成2个pod k8s login api #用户本人空间下登录api所在的docker容器 k8s logs api #用户自己本人空间用tail -f 命令的方式查看容器内/home/deploy/api/logs/api.log 的日志 k8s error-logs api #用户自己本人空间用tail -f 命令的方式查看容器内/home/deploy/api/logs/api.error.log 的日志 k8s clean api #如果编译出错,在用户自己本人空间用gradlew clean清理命令的方式清理编译 k8s push_jar #更新本人空间下所有容器的jar包版本,重启所有容器,默认拉取backend / push-envelope -git最终版本,该版本为合并编译成功后的最新版本号 k8s push_jar 20170927-1731 #选择指定的jar版本号20170927-1731 进行更新 ,重启所有容器 k8s reinit-mysql #重新更新所有容器jar版本后api无法启动,清空用户空间下的数据库,重新创建导入数据 批量操作 k8s scale api-geo 2 #在dev用户下把api和geo 扩容 k8s delete api-geo #在dev用户下删除api 和geo服务 k8s create api-geo #在dev用户下创建api和geo服务 所有人员通用命令,要操作某个用户的资源,必需先生成所需要的yml文件 但是必需指定第二个参数名dev test stage等。 k8s stage init-yml #初始化生成stage用户的yml文件 注意要操作stage用户的容器要先成配置文件 k8s test init-yml #初始化生成test空间的yml文件 k8s dev init-yml #初始化生成dev空间的yml文件 k8s dev get_all #查看dev用户空间下的所有运行的容器 k8s dev create_all #创建dev空间下所有服务 k8s dev delall_app #删除dev空间下的app服务,除基础服务mysql、 consul、 kafka、 redis、 zookeeper、mqtt 以外的所有服务 k8s dev apply api #修改了yml配置文件,应用配置生效 k8s dev create api #dev空间下创建一个api服务 k8s dev delete api #dev空间下删除一个api服务 k8s dev scale api 2 #dev空间下把api服务扩容成2个pod k8s dev login api #dev空间下登录api所在的docker容器 k8s dev logs api #dev空间用tail -f 命令的方式查看容器内/home/deploy/api/logs/api.log 的日志 k8s dev error-logs api #dev空间用tail -f 命令的方式查看容器内/home/deploy/api/logs/api.error.log 的日志 k8s dev push_jar #更新dev空间下所有容器的jar包版本,重启所有容器,默认拉取backend /-git最终版本,该版本为合并编译成功后的最新版本号 k8s dev push_jar 20170927-1731 #选择指定的jar版本号20170927-1731 进行更新 ,重启所有容器 k8s dev clean api #如果编译出错,dev用户空间用gradlew clean清理命令的方式清理编译 k8s dev reinit-mysql #重新更新所有容器jar版本后api无法启动,清空dev空间下的数据库,重新创建导入数据 批量操作 k8s dev scale api-geo 2 #在dev空间把api和geo 扩容 k8s dev delete api-geo #在dev空间删除api 和geo服务 k8s dev create api-geo #在dev空间下创建api和geo服务 管理员专用命令,注意管理员第二个参数一定要填 k8s dev create_rsync #创建dev空间的rsync配置 k8s dev create_passwd #创建dev空间的解压密码下发密钥 k8s dev create rbac #创建dev空间的集群授权认证 k8s dev delete rbac #删除dev空间的集群授权认证 k8s dev delete_all #删除dev空间下所有服务
Kubernetes集群规划和问题总结
1、集群资源规划request +limit+maxpods+eviction参数,需要计算好再配置,配置有问题可能导致资源利用不均衡,一部节点资源利用过高,一部节点资源利用过低。
2、Kubernetes Node节点一定要留有足够的磁盘空间,跟据Pod个数和image大小决定磁盘空间数。
3、JDK无法获取正确的CPU数,默认获取的是宿主机CPU,会致创建的线程数过多,系统崩溃,可以通过: https://github.com/obmarg/libsysconfcpus.git 解决。
