5分钟从零构建第一个 Flink 应用
在本文中,我们将从零开始,教您如何构建第一个 Flink 应用程序。
开发环境准备
Flink 可以运行在 Linux, Max OS X, 或者是 Windows 上。为了开发 Flink 应用程序,在本地机器上需要有 Java 8.x 和 maven 环境。
如果有 Java 8 环境,运行下面的命令会输出如下版本信息:
$ java-version javaversion "1.8.0_65" Java(TM)SE Runtime Environment (build1.8.0_65-b17) JavaHotSpot(TM) 64-BitServer VM (build25.65-b01,mixed mode)
如果有 maven 环境,运行下面的命令会输出如下版本信息:
$ mvn -version Apache Maven 3.5.4 (1edded0938998edf8bf061f1ceb3cfdeccf443fe; 2018-06-18T02:33:14+08:00) Maven home: /Users/wuchong/dev/maven Java version: 1.8.0_65, vendor: Oracle Corporation, runtime: /Library/Java/JavaVirtualMachines/jdk1.8.0_65.jdk/Contents/Home/jre Default locale: zh_CN, platform encoding: UTF-8 OS name: "mac os x", version: "10.13.6", arch: "x86_64", family: "mac"
另外我们推荐使用 ItelliJ IDEA (社区免费版已够用)作为 Flink 应用程序的开发 IDE。Eclipse 虽然也可以,但是 Eclipse 在 Scala 和 Java 混合型项目下会有些已知问题,所以不太推荐 Eclipse。下一章节,我们会介绍如何创建一个 Flink 工程并将其导入 ItelliJ IDEA。
创建 Maven 项目
我们将使用 Flink Maven Archetype 来创建我们的项目结构和一些初始的默认依赖。在你的工作目录下,运行如下命令来创建项目:
mvn archetype:generate / -DarchetypeGroupId=org.apache.flink / -DarchetypeArtifactId=flink-quickstart-java / -DarchetypeVersion=1.6.1 / -DgroupId=my-flink-project / -DartifactId=my-flink-project / -Dversion=0.1 / -Dpackage=myflink / -DinteractiveMode=false
你可以编辑上面的 groupId, artifactId, package 成你喜欢的路径。使用上面的参数,Maven 将自动为你创建如下所示的项目结构:
$ tree my-flink-project my-flink-project ├── pom.xml └── src └── main ├── java │ └── myflink │ ├── BatchJob.java │ └── StreamingJob.java └── resources └── log4j.properties
我们的 pom.xml 文件已经包含了所需的 Flink 依赖,并且在 src/main/java 下有几个示例程序框架。接下来我们将开始编写第一个 Flink 程序。
编写 Flink 程序
启动 IntelliJ IDEA,选择 “Import Project”(导入项目),选择 my-flink-project 根目录下的 pom.xml。根据引导,完成项目导入。
在 src/main/java/myflink 下创建 SocketWindowWordCount.java 文件:
package myflink;
public class SocketWindowWordCount{
public static void main(String[] args) throws Exception{
}
}
现在这程序还很基础,我们会一步步往里面填代码。注意下文中我们不会将 import 语句也写出来,因为 IDE 会自动将他们添加上去。在本节末尾,我会将完整的代码展示出来,如果你想跳过下面的步骤,可以直接将最后的完整代码粘到编辑器中。
Flink 程序的第一步是创建一个 StreamExecutionEnvironment 。这是一个入口类,可以用来设置参数和创建数据源以及提交任务。所以让我们把它添加到 main 函数中:
StreamExecutionEnvironment see = StreamExecutionEnvironment.getExecutionEnvironment();
下一步我们将创建一个从本地端口号 9000 的 socket 中读取数据的数据源:
DataStream<String> text = env.socketTextStream("localhost", 9000, "/n");