if [ "x$CONTAINER_CORE_LIMIT" != "x" ]; then
LIBSYSCONFCPUS="$CONTAINER_CORE_LIMIT"
if [ ${LIBSYSCONFCPUS} -lt 2 ]; then
LIBSYSCONFCPUS=2
fi
export LIBSYSCONFCPUS
fi
export LD_PRELOAD="/usr/local/lib/libsysconfcpus.so:$LD_PRELOAD"
4、nfs-server一定要用async,充份利用缓存加快写入速度,注意内核版本bug。
5、应用产生的日志必需要设置轮转数和大小,防止过大日志撑暴宿主机磁盘。
6、发布版本越多,随着下载镜像版本越来越多,磁盘会撑爆,合理配置kubelet image gc参数,配置gc回收优化磁盘空间。
7、Docker CE以前的版本经常会出现Docker失控,使用过程中整个节点容器无法删除,无法创建,只能重启,对业务影响很大,建议全部更新到18-CE版本,和Kubernetes容性更好。
8、节点的亲和性和反亲和Affinity一定要提前规划好,为了达到高可用目的,多副本必需配置。
9、应用异常检测,跟据实际情况配置探针ReadinessProbe、LivenessProbe防止应用假死,Kubernetes提前剔除有问题的Pod容器。
Q&A
Q:使用NFS有存在性能瓶颈或单点故障的问题吗,如何解决,对于持久化要求高的Redis应该采用哪种存储?
A:具体看你的规模数量,测试、开发环境,单节点NFS毫无压力,数据是先写到缓存内存,速度很快,我文章中的说的内核注意bug,没必要做高可用,公有云有NAS服务,不必担心,自建机房可以用drbd Keepalived vip。
Q:为什么网络没有使用Traefik,Spring Cloud的相关组件是怎么部署的,是用yaml文件还是使用Helm方式?
A:考虑到Traefik性能没有nginx好,所以用nginx,ymal是自己写的模板生成的,没有用Helm。我们正在调研,Eureka可以单独定制多个yml互相注册。与外部服务通过打通网络直通,通过SVC对接。
Q:请问下所有环境都在一个集群,压测怎么办?
A:压测只是对应用产生压力,你可以把需要压测的应用调度到不同的节点NodeSelecto隔离运行。
Q:对于局域网微信回调是如何做,没有公网IP?
A:打通网络之后,设置WIFI指向DNS为Kubernetes DNS,Service直接互通。
Q:Eureka注册时服务IP用的什么?
A:Kubernetes集群内会用的podip去注册。
Q:有状态应用的场景,使用容器部署与传统部署有啥区别,容器部署是否存在一些坑?
A:有状态容器创建后,尽量少动,少迁移,遇到过卡住,容器无法迁移或删除,重要的MySQL之类的建议放外部运行。
以上内容根据2018年10月30日晚微信群分享内容整理。分享人 涂小刚,新浪爱问普惠科技容器平台负责人,负责Kubernetes容器平台的推广与建设 。DockOne每周都会组织定向的技术分享,欢迎感兴趣的同学加微信:liyingjiesd,进群参与,您有想听的话题或者想分享的话题都可以给我们留言。
正文到此结束
- 本文标签: consul 时间 目录 公网IP git 解析 探针 Logging 数据库 参数 tab id sql 管理 core tomcat Dockerfile zab 域名 update ACE tar value 编译 Service cat Uber node Elasticsearch UI Dashboard 需求 云 ECS iptables MongoDB web Quartz grep REST 认证 Master zookeeper IDE src 质量 bug 缓存 空间 java 生命 key 服务器 钉钉 压力 同步 remote 高可用 配置 Spring cloud 代码 mysql 主机 awk Kubernetes rsync 下载 find Eureka 测试 MQ 密钥 redis lib jenkins Kibana Proxy UDP spring 删除 DNS Docker Nginx HTTP服务器 进程 总结 端口 分布式 安装 Lua GitHub linux ask ip tag App wget 文章 nfs 组织 定制 IO centos 数据 client 自动化 ELK Pods TCP rmi http https Select root message 线程 开发 windows tail -f map mongo API 推广 SVN stream CTO zip python 科技 list 协议 cache 集群 build db 分布式系统 调试
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