这创建了一个字符串类型的 DataStream 。 DataStream 是 Flink 中做流处理的核心 API,上面定义了非常多常见的操作(如,过滤、转换、聚合、窗口、关联等)。在本示例中,我们感兴趣的是每个单词在特定时间窗口中出现的次数,比如说5秒窗口。为此,我们首先要将字符串数据解析成单词和次数(使用 Tuple2<String, Integer> 表示),第一个字段是单词,第二个字段是次数,次数初始值都设置成了1。我们实现了一个 flatmap 来做解析的工作,因为一行数据中可能有多个单词。
DataStream<Tuple2<String, Integer>> wordCounts = text
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out){
for (String word : value.split("//s")) {
out.collect(Tuple2.of(word, 1));
}
}
});
接着我们将数据流按照单词字段(即0号索引字段)做分组,这里可以简单地使用 keyBy(int index) 方法,得到一个以单词为 key 的 Tuple2<String, Integer> 数据流。然后我们可以在流上指定想要的窗口,并根据窗口中的数据计算结果。在我们的例子中,我们想要每5秒聚合一次单词数,每个窗口都是从零开始统计的:。
DataStream<Tuple2<String, Integer>> windowCounts = wordCounts .keyBy(0) .timeWindow(Time.seconds(5)) .sum(1);
第二个调用的 .timeWindow() 指定我们想要5秒的翻滚窗口(Tumble)。第三个调用为每个key每个窗口指定了 sum 聚合函数,在我们的例子中是按照次数字段(即1号索引字段)相加。得到的结果数据流,将每5秒输出一次这5秒内每个单词出现的次数。
最后一件事就是将数据流打印到控制台,并开始执行:
windowCounts.print().setParallelism(1);
env.execute("Socket Window WordCount");
最后的 env.execute 调用是启动实际Flink作业所必需的。所有算子操作(例如创建源、聚合、打印)只是构建了内部算子操作的图形。只有在 execute() 被调用时才会在提交到集群上或本地计算机上执行。
下面是完整的代码,部分代码经过简化(代码在 GitHub 上也能访问到):
package myflink;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
public class SocketWindowWordCount{
public static void main(String[] args) throws Exception{
// 创建 execution environment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 通过连接 socket 获取输入数据,这里连接到本地9000端口,如果9000端口已被占用,请换一个端口
DataStream<String> text = env.socketTextStream("localhost", 9000, "/n");
// 解析数据,按 word 分组,开窗,聚合
DataStream<Tuple2<String, Integer>> windowCounts = text
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out){
for (String word : value.split("//s")) {
out.collect(Tuple2.of(word, 1));
}
}
})
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1);
// 将结果打印到控制台,注意这里使用的是单线程打印,而非多线程
windowCounts.print().setParallelism(1);
env.execute("Socket Window WordCount");
}
}
运行程序
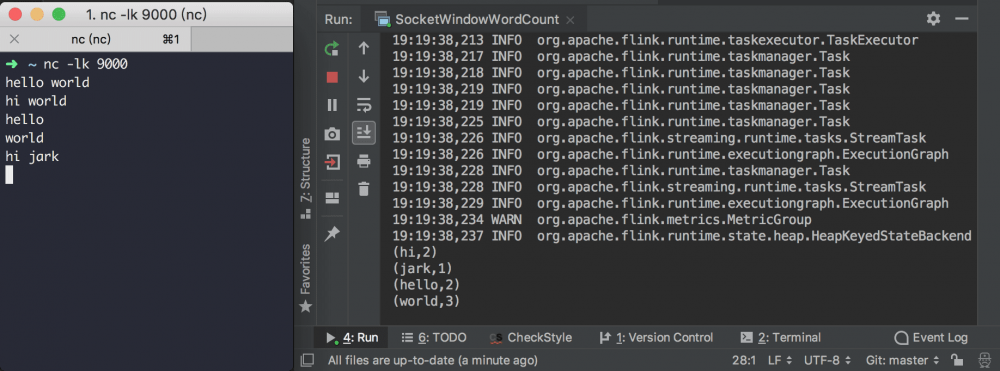
要运行示例程序,首先我们在终端启动 netcat 获得输入流:
nc -lk 9000
如果是 Windows 平台,可以通过 https://nmap.org/ncat/ 安装 ncat 然后运行:
ncat -lk 9000
然后直接运行 SocketWindowWordCount 的 main 方法。
只需要在 netcat 控制台输入单词,就能在 SocketWindowWordCount 的输出控制台看到每个单词的词频统计。如果想看到大于1的计数,请在5秒内反复键入相同的单词。
Cheers! :tada:
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

